




偶尔启动集群发现一个shard replica set一直处于recovering状态中
问题诊断
mongo --port 27100 --host 127.0.0.1
use admin
db.auth(“rs01Admin”,“Admin@01”);


查看同步进度
rs.status()
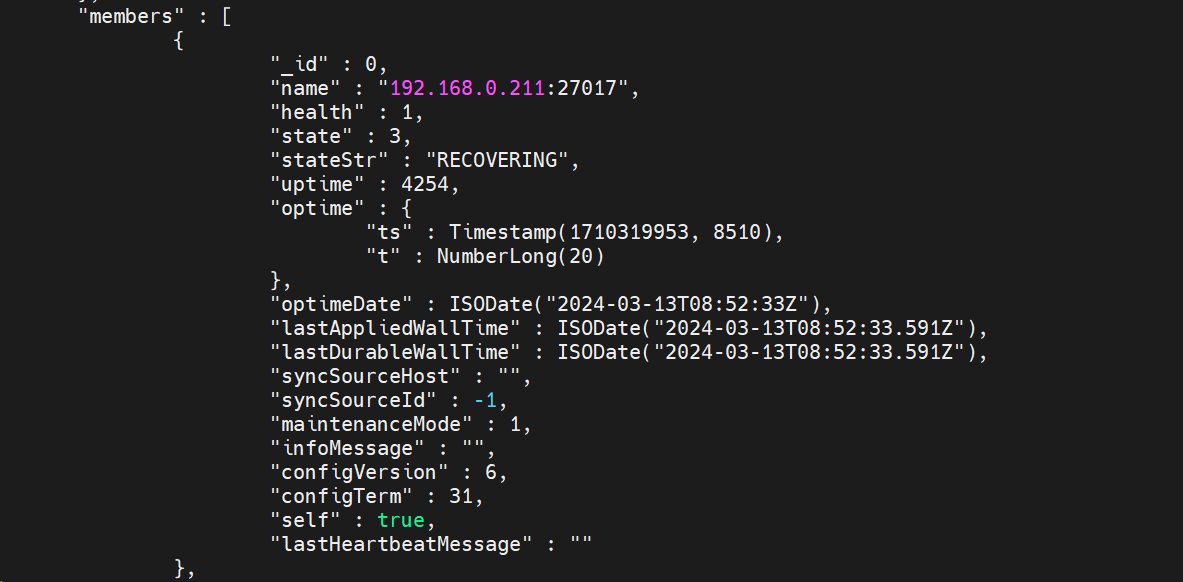

看不出问题,继续看对应的mongod.log寻找线索

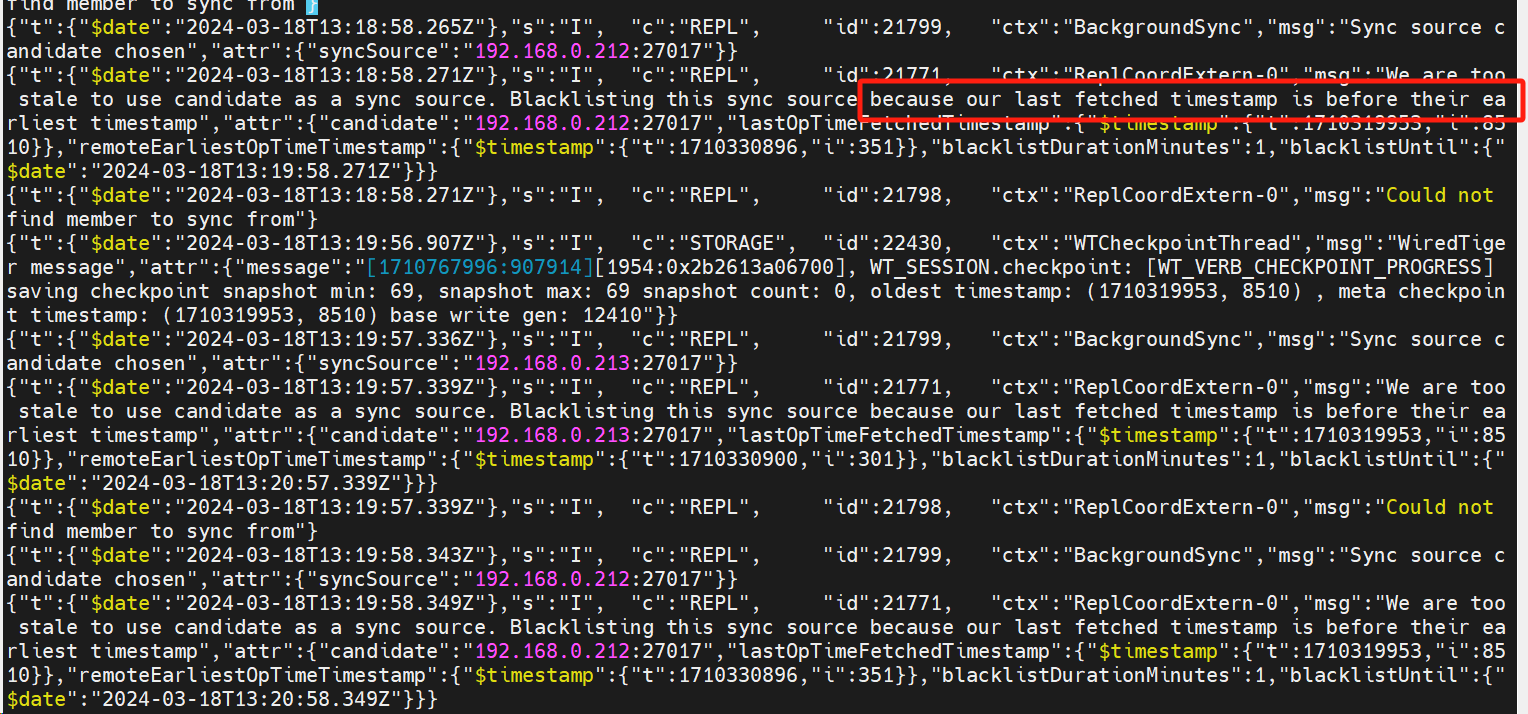
对应报错:“Blacklisting this sync source because our last fetched timestamp is before their earliest timestamp”因为最后一次获取的时间戳比阈值(t)还早而被列入黑名单
{"t":{"$date":"2024-03-18T13:20:58.427Z"},"s":"I", "c":"REPL", "id":21771, "ctx":"ReplCoordExtern-0","msg":"We are too stale to use candidate as a sync source. Blacklisting this sync source because our last fetched timestamp is before their earliest timestamp","attr":{"candidate":"192.168.0.212:27017","lastOpTimeFetchedTimestamp":{"$timestamp":{"t":1710319953,"i":8510}},"remoteEarliestOpTimeTimestamp":{"$timestamp":{"t":1710330896,"i":351}},"blacklistDurationMinutes":1,"blacklistUntil":{"$date":"2024-03-18T13:21:58.427Z"}}}
通过报错提示超过时间同步限制 blacklistDurationMinutes
查询集群机器时间,确认差异:
ssh node01 date; ssh node02 date; ssh node03 date;

