




这个小案例已经过去好几个月了,在这篇文章里面我试图来重新回忆并梳理一下当时碰到的这个dblink性能语句的调优过程,方法挺简单但是当时还是绕了一些弯子。还是老规矩,各位天上的大能请自动飞过,这篇文章没啥太大的技术含量,也没有长篇大论的叙述dblink的优化方式,我自己也才学了个一知半解的。
dblink的性能优化,我觉得大体上来说就两个思路,把数据送过去处理,然后拿结果回来,或者把远端数据先拿过来然后在本地处理,其它的诸如视情况在远端建立物化视图,提前准备好数远端数据结果,或者根据链接条件,如果在远端表上过滤性非常好的话,可以在远端表建索引什么的,我认为最终都还是会落回这两个方向上来,关键点就是你在哪儿处理,就在那儿看看它的执行计划是啥,然后在进一步针对性的调优。
一般情况下(并非绝对的),带dblink的语句都是把远端数据直接拉回本地数据库,然后再与本地表做关联,如果要控制关联这个操作的位置,方法就是我们都知道的driving_site这个提示。其它更加高深的绝招,我这里也没有,如果哪位大佬有相关资料的,欢迎共享,不胜感激。
有一天下午,我们一套MIS系统库的同事来找我反馈,他们一条涉及dblink的查询语句跑的非常慢,每次都要跑两个多钟头,是在令人头疼。我问了下,这个SQL语句返回的数据量大概在几万条到10W条之间,按理说应该没这么夸张才对。
SQL的部分内容大致如下,省略了部分内容:
INSERT INTO /*+ APPEND */ MID_SF_XXXXXX_ALL
(RCPTNO,
POLICYNO,
...
CREATEDATE,
UPDATEDATE
)
SELECT /*+ parallel(8) */
PD.CUSTSEQ AS RCPTNO,
...
PD.AMOUNT AS premium,
SYSDATE CREATEDATE,
SYSDATE UPDATEDATE
FROM mm_usablemirror_td@BPSFLINK p
