




AIGC与RAG
人工智能生成内容(AIGC)的发展得益于模型算法、可扩展的基础模型架构以及丰富的高质量数据集的进步。虽然AIGC取得了显著的性能,但仍面临一些挑战,如难以保持最新和长尾知识、数据泄漏的风险以及与训练和推理相关的高成本。

最近出现的检索增强生成(RAG)作为一种范式应运而生,旨在解决这些挑战。在本文中,我们全面审视了将RAG技术整合到AIGC场景中的现有工作。
RAG流程
图1显示了典型的RAG过程:给定一个输入查询,检索器定位并查找相关的数据源,然后检索结果与生成器交互以增强整个生成过程。
检索结果可以以不同的方式与生成过程交互:
作为生成器的增强输入; 在生成的中间阶段作为潜在表示加入; 以logits的形式对最终生成结果做出贡献;
甚至可以影响或省略某些生成步骤。此外,在典型的基础RAG过程基础上,还提出了许多增强措施来提高整体质量。这些增强措施涵盖了特定组件的方法以及针对整个流程的优化。
尽管RAG的概念最初是在文本到文本生成中出现的,但它也已经适应了各种领域,包括代码、音频、图像、视频、三维、知识和科学人工智能。特别是,RAG的基本思想和过程在各种模态之间基本一致。
RAG组成结构
整个RAG系统由两个核心模块组成:检索器和生成器。检索器负责从构建的数据存储中搜索相关信息,生成器负责产生生成的内容。
RAG过程展开如下:首先,检索器接收输入查询并搜索相关信息;然后,原始查询和检索结果通过特定的增强方法馈送到生成器中;最后,生成器产生所需的结果。
检索模块
检索是指识别和获取与信息需求相关的信息系统资源。具体来说,我们考虑的信息资源可以被概念化为一个键-值存储,其中每个键对应一个值(通常情况下,和是相同的)。给定一个查询,目标是使用相似度函数搜索出前个最相似的键,并获取其对应的值。
根据不同的相似度函数,现有的检索方法可以分为稀疏检索、密集检索和其他方法。对于广泛使用的稀疏和密集检索,整个过程可以分为两个不同的阶段:在第一个阶段,每个对象被编码为特定的表示;在第二个阶段,构建索引以组织数据源以实现高效搜索。
稀疏检索器
稀疏检索方法广泛应用于文档检索中,其中键实际上是要搜索的文档(在这种情况下,值是相同的文档)。这些方法利用诸如TF-IDF、查询可能性和BM25等词项匹配度量标准,从文本中分析词汇统计信息,并构建倒排索引以实现高效搜索。
其中,IDF是逆文档频率权重,是词在文档中出现的次数,是文档的长度,avgdl是语料库集合中的平均文档长度,和是可调参数。
为了实现高效的搜索,稀疏检索通常利用倒排索引来组织文档。具体地,查询中的每个词执行查找以获取候选文档列表,然后根据它们的统计分数对这些文档进行排名。
密集检索器
