




一,简介
https://www.modb.pro/db/176706
二,pgpool PCP命令集
pcp_detach_node - 将给定节点从 Pgpool-II 分离。与Pgpool-II的外泄连接被迫断开。
pcp_attach_node - 将给定的节点连接到 Pgpool-II。
pcp_stop_pgpool - 终止Pgpool-II进程
pcp_reload_config - 重新加载 pgpool-II 配置文件
pcp_recovery_node - 将给定的后端节点与恢复连接
三,pgpool脚本样本
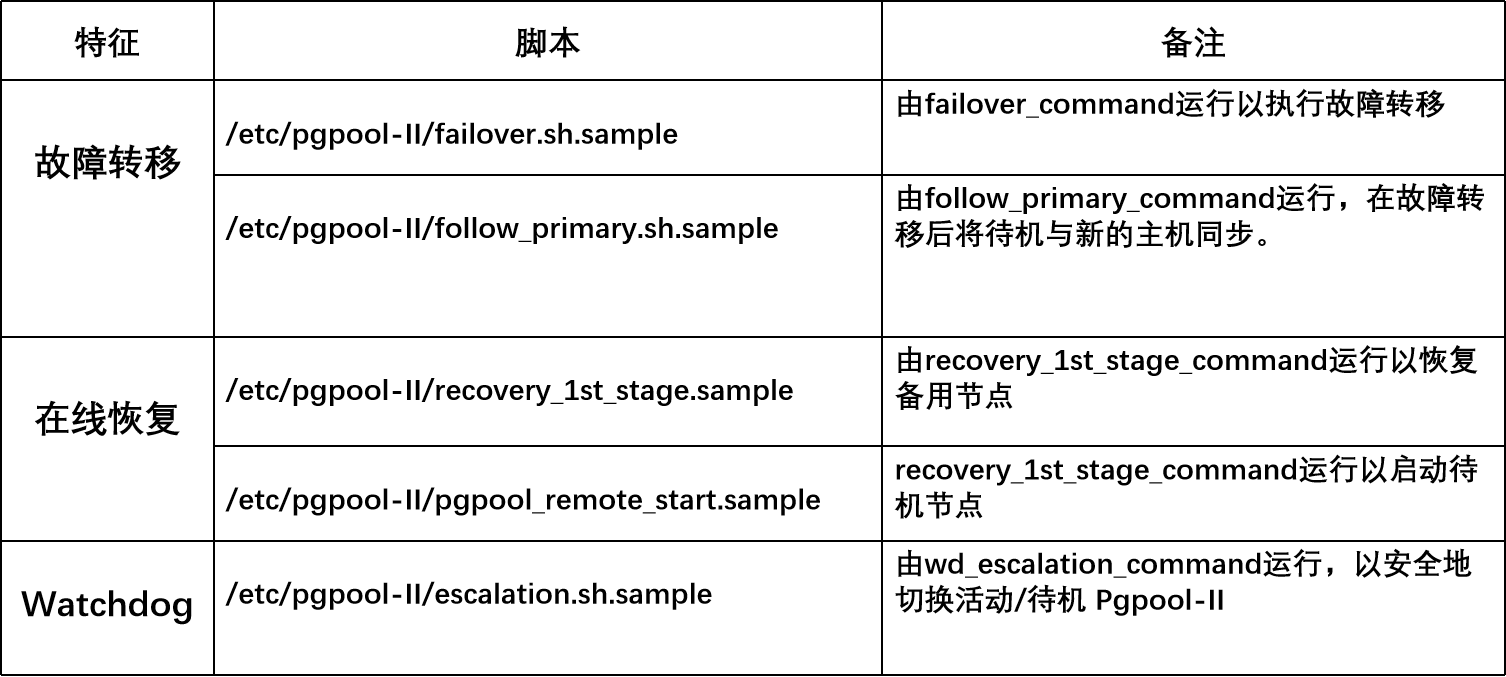
故障转移脚本介绍
failover_command触发条件:
1,health check(网络问题或者pg无法工作)
2,若没有连接链接到pgpool,
则pg关闭不会触发
脚本逻辑
1,如果是从库down
那么在主库上drop replication slot
2,如果是主库down 那么提升从库为新主
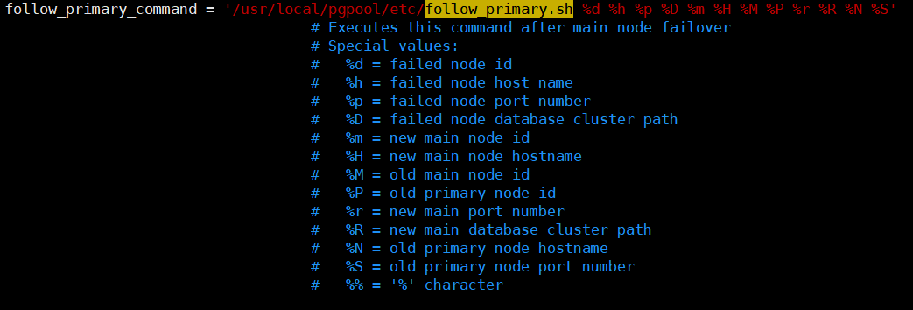
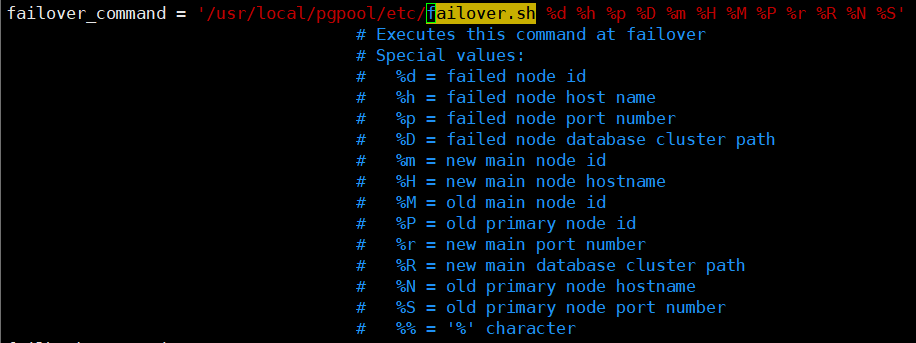
follow_primary_command触发条件
1,在主节点故障转移后要运行的用户命令
2,pcp_promote_node命令
(仅在流复制模式下有效)
脚本逻辑
同步从库到新主
1,pg_rewind
2,pg_basebackup(pcp_recovery_node)
四,pgpool部署

端口规划:

在100/101/102上关闭防火墙和selinux:
[root@allserver ~]# systemctl disable firewalld
[root@allserver ~]# systemctl stop firewalld
[root@allserver ~]# setenforce 0
[root@allserver ~]# sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/confi
安装/配置 pgpool:
[root@allserver src]# tar -zxf pgpool-II-4.2.4.tar.gz
[root@allserver pgpool-II-4.2.4]# ./configure --prefix=/usr/local/pgpool
[root@allserver pgpool-II-4.2.4]# make && make install
[root@allserver pgpool-II-4.2.4]# cd /usr/local/pgpool/etc
[root@allserver etc]# cp pcp.conf.sample pcp.conf;cp pgpool.conf.sample-stream pgpool.conf;
cp follow_primary.sh.sample follow_primary.sh; chmod +x failover.sh;cp failover.sh.sample failover.sh; chmod +x failover.sh;
cp escalation.sh.sample escalation.sh;chmod +x escalation.sh;
chown postgres:postgres /usr/local/pgpool/etc/{failover.sh,follow_primary.sh,escalation.sh};
cp recovery_1st_stage.sample recovery_1st_stage;chmod +x recovery_1st_stage;
mv recovery_1st_stage /data/pg_data/;cp pgpool_remote_start.sample pgpool_remote_start;
chmod +x pgpool_remote_start;mv pgpool_remote_start /data/pg_data/;chown postgres:
postgres /data/pg_data -R;cp pool_hba.conf.sample pool_hba.conf;
echo "export PATH=\$PATH:/usr/local/pgpool/bin/">> /etc/profile; . /etc/profile
设置密码
[root@allserver etc]# pg_md5 -p -m -u postgres pool_passwd
password: (输入密码123qwert)
[root@allserver etc]# pg_md5 -p -m -u pgpool pool_passwd
password: (输入密码123qwert)
[root@allserver etc]# cat /usr/local/pgpool/etc/pool_passwd
postgres:md569d08236c8e9fc9e0fd97e9d74afe7de
pgpool:md560cd0c52f2f43bb1eb5f18c70ae85a59
修改:
[postgres@allserver ~]$ vim /usr/local/pgpool/etc/failover.sh
PGHOME=/usr/local/pgsql
/data/pg_data/recovery_1st_stage脚本内容:
[postgres@allserver pgpool_logs]$ vim /data/pg_data/recovery_1st_stage
PGHOME=/usr/local/pgsql/
ARCHIVEDIR=/data/pg_archive/
REPLUSER=replic
在53行左右的pg_basebackup的后面加上-R参数
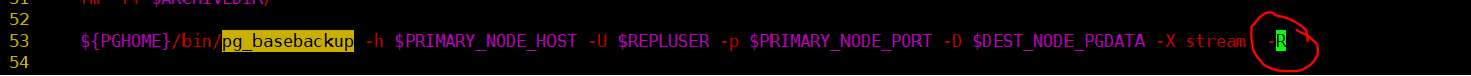
以及第56行左右的.pgpass文件路径由/var/lib/pgsql/.pgpass更改为 ~/.pgpass

修改/data/pg_data/pgpool_remote_start里面的内容
PGHOME=/usr/local/pgsql/
修改/usr/local/pgpool/etc/follow_primary.sh里面内容
#!/bin/bash