LEFT OUTER JOIN mm_policy_td@BPSFLINK PD ON P.usableno = PD.SEQPOLICY
LEFT OUTER JOIN mm_conversionrate_tc@BPSFLINK RATE ON rate.currencycode2='CNY'
AND p.currencycode = RATE.currencycode1 and TRUNC(V_ETL_DATE_TO_DATE, 'dd') between rate.startdate and rate.enddate
WHERE p.mirrorid in (select mirrorid
from mm_mirror_td@BPSFLINK m
where m.mirrortype='2' and m.mirrordate = TRUNC(V_ETL_DATE_TO_DATE, 'dd'))
AND p.businestype='1';
各位火眼金睛的大佬们,应该第一时间就能看出这个SQL语句的一个特点,那就是它取数据的所有表,全部都是远端数据库里面的,本地库一张表也没有。另外,这些个远端表我看了一下,有两个大家伙总计35个G,两个比较小的表,所以SELECT部分还开了并发查询。那么这个SQL的优化办法,就是设法让SELECT部分全部在远端数据库执行,然后直接把结果返回来就行。由于当时数据库里面这条SQL语句的执行计划信息已经被age out出内存了,我也懒得去看AWR里面的计划,因为我感觉有时候AWR里面保留的计划不一定靠谱。于是我先尝试直接执行一下里面的SELECT部分,得到的执行计划如下:
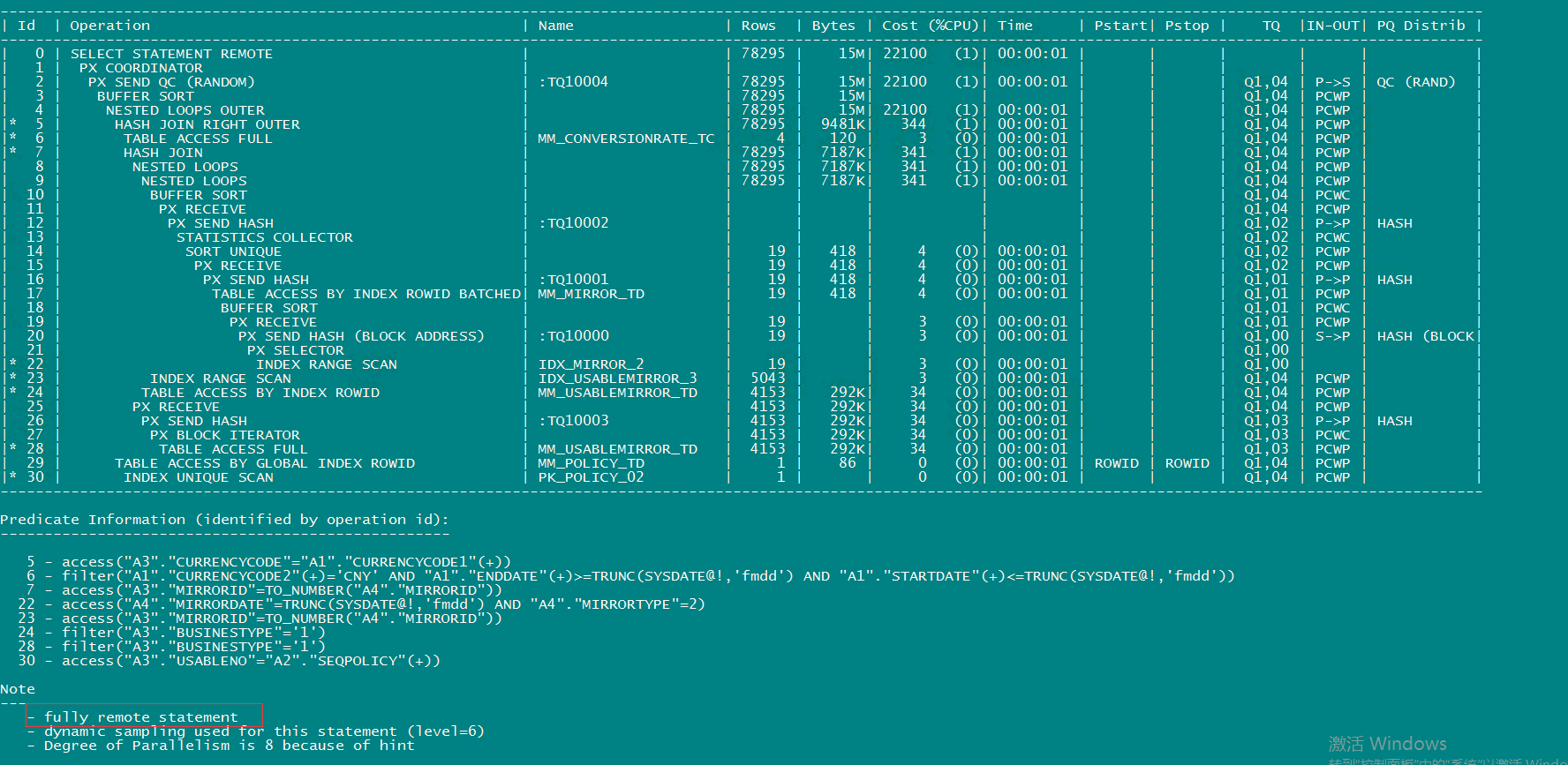
查询花了大概19秒的时间,返回大概9万多条数据,而且可以看到后面的NOTE提示“- fully remote statement”,说明这个SQL的执行全部都是在远端完成,然后把结果传回到本地,和我预计的是一样的,整个执行计划是没有太大问题的。就算INSERT速度慢,但区区9万条数据,咋可能会花费掉2个半小时?