问题解决
1.设置时间同步
/usr/sbin/ntpdate -u ntp.tencent.com && /usr/sbin/hwclock -w #手动
#自动
cat <<EOF>>/var/spool/cron/root
*/15 * * * * /usr/sbin/ntpdate -u ntp.tencent.com && /usr/sbin/hwclock -w
EOF
-
重启mongodb,删除节点,再添加节点
#primary rs.remove("192.168.0.211:27017"); #清理数据,重启mongod进程,故障节点执行 mongod -f /data/mongodb/standalone/conf/mongo.conf #primary rs.add("192.168.0.211:27017") -
登录mongodb 对应shard验证是否正常
mongo --host 127.0.0.1 --port 27017
use admin;
db.auth("rs01Admin","Admin@01");
rs.status()
观察发现一切正常

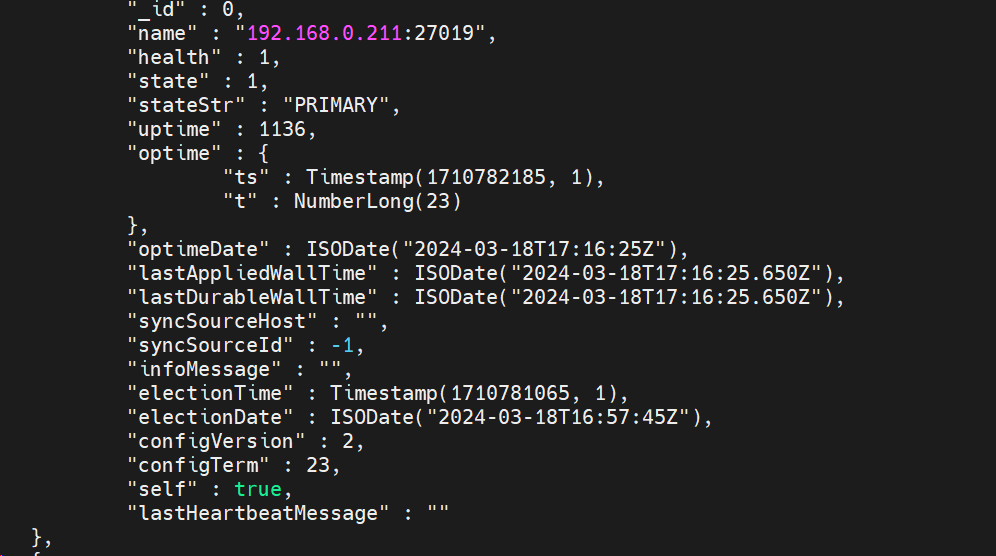
总结:对于任何集群都是需要时间同步,网络互通(不能过大延时);如果短暂问题可以通过同步时间来修复,如果隔了很久才处理,很可能由于oplog覆盖再也不能同步,则需要重做了
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