# This script is run after failover_command to synchronize the Standby with the new Primary.
# First try pg_rewind. If pg_rewind failed, use pg_basebackup.
set -o xtrace
# Special values:
# 1) %d = node id
# 2) %h = hostname
# 3) %p = port number
# 4) %D = node database cluster path
# 5) %m = new primary node id
# 6) %H = new primary node hostname
# 7) %M = old main node id
# 8) %P = old primary node id
# 9) %r = new primary port number
# 10) %R = new primary database cluster path
# 11) %N = old primary node hostname
# 12) %S = old primary node port number
# 13) %% = '%' character
NODE_ID="$1"
NODE_HOST="$2"
NODE_PORT="$3"
NODE_PGDATA="$4"
NEW_PRIMARY_NODE_ID="$5"
NEW_PRIMARY_NODE_HOST="$6"
OLD_MAIN_NODE_ID="$7"
OLD_PRIMARY_NODE_ID="$8"
NEW_PRIMARY_NODE_PORT="$9"
NEW_PRIMARY_NODE_PGDATA="${10}"
FAILED_NODE_ID="$1"
FAILED_NODE_HOST="$2"
FAILED_NODE_PORT="$3"
FAILED_NODE_DATA="$4"
NEW_MASTER_NODE_ID="$5"
NEW_MASTER_NODE_HOST="$6"
OLD_MASTER_NODE_ID="$7"
OLD_PRIMARY_NODE_ID="$8"
NEW_MASTER_NODE_PORT="$9"
NEW_MASTER_NODE_PGDATA="${10}"
OLD_PRIMARY_NODE_HOST="${11}"
OLD_PRIMARY_NODE_PORT="${12}"
PGHOME=/usr/local/pgsql/
ARCHIVEDIR=/data/pg_archive
REPLUSER=replic
PCP_USER=pgpool
PGPOOL_PATH=/usr/local/pgpool/bin/
PCP_PORT=9898
REPL_SLOT_NAME=${NODE_HOST//[-.]/_}
#超级用户
PGUSER_SUPER=postgres
#超级用户pgdb密码
PGUSER_SUPER_PWD='123qwert'
#dbname
PGUSER_SUPER_DBNAME=postgres
#复制用户
PGUSER_REPLI=replic
#复制用户密码
PGUSER_REPLI_PWD='123qwert'
echo follow_primary.sh: start: Standby node ${FAILED_NODE_ID}
## Get PostgreSQL major version
PGVERSION=`${PGHOME}/bin/initdb -V | awk '{print $3}' | sed 's/\..*//' | sed 's/\([0-9]*\)[a-zA-Z].*/\1/'`
if [ $PGVERSION -ge 12 ]; then
RECOVERYCONF=${FAILED_NODE_DATA}/myrecovery.conf
else
RECOVERYCONF=${FAILED_NODE_DATA}/recovery.conf
fi
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null $PGUSER_SUPER@${NEW_PRIMARY_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
echo follow_main.sh: passwrodless SSH to $PGUSER_SUPER@${NEW_PRIMARY_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## Check the status of Standby
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \
$PGUSER_SUPER@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ${PGHOME}/bin/pg_ctl -w -D ${FAILED_NODE_DATA} status
## If Standby is running, synchronize it with the new Primary.
if [ $? -eq 0 ]; then
echo follow_primary.sh: pg_rewind for node ${FAILED_NODE_ID}
# Create replication slot "${REPL_SLOT_NAME}"
echo 'this is create_physical_replication_slot-->'${REPL_SLOT_NAME}
${PGHOME}/bin/psql -h ${NEW_PRIMARY_NODE_HOST} -p ${NEW_PRIMARY_NODE_PORT} \
-c "SELECT pg_create_physical_replication_slot('${REPL_SLOT_NAME}');" >/dev/null 2>&1
if [ $? -ne 0 ]; then
echo follow_primary.sh: create replication slot \"${REPL_SLOT_NAME}\" failed. You may need to create replication slot manually.