我琢磨了一阵子,想到一种可能,该不会在实际调用的过程中,走的计划不是这个样子,它会不会是把这几张表先传递回本地数据库,然后再做的处理,dblink和insert的结合,产生了啥爱情故事不成,于是我explain plan for了一把整个INISERT SELECT 语句,得到的结果如下:
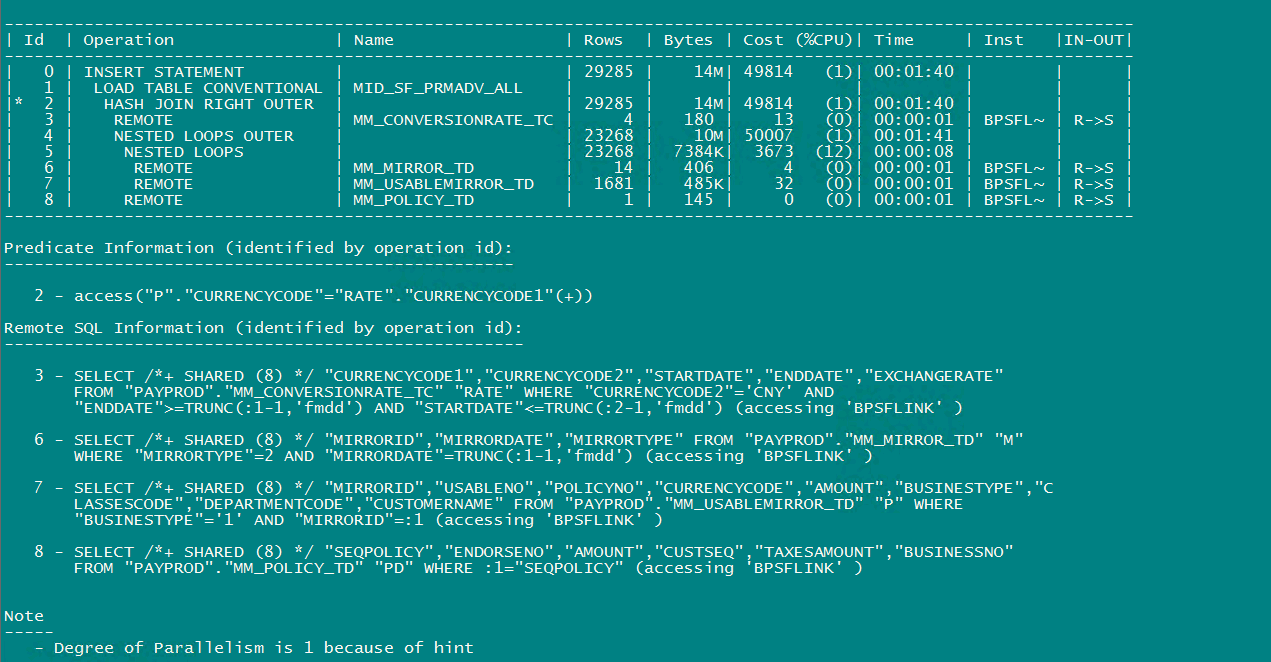
数据库把里面的远程表,每一张都单独进行远程过滤,然后传回本地数据库,最后再做的加工。然后我又返回去抓了这个SQL的AWR历史执行计划,发现和这个一模一样,简直了…
那个时候的我,还不知道DML和DBLINK的结合,会有一些不太友好的化学反应,于是就立马想到用driving_site来进行优化,在SELECT的地方,加了最大那张表的driving_site:
SELECT /*+ parallel(8) driving_site(p) */
我试图用这种方式,来控制dblink的执行主体为远程数据库,但是我发现,这个地方无论我怎么添加这个hint提示,执行计划依然执着的一成不变,对于INSERT来说,这个dblink就像个二五仔似得,脑后勺长反骨啊。
在抓瞎之下,我到MOS上面去搜索,找到了这篇文章:
Limitations of DRIVING_SITE Hint For DMLS and DDLS (Doc ID 825677.1)
这篇文章的意思就是说,driving_site这个Hint提示只是用优化查询语句的,它对DML和DDL语句无效。
DRIVING_SITE hint is not working for DML or DDL. Remember DRIVING_SITE hint is for query optimization and not intended for DML or DDL, as a distributed DML statement must execute on the database where the DML target resides.