与稀疏检索不同,密集检索方法使用密集嵌入向量表示查询和键,并构建近似最近邻(ANN)索引以加速搜索。这种范式可以应用于所有模态。对于文本数据,包括BERT和RoBERTa在内的最新预训练模型被用作编码器,分别对查询和键进行编码。类似于文本,已经提出了用于编码代码数据、音频数据、图像数据和视频数据的模型。密集表示之间的相似度分数可以使用余弦相似度、内积或L2距离等方法计算。
在训练过程中,密集检索通常遵循对比学习范式,使正样本更相似,负样本更不相似。已经提出了一些硬负样本技术来进一步提高模型质量。在推理过程中,使用近似最近邻(ANN)方法进行高效搜索。开发了各种索引来服务于ANN搜索,例如树索引、局部敏感哈希、邻居图索引(例如,HNSW、DiskANN、HMANN)以及图索引和倒排索引的组合
RAG基础范式
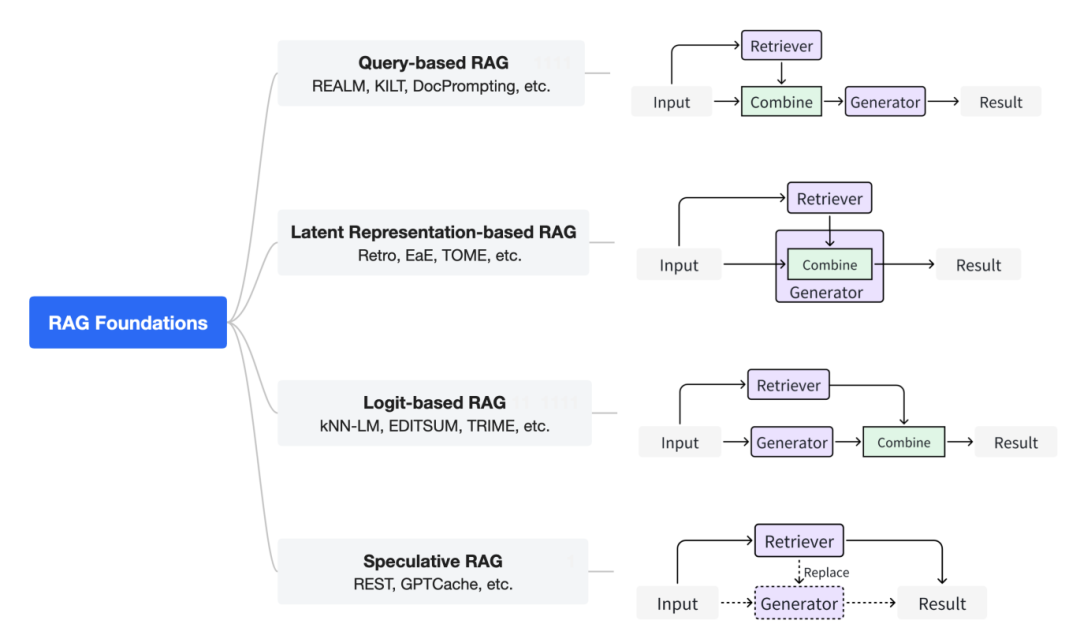 基于查询的RAG
基于查询的RAG
基于查询的RAG也被称为提示增强。它将用户的查询与检索过程中提取的文档见解直接整合到语言模型输入的初始阶段。这种范式是RAG应用中广泛采用的方法。
一旦文档被检索,它们的内容就会与原始用户查询合并,以创建一个复合输入序列。然后将这个增强的序列馈送到预训练语言模型中生成响应。
基于潜在表示的RAG
基于潜在表示的RAG框架中,生成模型与检索到的对象的潜在表示进行交互,从而增强模型的理解能力和生成内容的质量。
FiD技术利用BM25和DPR来获取支持性段落。它将每个检索到的段落及其标题与查询连接起来,并通过编码器分别处理它们。
基于Logit的RAG
基于Logit的RAG方法着重于在解码过程中将检索信息与语言模型生成的logits结合起来。这些方法通过将来自外部来源的相关信息纳入原始语言模型的输出,来增强其性能。
增强RAG性能
我们根据它们的增强目标将现有方法分为5个不同的类别:输入、检索器、生成器、结果和整个流程。

输入增强
输入指的是用户的查询,最初被输入到检索器中。输入的质量显著影响了检索阶段的最终结果。因此,增强输入变得至关重要。在这一部分,我们介绍两种方法:查询转换和数据增强。
查询转换:查询转换可以通过修改输入查询来增强检索结果。 数据增强:数据增强是指在检索之前提前改善数据,例如去除不相关信息、消除歧义、更新过时的文档、合成新数据等。
检索器增强
在RAG系统中,检索过程至关重要。一般来说,内容质量越好,LLMs在上下文学习以及其他生成器和范式中的能力就越容易被激发。内容质量越差,模型产生幻觉的可能性就越大。