fi
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null $PGUSER_SUPER@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
set -o errexit
${PGHOME}/bin/pg_ctl -w -m f -D ${FAILED_NODE_DATA} stop
${PGHOME}/bin/pg_rewind -R -D ${FAILED_NODE_DATA} --source-server=\"user=$PGUSER_SUPER host=${NEW_PRIMARY_NODE_HOST} port=${NEW_PRIMARY_NODE_PORT}\"
rm -rf ${FAILED_NODE_DATA}/pg_replslot/*
cat > ${RECOVERYCONF} << EOT
primary_conninfo = 'host=${NEW_PRIMARY_NODE_HOST} port=${NEW_PRIMARY_NODE_PORT} user=${REPLUSER} application_name=${FAILED_NODE_HOST} user=$PGUSER_REPLI password=$PGUSER_REPLI_PWD'
recovery_target_timeline = 'latest'
restore_command = 'scp ${NEW_PRIMARY_NODE_HOST}:${ARCHIVEDIR}/%f %p'
primary_slot_name = '${REPL_SLOT_NAME}'
EOT
if [ ${PGVERSION} -ge 12 ]; then
sed -i -e \"\\\$ainclude_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'\" \
-e \"/^include_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'/d\" ${FAILED_NODE_DATA}/postgresql.auto.conf
touch ${FAILED_NODE_DATA}/standby.signal
else
echo \"standby_mode = 'on'\" >> ${RECOVERYCONF}
fi
"
sleep 2
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null $PGUSER_SUPER@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
${PGHOME}/bin/pg_ctl -l /dev/null -w -D ${FAILED_NODE_DATA} restart -mf
"
if [ $? -ne 0 ]; then
echo 'pg_rewind is failed ,will try to use pcp_recovery_node'
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGPOOL_PATH}/pcp_recovery_node -h NEW_MASTER_NODE_HOST -v -p $PGPOOL_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
sleep 2
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGPOOL_PATH}/pcp_recovery_node -h FAILED_NODE_HOST -v -p $PGPOOL_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
if [ $? -ne 0 ]; then
echo 'the old primary pg_rewind and pcp_recovery_node is failed!'
fi
fi
# If start Standby successfully, attach this node
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null $PGUSER_SUPER@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool $PGHOME/bin/pg_ctl -w -D /data/pg_data status
if [ $? -eq 0 ]; then
# Run pcp_attact_node to attach Standby node to Pgpool-II.
echo "pgpool_follow_master pcp_attach_node 111 id-->"${FAILED_NODE_ID}
${PGPOOL_PATH}/pcp_attach_node -w -h $NEW_MASTER_NODE_HOST -U $PCP_USER -p ${PCP_PORT} -n ${FAILED_NODE_ID}
if [ $? -ne 0 ]; then
ssh -i ~/.ssh/id_rsa_pgpool -T $NEW_MASTER_NODE_HOST "${PGPOOL_PATH}/pcp_attach_node -d -w -h $NEW_MASTER_NODE_HOST -p $PCP_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
fi
if [ $? -ne 0 ]; then
ssh -i ~/.ssh/id_rsa_pgpool -T $NEW_MASTER_NODE_HOST "${PGPOOL_PATH}/pcp_attach_node -d -w -h $FAILED_NODE_HOST -p $PCP_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
fi
if [ $? -ne 0 ]; then
echo ERROR: follow_primary.sh: end: pcp_attach_node failed
exit 1
fi
# If start Standby failed, drop replication slot "${REPL_SLOT_NAME}"
else
${PGHOME}/bin/psql -h ${NEW_PRIMARY_NODE_HOST} -p ${NEW_PRIMARY_NODE_PORT} \
-c "SELECT pg_drop_replication_slot('${REPL_SLOT_NAME}');" >/dev/null 2>&1
if [ $? -ne 0 ]; then
echo ERROR: follow_primary.sh: drop replication slot \"${REPL_SLOT_NAME}\" failed. You may need to drop replication slot manually.
fi
echo ERROR: follow_primary.sh: end: follow primary command failed
exit 1
fi
else
echo "follow_primary.sh: failed_nod_id=${FAILED_NODE_ID} is not running. try to fix it"
###对失败的数据节点尝试操作####################### start
echo '对失败的数据节点尝试操作--start'
echo "pgpool_follow_master stop pgdb "
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGHOME}/bin/pg_ctl stop -m fast -D $FAILED_NODE_DATA"
echo "failover.sh: failed_node_id=$FAILED_NODE_ID failed_node_host=${FAILED_NODE_HOST} stop The action has been completed!"
# echo "pgpool_follow_master pg_rewind pgdb "
# ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGHOME}/bin/pg_rewind --target-pgdata=$FAILED_NODE_DATA --source-server='host=$NEW_MASTER_NODE_HOST port=$NEW_MASTER_NODE_PORT user=$PGUSER_SUPER password=$PGUSER_SUPER_PWD dbname=$PGUSER_SUPER_DBNAME' -P -R"
echo "pgpool_follow_master touch the FAILED_NODE_ID:${FAILED_NODE_ID} pgdb conf file ${PGRECOVERYCONF}"
# Create replication slot "${REPL_SLOT_NAME}"
echo 'this is start create replication'${REPL_SLOT_NAME}
${PGHOME}/bin/psql -h ${NEW_PRIMARY_NODE_HOST} -p ${NEW_PRIMARY_NODE_PORT} \
-c "SELECT pg_create_physical_replication_slot('${REPL_SLOT_NAME}');" >/dev/null 2>&1
if [ $? -ne 0 ]; then
echo follow_primary.sh: create replication slot \"${REPL_SLOT_NAME}\" failed. You may need to create replication slot manually.