坦白说我还是第一次听说这个知识点,但是不知道到底是我英文不好还是怎么的,我感觉这篇文章里面举的例子,反而把事情说的不清不楚的,根据我的一些测试,如果添加driving_site之后,后面的remote sql部分会变成类似(accessing !)这样的形式,比如这样:
select/*+ driving_site(t2) */ * from test t, test2@dbl_tst t2 where t.id1=t2.id2;
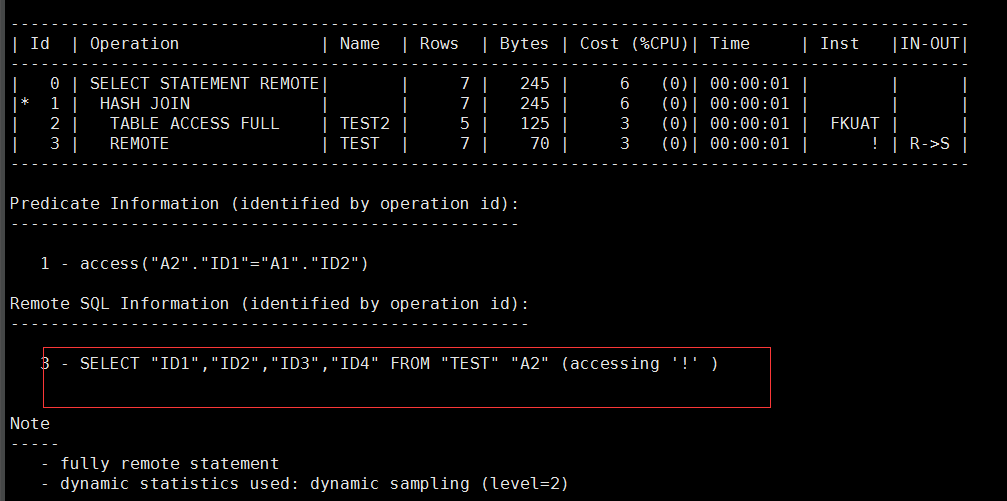
既然driving_site对DML和DDL语句无效,那么似乎这个SQL的处理办法就只有一个了,那就是在远程数据库去创建一个物化视图,专门用于处理这个数据,后面本地数据库直接访问那个物化视图就可以了,这当然是一个好办法。我也是建议他们这么处理的,但是他们给我说,“麻烦!有没有其他办法?”“那就试试用游标的方式,把SQL拆分成两部分?”“还是麻烦…”
唉,我也觉得麻烦,我就取个数而已,这样视图那样JOB的,搞这么复杂。我这人吧,有时候就不太相信一些东西,MOS里面说driving_site对DML和DDL都无效,DML这个我目前已经证实了,但是DDL嘛,试试看吧。
于是我尝试将INSERT部分,先用create table as 的方式进行替代:
CREATE table dblinktest AS
SELECT /*+ parallel(8) */
PD.CUSTSEQ AS RCPTNO, --收付号
P.POLICYNO AS POLICYNO, --保单号
...
