




PgSQL技术内幕 - 优化器如何估算行数
PgSQL优化器根据统计信息估算执行计划路径的代价,从而选择出最优的执行计划。而这些统计信息来自pg_statistic,当然这个系统表是由ANALYZE或者VACUUM进行样本采集而来。关于该系统表的介绍详见:
在理解优化器估算行数原理前,先了解几个概念。
1、MCV
MCV即Most Common Values也就是表中出现频率最高的一批值,以KV形式存储在pg_statistic系统表中。将这些值从直方图中剔除可以减少极端值造成的估算误差。
2、等频直方图
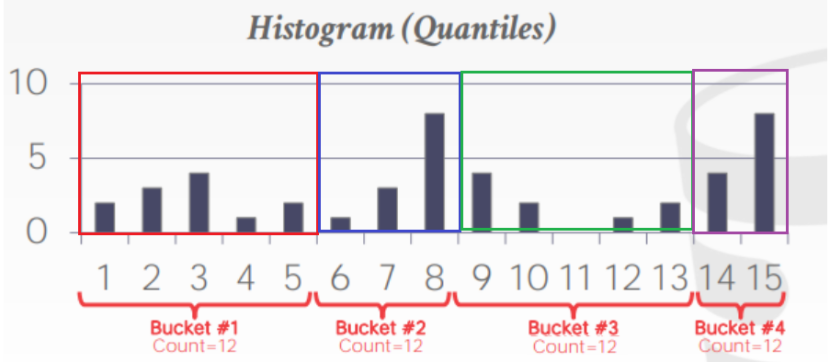
直方图高度相同,每个桶宽度不同。如下图,每个桶Bucket里数值总个数相同,即为12。那么由于黑桶个数不同,导致有些Bucket跨度比较大。比如估算5的频率时,若在第一个Bucket频率占比为1/5,而第一个Bucket在整个直方图中占比为1/4,那么5的频率就是1/20。
3、打印执行计划时估算的行数
以select * from t1 where id2 =10;为例:

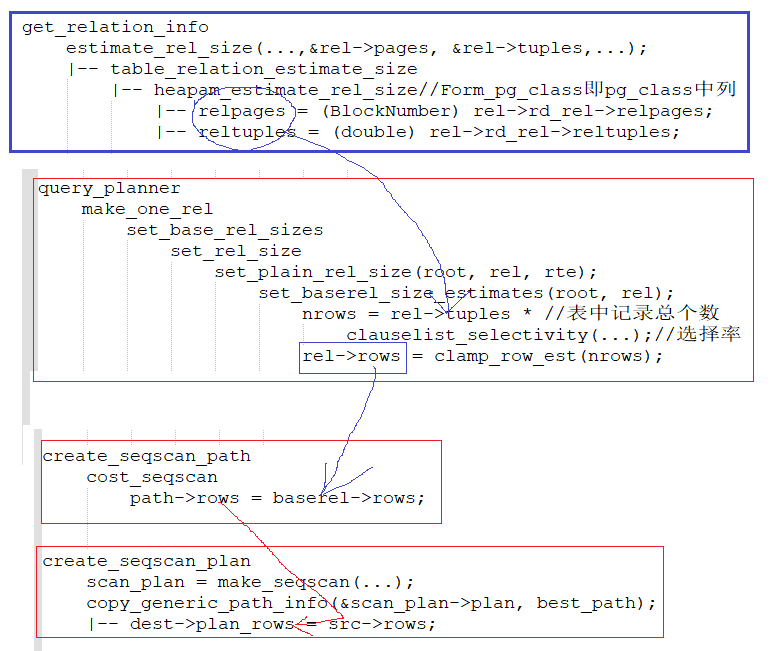
也就是执行计划节点Plan的plan_rows值。追本溯源,查看plan_rows值怎么计算得到的即可。从pg_class系统表获取对应表对应的行数rel->tuples,在query_planner调用到set_baserel_size_estimates函数时,将采样统计出表的行数rel->tuples * 选择率即得到估算行数。该估算行数在生成执行计划路径时放到路径path->rows中,进一步在创建SeqScan计划节点时由path->rows传递给Plan的rows,由此估算出了行数:
4、等值选择率
进一步,需要知道选择率如何计算。我们以=100为例:选择率函数包括join选择率评估函数都在selfuncs.c文件中,选择率调用函数堆栈:
clauselist_selectivity->clauselist_selectivity_simple->clause_selectivity->restriction_selectivity
restriction_selectivity中调用各个操作符对应的计算选择函数,等值过滤查询的选择率函数为eqsel:主要根据pg_statistic系统表的第一个卡槽的统计信息MCV:
eqsel_internal
var_eq_const
|-- if (HeapTupleIsValid(vardata->statsTuple)){
//pg_statistic中的信息
Form_pg_statistic stats;
stats = (Form_pg_statistic) GETSTRUCT(vardata->statsTuple);
nullfrac = stats->stanullfrac;//null值占比
}
if (vardata->isunique && vardata->rel && vardata->rel->tuples >= 1.0){
//该列唯一约束
selec = 1.0 / vardata->rel->tuples;
}else if (HeapTupleIsValid(vardata->statsTuple) &&
statistic_proc_security_check(vardata,(opfuncoid = get_opcode(operator)))){
//有统计信息
if (get_attstatsslot(&sslot, vardata->statsTuple,STATISTIC_KIND_MCV, InvalidOid,
ATTSTATSSLOT_VALUES | ATTSTATSSLOT_NUMBERS)){
//MCV卡槽取出最常见值统计信息sslot
fmgr_info(opfuncoid, &eqproc);