fi
echo "pgpool_follow_master pg_rewind pgdb "
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null $PGUSER_SUPER@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
set -o errexit
${PGHOME}/bin/pg_rewind -R -D ${FAILED_NODE_DATA} --source-server=\"user=$PGUSER_SUPER host=${NEW_PRIMARY_NODE_HOST} port=${NEW_PRIMARY_NODE_PORT}\"
rm -rf ${FAILED_NODE_DATA}/pg_replslot/*
cat > ${RECOVERYCONF} << EOT
primary_conninfo = 'host=${NEW_PRIMARY_NODE_HOST} port=${NEW_PRIMARY_NODE_PORT} user=${REPLUSER} application_name=${FAILED_NODE_DATA} user=$PGUSER_REPLI password=$PGUSER_REPLI_PWD'
recovery_target_timeline = 'latest'
restore_command = 'scp ${NEW_PRIMARY_NODE_HOST}:${ARCHIVEDIR}/%f %p'
primary_slot_name = '${REPL_SLOT_NAME}'
EOT
if [ ${PGVERSION} -ge 12 ]; then
sed -i -e \"\\\$ainclude_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'\" \
-e \"/^include_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'/d\" ${FAILED_NODE_DATA}/postgresql.auto.conf
touch ${FAILED_NODE_DATA}/standby.signal
else
echo \"standby_mode = 'on'\" >> ${RECOVERYCONF}
fi
"
sleep 2
echo "pgpool_follow_master start pgdb "
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGHOME}/bin/pg_ctl start -D $FAILED_NODE_DATA 2>/dev/null 1>/dev/null < /dev/null &"
##################################### 如果pg_rewind失败进行recovery操作 -- start
if [ $? -ne 0 ]; then
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGPOOL_PATH}/pcp_recovery_node -h NEW_MASTER_NODE_HOST -v -p $PGPOOL_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
sleep 2
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGPOOL_PATH}/pcp_recovery_node -h FAILED_NODE_HOST -v -p $PGPOOL_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
if [ $? -ne 0 ]; then
echo 'the old primary pg_rewind and pcp_recovery_node is failed!'
fi
fi
##################################### 如果pg_rewind失败进行recovery操作 -- end
sleep 2
echo "pgpool_follow_master pcp_attach_node 222 id->"${FAILED_NODE_ID}
${PGPOOL_PATH}/pcp_attach_node -w -h $NEW_MASTER_NODE_HOST -U $PCP_USER -p ${PCP_PORT} -n ${FAILED_NODE_ID}
sleep 2
ssh -i ~/.ssh/id_rsa_pgpool -T $NEW_MASTER_NODE_HOST "${PGPOOL_PATH}/pcp_attach_node -d -w -h $NEW_MASTER_NODE_HOST -p $PCP_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
sleep 2
ssh -i ~/.ssh/id_rsa_pgpool -T $FAILED_NODE_HOST "${PGPOOL_PATH}/pcp_attach_node -d -w -h $FAILED_NODE_HOST -p $PCP_PORT -U $PGUSER_SUPER -n $FAILED_NODE_ID "
echo "pgpool_follow_master exit 0 "
echo '对失败的数据节点尝试操作--start'
###对失败的数据节点尝试操作####################### end
exit 0
fi
echo follow_primary.sh: end: follow primary command is completed successfully
exit 0
修改 $VIP/24为$VIP/20 掩码;并且修改vip;以及DEVICE配置为机器自己的网卡