SYSDATE CREATEDATE, --创建日期
SYSDATE UPDATEDATE --修改日期
FROM payprod.mm_usablemirror_td@BPSFLINK p
LEFT OUTER JOIN payprod.mm_policy_td@BPSFLINK PD ON P.usableno = PD.SEQPOLICY
LEFT OUTER JOIN payprod.mm_conversionrate_tc@BPSFLINK RATE ON rate.currencycode2='CNY'
AND p.currencycode = RATE.currencycode1 and TRUNC(SYSDATE-1, 'dd') between rate.startdate and rate.enddate
WHERE p.mirrorid in (select mirrorid from payprod.mm_mirror_td@BPSFLINK m where m.mirrortype='2' and m.mirrordate = TRUNC(SYSDATE-1, 'dd'))
AND p.businestype='1';
注意看,我这里没有添加任何hint,看看结果如何:

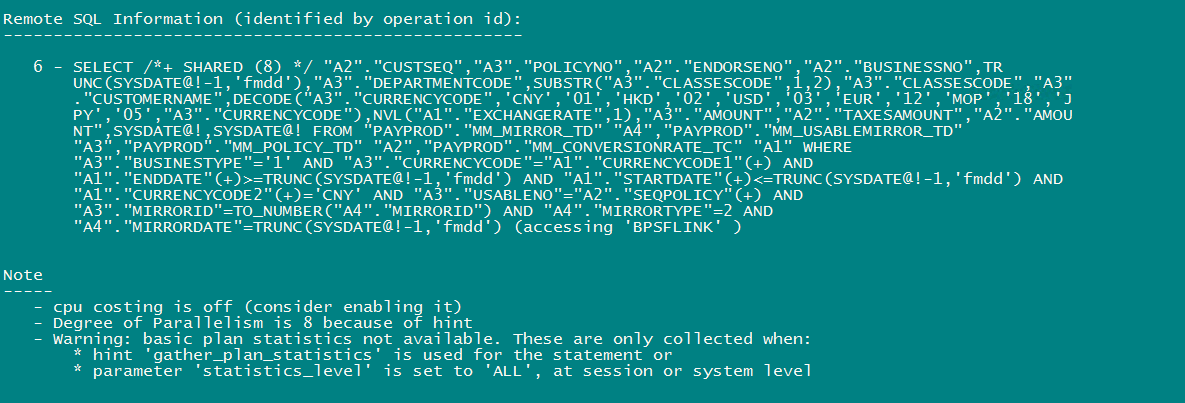
没想到效果居然不错,不到30秒就跑完了。注意看后面remote sql部分,这一次数据库是把整个处理逻辑当成了一整条SQL语句,在远端数据库执行完了之后,再通过dblink传回的本地数据库,这个就跟我们一开始的单独执行SELECT语句,实际上是一样的效果。
当然,这个地方我也尝试过添加driving_site,但是结果还是一样的,跟单独执行SELECT的效果一样。
这似乎说明在这种纯远程SQL的模式(不和本地表关联,纯dblink取数)下,INSERT的语句,会将每一个表单独进行处理,然后传回本地最终做加工,但是CREATE TABLE AS的方式,却可以将整个加工逻辑,全部整合成一条SQL语句,在远端执行出了结果,然后再传回本地库,再进行表的创建。其中的原理我还没理解透,各位如果碰到这种类似的情况,或许可以试试这个办法。但是如果和本地表有关联的话,这个方式就不一定适用了,比如:
create table test4 as
select /*+ driving_site(t2) */ t1.id1,t2.name2
from test t1
left join test2@dbl_tst t2