for (i = 0; i < sslot.nvalues; i++){//从最常见值数组中查找
match = DatumGetBool(FunctionCall2Coll...,constval,sslot.values[i]));
if (match)
break;//落在MCV中break
}
}else{
i = 0;
}
if (match){//落在MCV,选择率为MCV占比
selec = sslot.numbers[i];
}else{//没落在MCV中
for (i = 0; i < sslot.nnumbers; i++)
sumcommon += sslot.numbers[i];//mcv的总占比
selec = 1.0 - sumcommon - nullfrac;//去掉mcv占比和null占比
//(不同值个数 - 高频值个数)
otherdistinct = get_variable_numdistinct(vardata, &isdefault) - sslot.nnumbers;
if (otherdistinct > 1)
selec /= otherdistinct;//(低频值总占比)/低频值总数=每个低频值的占比
}
}else{//没有analyze统计信息,猜一个选择率
selec = 1.0 / get_variable_numdistinct(vardata, &isdefault);
}总结:
1)若100落在MCV中,则MCV的占比即为其选择率
2)若100没有落在MCV中,则选择率为:
(1- sumcommon - nullfrac)/(otherdistinct )即:低频值总占比/低频值总数
5、<=的选择率
等值过滤条件选择率计算没有用到直方图,<=的场景会用到等频直方图。<=的选择率计算函数为scalarlesel->scalarineqsel_wrapper->scalarineqsel:
scalarlesel->scalarineqsel_wrapper->scalarineqsel
stats = (Form_pg_statistic) GETSTRUCT(vardata->statsTuple);
//mcv中的选择率,计算同上
mcv_selec = mcv_selectivity(vardata, &opproc, constval, true,&sumcommon);
hist_selec = ineq_histogram_selectivity(root, ...);//直方图的选择率
//合并mcv和直方图选择率
selec = 1.0 - stats->stanullfrac - sumcommon;//非高频即直方图的占比
selec *= hist_selec;//直方图中满足条件的选择率
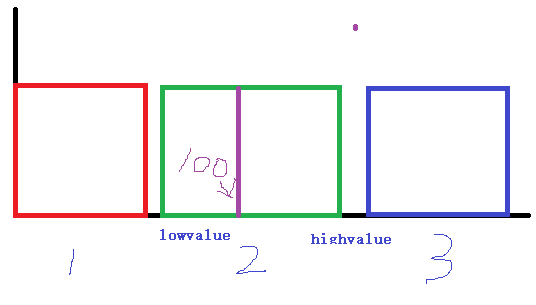
selec += mcv_selec;//加上mcv的选择率重点关注直方图中如何计算ineq_histogram_selectivity,它使用二分查找法在直方图中进行查找,看100落在哪个桶上,如下图,比如100落在第2(标记序号为i)个桶上,那么满足条件的桶的个数n=(i-1)+(100-lowvalue)/(highvalue - lowvalue)。n/总桶数:(sslot.nvalues - 1)即为直方图中满足条件的行数占比。直方图的占比*非常见数的占比即为直方图中求得的满足条件的记录选择率。
当然,若有多个条件,则多个条件的选择率进行与或等(加/减)操作就可以得到多个条件下的选择率。
参考
https://www.postgresql.org/docs/current/planner-stats.html
https://postgrespro.com/blog/pgsql/5969296
https://postgrespro.com/list/thread-id/2676971
https://www.cnblogs.com/mlmz/p/15973106.html