[root@allserver etc]# vim escalation.sh
set -o xtrace
PGPOOLS=(server1 server2 server3)
VIP=192.168.254.99
DEVICE=ens33
for pgpool in "${PGPOOLS[@]}"; do
[ "$HOSTNAME" = "$pgpool" ] && continue
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$pgpool -i ~/.ssh/id_rsa_pgpool "
/usr/bin/sudo /sbin/ip addr del $VIP/20 dev $DEVICE
"
done
exit 0
如果某一个网卡名称不一样,需要另外处理:
[postgres@server1 ~]$ vim /usr/local/pgpool/etc/escalation.sh
#!/bin/bash
# This script is run by wd_escalation_command to bring down the virtual IP on other pgpool nodes
# before bringing up the virtual IP on the new active pgpool node.
set -o xtrace
PGPOOLS=(server1 server2 server3)
VIP=192.168.254.99
DEVICE=ens33
DEVICE2=eth0
for pgpool in "${PGPOOLS[@]}"; do
[ "$HOSTNAME" = "$pgpool" ] && continue
if [[ $pgpool != 'server2' ]]
then
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$pgpool -i ~/.ssh/id_rsa_pgpool "
/usr/bin/sudo /sbin/ip addr del $VIP/20 dev $DEVICE
"
else
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$pgpool -i ~/.ssh/id_rsa_pgpool "
/usr/bin/sudo /sbin/ip addr del $VIP/20 dev $DEVICE2
"
fi
done
exit 0
配置postgres用户的sudo权限:
[root@allserver etc]# cat /etc/sudoers |grep postgres
postgres ALL=(ALL) NOPASSWD:ALL
配置目录:
[root@allserver etc]# mkdir /runpg;mkdir /runpg/pgpool_log/;mkdir /runpg/pgpool ;mkdir /runpg/postgres ; chown postgres:postgres /runpg -R
#enable_pool_hba = on
[all servers]# vi /usr/local/pgpool/etc/pool_hba.conf
# 官方文档为 scram-sha-256,改为md5
host all pgpool 0.0.0.0/0 md5
host all postgres 0.0.0.0/0 md5
修改pgpool.conf相关配置
[root@localhost etc]# vim pgpool.conf
# [CONNECTIONS]
listen_addresses = '*'
port = 9999
socket_dir = '/runpg/postgresql'
pcp_socket_dir = '/runpg/postgres'
## - Backend Connection Settings -
backend_hostname0 = 'server1'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/data/pg_data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_application_name0 = 'server1'
backend_hostname1 = 'server2'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/data/pg_data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'server2'
backend_hostname2 = 'server3'
backend_port2 = 5432
backend_weight2 = 1
backend_data_directory2 = '/data/pg_data'
backend_flag2 = 'ALLOW_TO_FAILOVER'
backend_application_name2 = 'server3'
## - Authentication -
enable_pool_hba = on
pool_passwd = 'pool_passwd'
# [LOGS]
logging_collector = on
log_directory = '/data/pgpool_log'
log_filename = 'pgpool-%d.log'
log_file_mode = 0600
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 100MB
# [FILE LOCATIONS]
pid_file_name = '/runpg/pgpool/pgpool.pid'
## 此目录用来存放 pgpool_status 文件,此文件保存集群状态(刷新有问题时会造成show pool_status不正确)
logdir = '/tmp'
# [Streaming REPLICATION MODE]
sr_check_user = 'pgpool'