on t1.id1=t2.id2
where t1.id1=2;
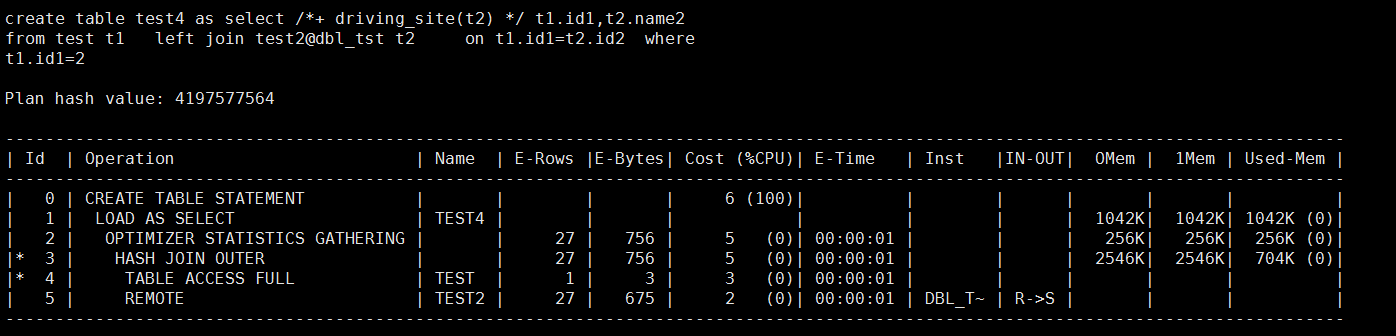

这也证明了前面文档里面说的,driving_site这个东西对DDL也无效。
同时,也并非是说所有的这种SQL都会完全如此,我后来在11g和19c里面分别都做了个简但的测试,发现结果都是如下形式:
insert into test3(id3, name3) select t1.id1,t2.name2 from test1@dbl_tst t1, test2@dbl_tst t2 where t1.id1=t2.id2;
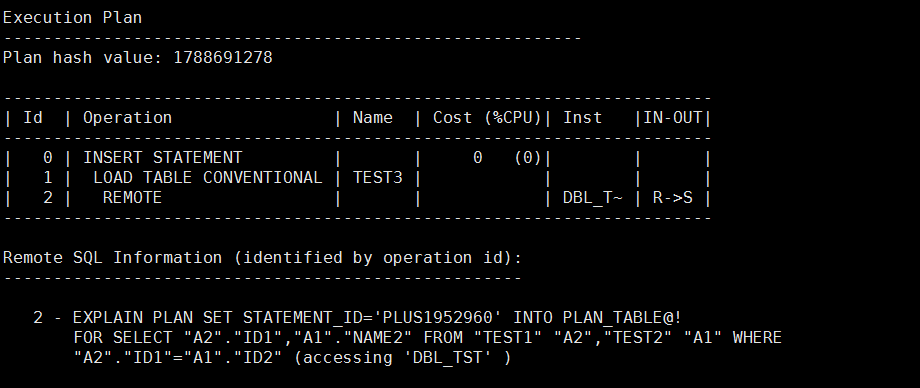
这次数据库并没有将表单独一个一个的拉扯回本地,然后在处理。当然,测试的SQL非常简单,不排除因为本次我碰到的SQL稍微复杂一点的缘故,并且这其中可能还有数据库的一些其它因素在影响,见招拆招吧。
那么碰到这种不受控的DML/DDL+dblink的情况该如何办呢,除了物化视图之外,其实只要懂点儿PL/SQL编程的人第一个能想到的就是用游标来先保存查询的结果,最后在进行游标遍历INSERT嘛(前面也提了一嘴,就是做SQL拆分),注意设置好批量提交的逻辑,这样的好处就是,既能在SELECT部分用driving_site来进行调优控制,同时批量插入的方法还可以减少Undo的争用,当然,副作用就是PL/SQL程序与数据库之间会产生更多的出入页的交换而造成CPU的其它开销,巨量结果集的话这个影响就比较大,如何取舍,就以实际结果来看吧。
事情到了这里,我就将这个办法反馈给他们了,剩下的事儿他们自己处理,做DBA而已干嘛把自己整的那么累嘛。
当然后面他们又碰到了另外一个问题,那就是在他们的存储过程当中,没有权限执行建表语句,又是一番折腾之后,告诉他们做如下处理,在创建Package的时候(注意不是package body),添加“Authid Current_User”关键字:
CREATE OR REPLACE PACKAGE PKG_PRMADV_ALL Authid Current_User AS
之后,他们的存过在这一部分,顺利的在不到5分钟内跑完。完美!(我知道你们还有进一步的优化方法,在其它地方可以再把时间压缩一点儿,但我觉得莫要那么固执的要求自己,有时候适当的得过且过会让自己更轻松一点儿。)
好了,这个SQL的dblink问题,就算是被我误打误撞的给拾掇了一顿,MD这个二五仔!
求学的路上,枯燥而漫长,每一小步的前进都算是一种收获吧。