递归检索:递归检索是在检索之前对查询进行分割,并进行多次搜索以检索更多且质量更高的内容的过程 分块优化:分块优化技术是指调整块的大小以获得更好的检索结果。句窗检索是一种有效的方法,通过获取小块文本并返回围绕检索段的相关句子窗口来增强检索。 微调检索器:作为RAG系统中的核心组件,检索器在整个系统运行过程中起着至关重要的作用。一个好的嵌入模型可以将语义上相似的内容在向量空间中靠近彼此。 重新排序:重新排序技术是指重新排列检索到的内容,以获得更大的多样性和更好的结果,减少由于将文本压缩为向量而导致的信息丢失对检索质量的影响。 元数据过滤:元数据过滤是帮助处理检索到的文档的另一种方法,它使用元数据(如时间、目的等)来过滤检索到的文档,以获得更好的结果。
生成器增强
在RAG系统中,生成器的质量通常决定了最终输出结果的质量。因此,生成器的能力决定了整个RAG系统有效性的上限。
提示工程:提示工程技术专注于提高LLMs输出质量,如提示压缩、回溯提示、主动提示、思维链提示等,都适用于RAG系统中的LLM生成器。 解码调优:解码调优是指在生成器处理过程中添加额外控制,可以通过调整超参数以实现更大的多样性,以某种形式限制输出词汇等方式实现。 微调生成器:生成器的微调可以增强模型对更精确的领域知识或更好地与检索器配合的能力。
RAG管道增强
自适应检索:一些关于RAG的研究和实践表明,检索并不总是有利于最终生成的结果。当模型本身的参数化知识足以回答相关问题时,过多的检索会导致资源浪费,可能会增加模型的混乱。 迭代式RAG:采用迭代的检索-生成管道,以更好地利用分散在不同文件中的有用信息,用于代码补全任务。在第i次迭代期间,它将检索查询与先前生成的代码一起进行增强,从而获得更好的结果。
RAG应用案例
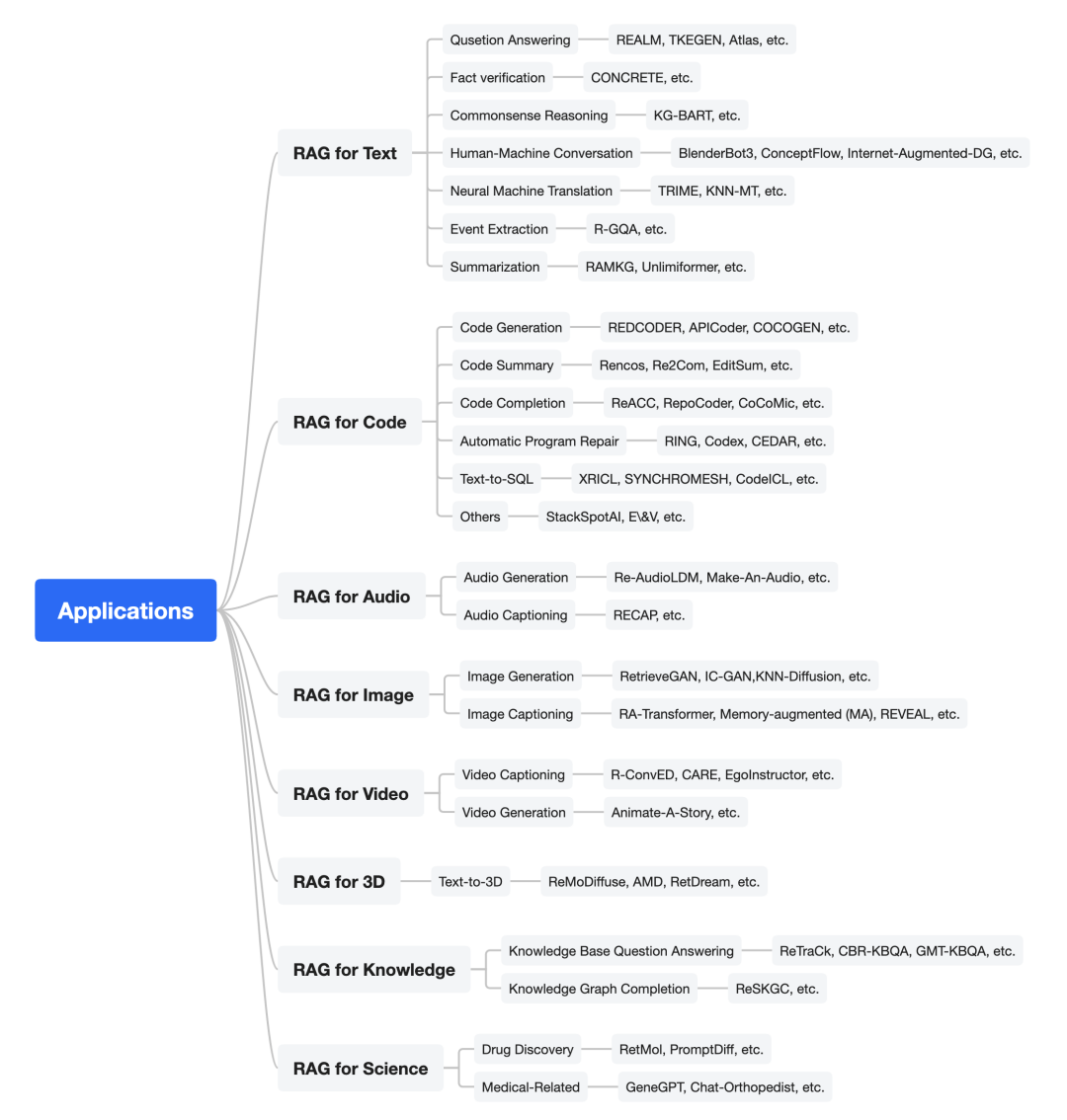 文本RAG
文本RAG
问答:问答涉及从广泛而全面的文本来源中提供对提出的问题的响应的过程。 事实验证:事实验证涉及评估信息的真实性,在自然语言处理(NLP)、信息检索和数据挖掘等学科中起着关键作用。 事件提取:事件提取是自然语言处理(NLP)中的一项专门任务,旨在从非结构化文本数据中确定和提取特定类型的事件实例。 摘要:在自然语言处理(NLP)领域,摘要是一项旨在从冗长的文本中提炼关键信息并产生简明、连贯摘要的任务,这些摘要包含了主要主题。
代码RAG
代码生成:代码生成的目标是将自然语言(NL)描述转换为代码实现,可以看作是文本到代码的过程。 代码摘要:代码摘要的目标是将代码转换为自然语言(NL)描述,这是一个代码到文本的过程。
音频RAG
音频生成:音频生成的目标是根据自然语言输入生成音频。 音频字幕:音频字幕的目标是将音频数据生成自然语言数据,基本上是一个序列到序列的任务。
图像RAG
图像生成:RAG通过整合信息检索系统来增强生成模型。 图像字幕生成:通过理解图片来生成图像字幕。
原始论文链接:https://arxiv.org/pdf/2402.19473.pdf
# 学习大模型 & 讨论Kaggle #
每天大模型、算法竞赛、干货资讯