sr_check_password = '123qwert'
follow_primary_command = '/usr/local/pgpool/etc/follow_primary.sh %d %h %p %D %m %H %M %P %r %R'
# [HEALTH CHECK GLOBAL PARAMETERS]
health_check_period = 5
health_check_timeout = 20
health_check_user = 'pgpool'
## 为健康检查时查找 pool_passwd
health_check_password = '123qwert'
health_check_max_retries = 3
# [FAILOVER AND FAILBACK]
failover_command = '/usr/local/pgpool/etc/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S'
# [ONLINE RECOVERY]
recovery_user = 'postgres'
recovery_password = '123qwert'
recovery_1st_stage_command = 'recovery_1st_stage'
# [WATCHDOG]
use_watchdog = on
hostname0 = 'server1'
wd_port0 = 9000
pgpool_port0 = 9999
hostname1 = 'server2'
wd_port1 = 9000
pgpool_port1 = 9999
hostname2 = 'server3'
wd_port2 = 9000
pgpool_port2 = 9999
wd_ipc_socket_dir = '/runpg/postgresql'
## - Virtual IP control Setting -
delegate_IP = '192.168.254.99'
## - Behaivor on escalation Setting -
wd_escalation_command=''
或者
wd_escalation_command = '/usr/local/pgpool/etc/escalation.sh'
## - Lifecheck Setting -
wd_lifecheck_method = 'heartbeat'
### -- heartbeat mode --
heartbeat_hostname0 = 'server1'
heartbeat_port0 = 9694
heartbeat_device0 = ''
heartbeat_hostname1 = 'server2'
heartbeat_port1 = 9694
heartbeat_device1 = ''
heartbeat_hostname2 = 'server3'
heartbeat_port2 = 9694
heartbeat_device2 = ''
在100/101/102上面安装PG:
[root@localhost src]# tar -zxf postgresql-13.4.tar.gz
[root@localhost src]# cd postgresql-13.4/
[root@localhost src]# ./configure --prefix=/usr/local/pgsql
[root@localhost src]# make world && make install-world
[root@localhost src]# groupadd postgres && useradd -g postgres postgres
[root@localhost src]# passwd postgres
[root@localhost src]# mkdir -p /data/pg_data && mkdir -p /data/pg_archive && mkdir -p /data/pg_log&& mkdir -p /data/pgpool_logs
[root@localhost src]# chown -R postgres:postgres /data
在100/101/102上环境设置:
/root/.bash_profile和/home/postgres/.bash_profile配置
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export PGPORT=5432
export PGDATA=/data/pg_data
export PGHOME=/usr/local/pgsql
export LD_LIBRARY_PATH=$PGHOME/lib:/lib64:/usr/lib64:/usr/local/lib64:/lib:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH
export PATH=$PGHOME/bin:$PATH:.
export MANPATH=$PGHOME/share/man:$MANPATH
export PGUSER=postgres
export PGDATABASE=postgres
alias rm='rm -i'
alias ll='ls -lh'
export LANG="zh_CN.UTF8"
安装pgpool-recovery
[root@allserver etc]# cd /usr/local/src/pgpool-II-4.2.4/src/sql/pgpool-recovery/
[root@allserver pgpool-recovery]# make && make install
在100上初始化数据库:
[postgres@server1 ~]$ initdb -D /data/pg_data -E UTF-8 --locale=C -U postgres -W
100数据库配置文件postgresql.conf:
listen_addresses = '*'
archive_mode = on
archive_command = 'test ! -f /data/pg_archive/%f && cp %p /data/pg_archive/%f '
max_wal_senders = 10
max_replication_slots = 10
wal_level = replica
hot_standby = on
wal_log_hints = on
进入数据库:
postgres=# CREATE user pgpool password '123qwert';
postgres=# CREATE user replic password '123qwert';
postgres=# GRANT pg_monitor TO pgpool;
postgres=# \c template1
template1=# CREATE EXTENSION pgpool_recovery;
配置认证文件pg_hba.conf 添加:
host all all 192.168.254.1/24 **粗体** md5
host replication all 192.168.254.1/24 md5
在101/102上面建立基础备份并启动:
[postgres@server2/3 ~]$ pg_basebackup -h 192.168.254.100 -Ureplic -R -P --verbose -c fast -D /data/pg_data/ -F p -C --slot='slot101'
(在102上就是--slot='slot102')
[postgres@server2/3 ~]$ pg_ctl -D /data/pg_data/ start
在100上查看主从复制信息:
postgres=# select pid,usesysid,usename,client_addr,backend_start,state,flush_lsn,replay_lsn,write_lsn,write_lag,flush_lag,sync_state from pg_stat_replication ;

在100/101/102上设置host:
echo "192.168.254.100 server1" >> /etc/hosts
echo "192.168.254.101 server2" >> /etc/hosts
echo "192.168.254.102 server3" >> /etc/hosts
分别修改 hostname
[server1]# hostnamectl set-hostname server1
[server2]# hostnamectl set-hostname server2
[server3]# hostnamectl set-hostname server3
查看是否修改成功:
[root@localhost postgresql-13.4]# uname -a
Linux server1 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
配置ssh互信(分别在root和postgres用户下面进行配置):
[root@allserver ~]# mkdir ~/.ssh; cd ~/.ssh
[root@allserver .ssh]# ssh-keygen -t rsa -f id_rsa_pgpool
[root@allserver .ssh]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server1
[root@allserver .ssh]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server2
[root@allserver .ssh]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server3
[root@allserver .ssh]# su - postgres
[postgres@allserver ~]$ cd ~/.ssh/
[postgres@allserver .ssh]$ ssh-keygen -t rsa -f id_rsa_pgpool
[postgres@allserver .ssh]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server1
[postgres@allserver .ssh]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server2
[postgres@allserver .ssh]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server3
测试看是否免密登录:
ssh postgres@serverNo -i ~/.ssh/id_rsa_pgpool
在100/101/102上面的PG安装目录下面创建.pgpass文件:
[postgres@allserver ~]$ su - postgres
[postgres@allserver ~]$ vim ~/.pgpass
server1:5432:replication:replic:123qwert
server2:5432:replication:replic:123qwert
server3:5432:replication:replic:123qwert
server1:5432:postgres:postgres:123qwert
server2:5432:postgres:postgres:123qwert
server3:5432:postgres:postgres:123qwert
[postgres@allserver ~]$ chmod 0600 ~/.pgpass
从 Pgpool-II 4.2 中,现在所有主机的所有配置参数都相同。如果启用了监视器功能,以消除对哪个主机是哪个主机的干扰,则需要pgpool_node_id文件。需要创建一个pgpool_node_id文件,并指定pgpool(看门狗)节点编号(例如0,1,2…)来识别pgpool(看门狗)主机。
[root@server1 etc]# echo "0" >> /usr/local/pgpool/etc/pgpool_node_id
[root@server2 etc]# echo "1" >> /usr/local/pgpool/etc/pgpool_node_id
[root@server3 etc]# echo "2" >> /usr/local/pgpool/etc/pgpool_node_id
为follow_primary.sh中的PCP_USER=pgpool配置免密登录
[root@allserver etc]#
echo 'pgpool:'`pg_md5 123qwert` >>/usr/local/pgpool/etc/pcp.conf
echo 'postgres:'`pg_md5 123qwert` >>/usr/local/pgpool/etc/pcp.conf
[root@allserver etc]# su - postgres
[postgres@allserver ~]$
echo 'localhost:9898:pgpool:123qwert' >> ~/.pcppass;
echo '192.168.254.99:9898:pgpool:123qwert' >> ~/.pcppass;
echo 'server1:9898:pgpool:123qwert' >> ~/.pcppass;
echo 'server2:9898:pgpool:123qwert' >> ~/.pcppass;
echo 'server3:9898:pgpool:123qwert' >> ~/.pcppass;
[postgres@allserver ~]$ chmod 600 ~/.pcppass
#启动pgpool(先后分别在server 1、2、3上启动)
[postgres@allserver ~]$ pgpool -D -d -n &
主从模式
可以用两种方式进行实现
1,手动使用pg_basebackup来操作
2,可以使用pcp_recovery_node来进行添加
2.1,
[server1]# pcp_recovery_node -h 192.168.254.99 -p 9898 -U pgpool -n 1
2.2,
[server1]# pcp_recovery_node -h 192.168.254.99 -p 9898 -U pgpool -n 2

添加成功之后,会自动的启动从库,无需再手动启动
集群管理
pgpool 集群
查看集群配置信息
pcp_pool_status -h 192.168.254.99 -p 9898 -U pgpool -v
查看集群节点详情
#-h 表示集群IP,-p 表示PCP管道端口(默认是9898),-U 表示 PCP管道用户,-v表示查看详细内容
pcp_watchdog_info -h 192.168.254.99 -p 9898 -U pgpool -v -w
查看节点数量
pcp_node_count -h 192.168.254.99 -p 9898 -U pgpool -w
查看指定节点信息
pcp_node_info -h 192.168.254.99 -p 9898 -U pgpool -n 0 -v -w
增加一个集群节点
#-n 表示节点序号(从0开始)
pcp_attach_node -h 192.168.254.99 -p 9898 -U pgpool -n 0 -v -w
脱离一个集群节点
pcp_detach_node -h 192.168.254.99 -p 9898 -U pgpool -n 0 -v -w
提升一个备用节点为活动节点
pcp_promote_node -h 192.168.254.99 -p 9898 -U pgpool -n 0 -v -w
恢复一个离线节点为集群节点
pcp_recovery_node -h 192.168.254.99 -p 9898 -U pgpool -n 0 -v -w
PostgresSQL集群
连接集群
[all servers]$ psql -h 192.168.254.99 -p 9999
查看集群状态
[all servers]$ psql -h 192.168.254.99 -p 9999 -U postgres postgres -c "show pool_nodes"

show pool_status;查看相关参数配置
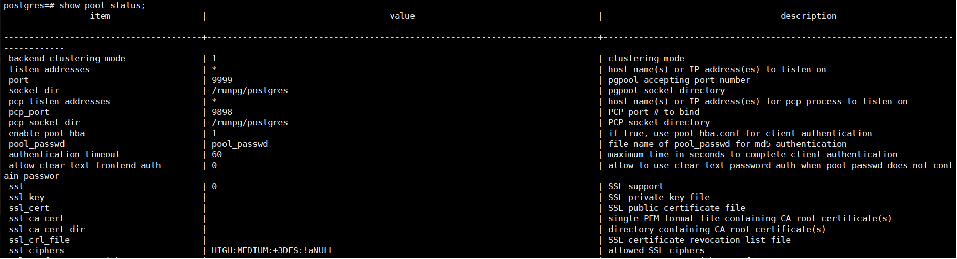
五,PGpool-II高可用测试
高可用测试:
目前状态:
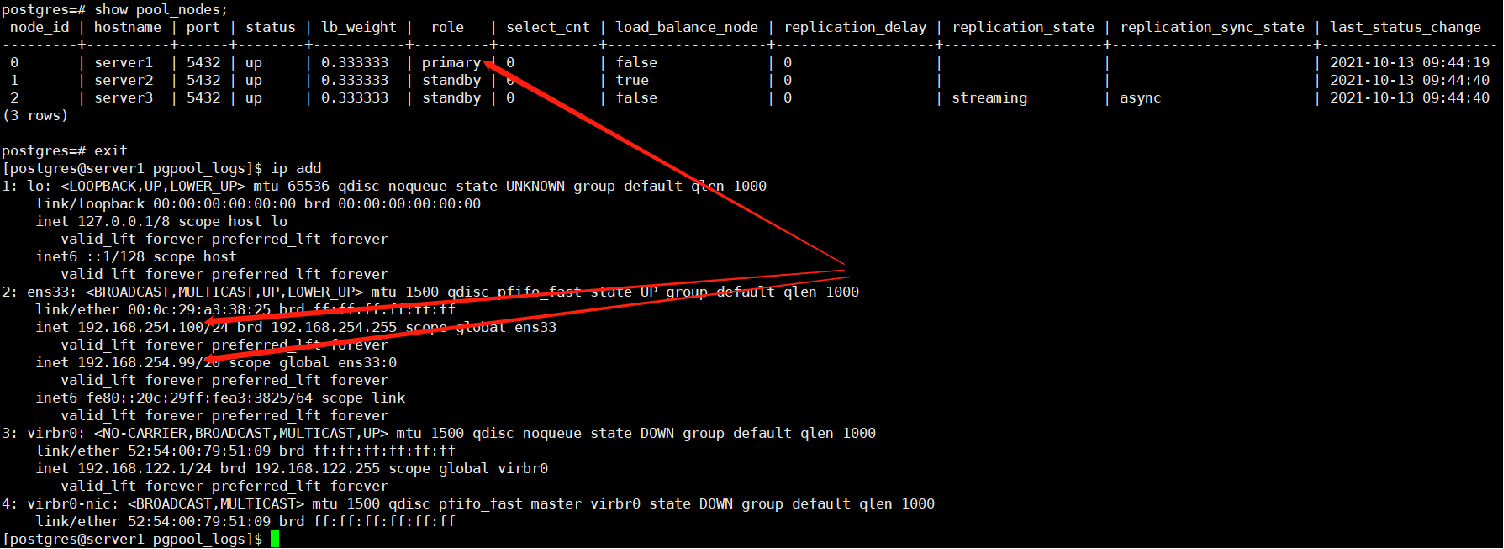
Vip位于100上。
1,停掉100上面的pg数据库
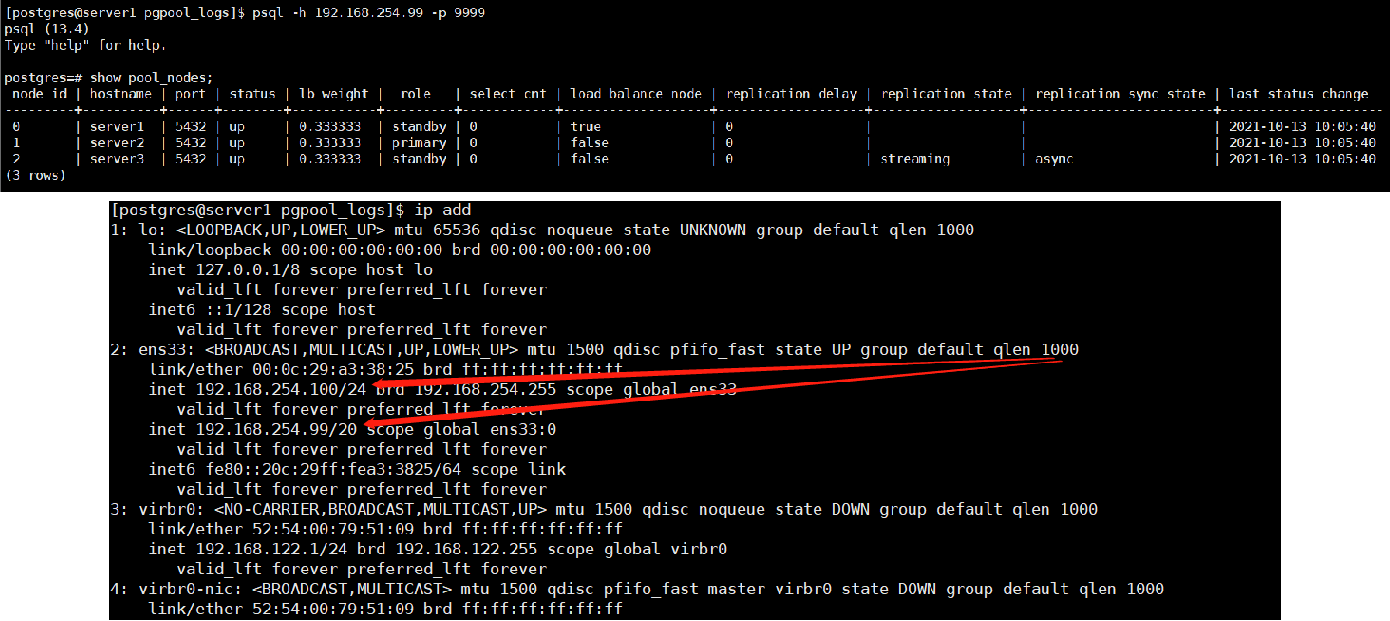
结果:主库原来的server2上面的从库被提升为主库,原来的sever1的主库将为从库,server3的从库被重新指向新的主库
2, 再次切换:
停掉101上面的主库。
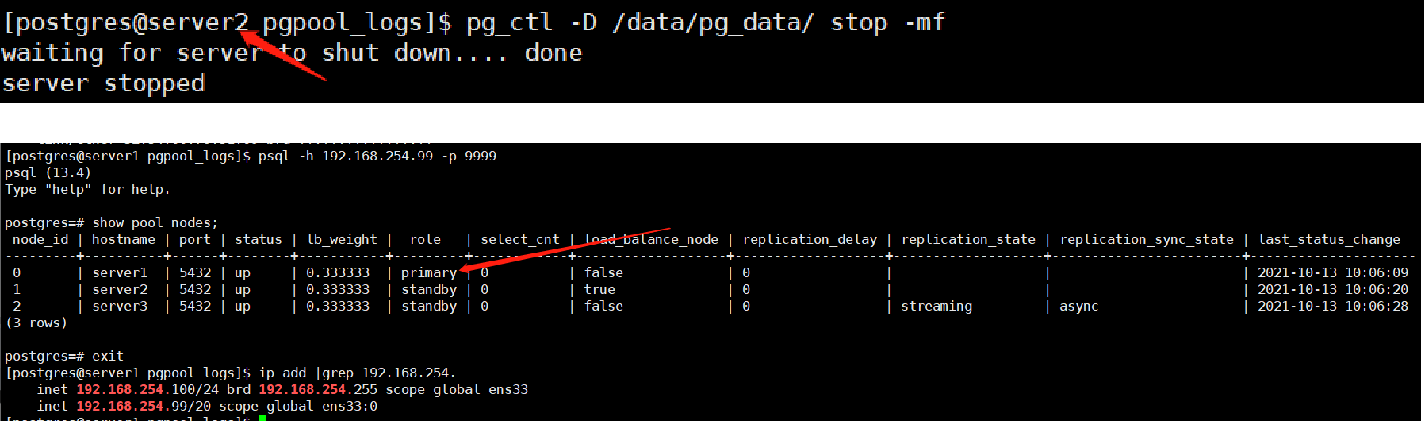
结果:主库原来的server1上面的从库被提升为主库,原来的sever2的主库将为从库,server3的从库被重新指向新的主库
3,关闭100虚拟机
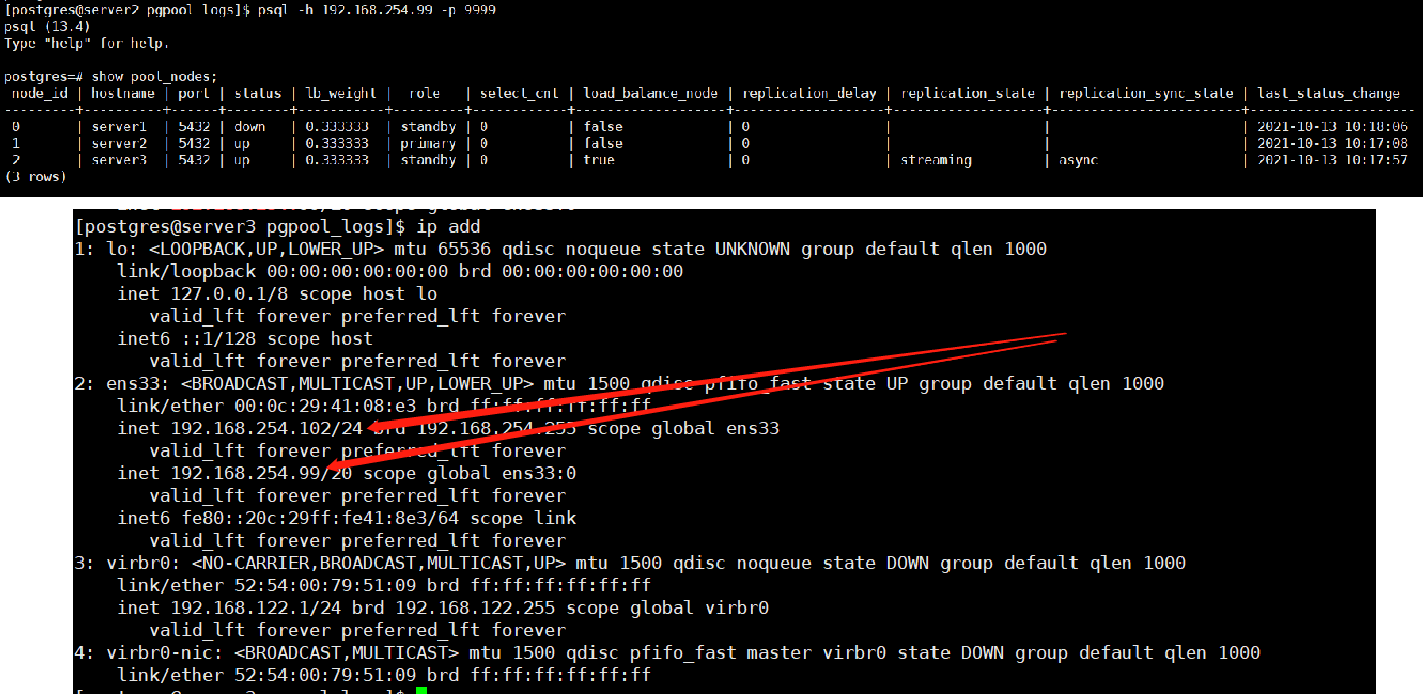
结果:原来的server2的从库被提升为新主库,server3的从库重新指向server2,原来在sever1上的vip漂移到server3 102上。
4,恢复100
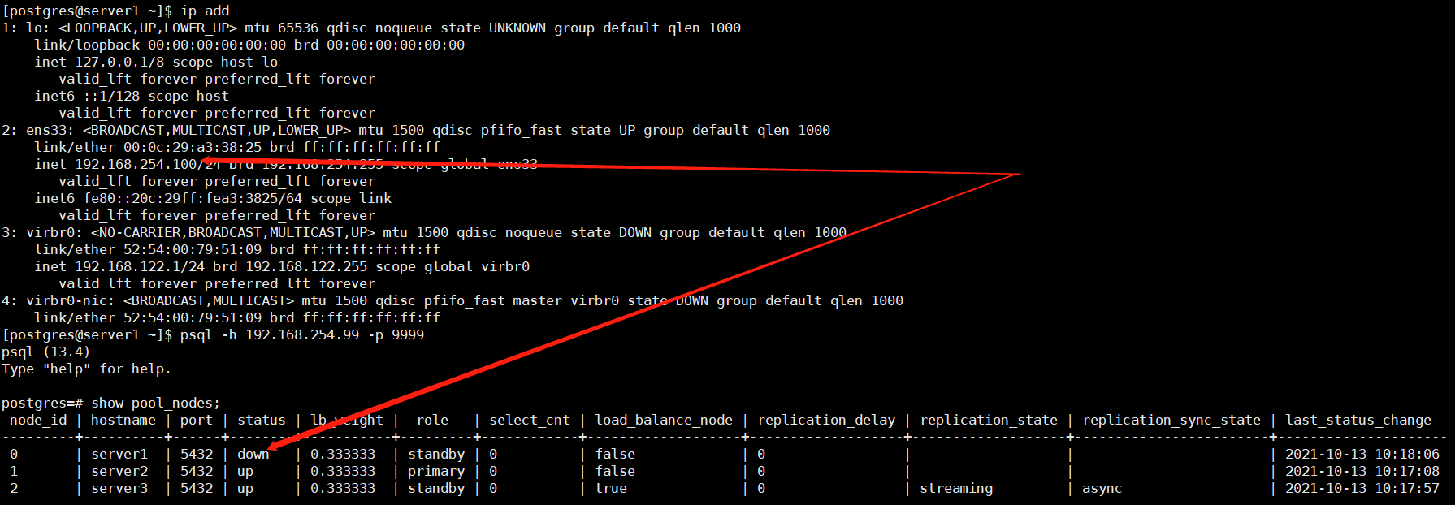
结果:server1启动之后,sever1依然是“down”状态,需要进行手动加入到集群中。
手动恢复节点1
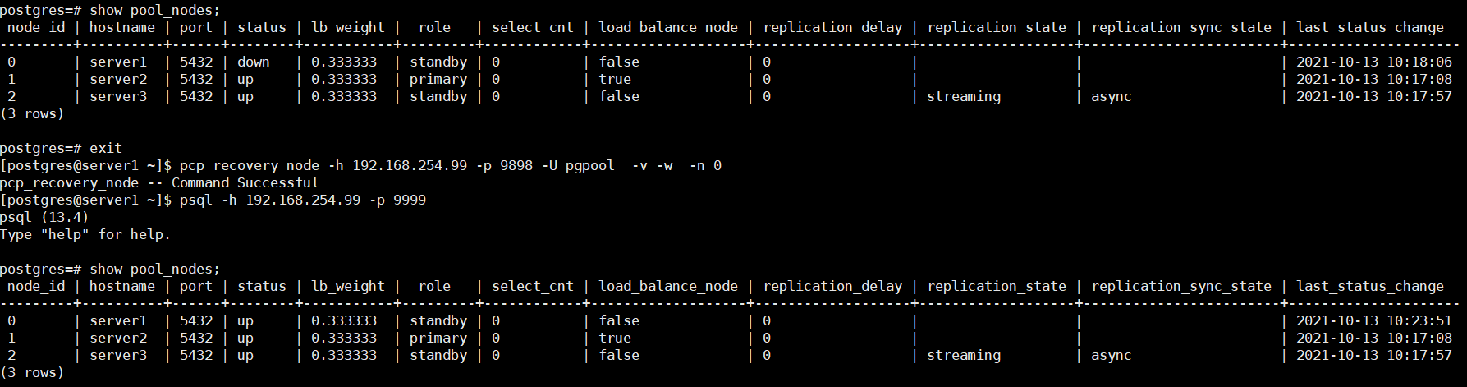
测试完毕
