




PBE:Prepare-Bind-Execute
看腻了就来听听视频演示吧:https://www.bilibili.com/video/BV1D142127Cx/
现象
应用JDBC接口调用SQL执行慢(几十分钟),客户端Dbeaver或psql执行快(秒内)
概念
SQL语句结构完全相同,但入参不同,这种情况下考虑在生成执行计划时,将SQL中不同的数值以参数的形式作为替代($)。此后的每次查询都可以根据语句中的数值将执行计划中的参数替换后再做执行,以此来提高此类SQL的执行效率。
实现方式是使用 java 的 preparedStatement 预编译接口,在数据库内核中对应的名称即为PBE(Prepare-Bind-Execute)。
在执行一个SQL时,首先生成执行计划(进行语义分析、词法解析、逻辑优化、物理优化)、执行、结果传输等操作。如果一个SQL在应用中反复使用,可以将此SQL执行计划固化下来,只做一次prepare,后面执行时就不需要进行前面执行计划的生成操作,直接使用prepare好的执行计划。
PREPARE语句
特点:
- 会话级别,session结束PREPARE语句也不存在了。下次再使用需重新创建
- PREPARE语句不能在多个并发的client中共有
- PREPARE语句可以通过DEALLOCATE命令清除。
- 会话中所有可用的PREPARE语句获取可查询系统视图:pg_prepared_statements
PostgreSQL默认前5次执行时每次都会根据实际传入的实际绑定变量生成执行计划(custom plan),即每次都是硬解析;当第6次开始执行时,会生成一个通用的执行计划(generic plan),同时与前5次的执行计划进行比较,如果比较的结果是通用执行计划不比前5次的执行计划差,以后就会把这个通用的执行计划固定下来,这之后即使传入的值发生变化后,执行计划也不再变化。这就相当于Oracle打开了绑定变量窥视的功能。
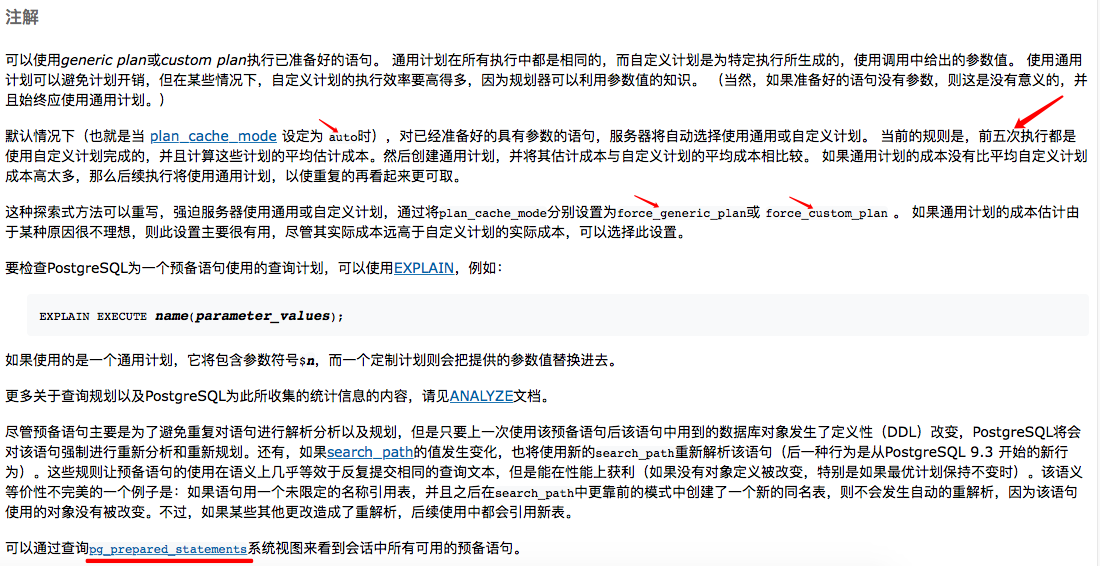
PG 12 中新增plan_cache_mode参数,用来改变执行计划的缓存模式。
plan_cache_mode参数介绍:

其中default值就是auto,即自动修正执行计划。
force_custom_plan:为每个指定的参数重新创建新的执行计划。
force_generic_plan:不依赖与参数的值,执行计划可以在各个语句间重复使用。
案例模拟
创建存在严重数据倾斜的数据场景,即为“PostgreSQL”的数据有100万,而为“Oracle”的数据是2条
-- 创建测试表和数据
drop table IF EXISTS t_pbe;
create table t_pbe(col1 serial, col2 text);
insert into t_pbe(col2) select 'PostgreSQL' from generate_series(1, 1000000);
insert into t_pbe(col2) select 'Oracle' from generate_series(1, 2);
CREATE INDEX idx_t_pbe_col2 ON t_pbe(col2);
vacuum analyze t_pbe;
复制常量模拟执行计划,可以看到col2字段的“PostgreSQL”数据用的是全表扫描(这里用到并行提高了查询效率),“Oracle”数据是走仅索引扫描
-- 常量模拟执行计划
explain (analyze,buffers) select count(*) from t_pbe where col2='PostgreSQL';
explain (analyze,buffers) select count(*) from t_pbe where col2='Oracle';
复制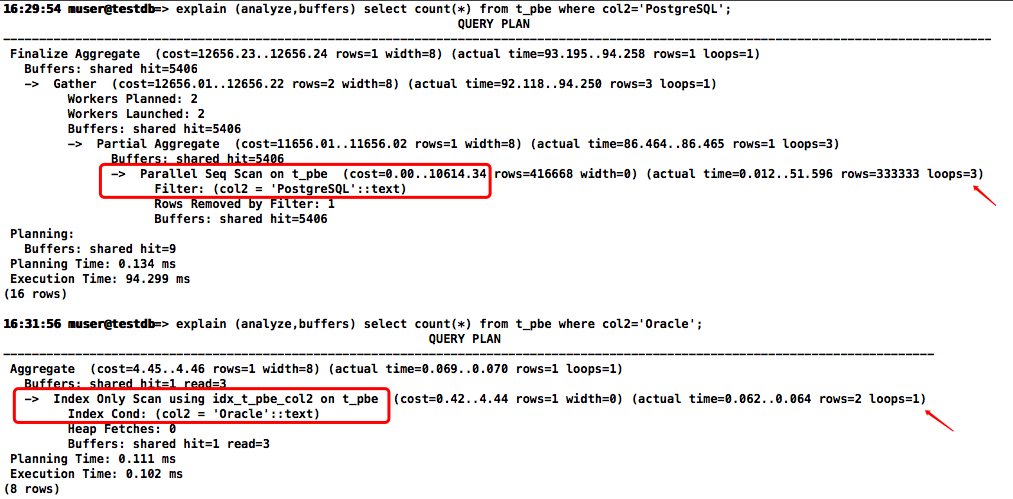
PBE模拟执行计划,默认plan_cache_mode为auto,两次都是cplan的执行计划,还是全表扫和索引扫描,针对不同的值生成了不同的执行计划
-- 模拟PBE,SQL如参用$1,$2...
prepare pbe_test as select count(*) from t_pbe where col2=$1;
-- 执行
explain (analyze,buffers) execute pbe_test('PostgreSQL');
explain (analyze,buffers) execute pbe_test('Oracle');
-- 取消
DEALLOCATE pbe_test;
-- PG14 新增统计软/硬解析次数
select * from pg_prepared_statements\gx
复制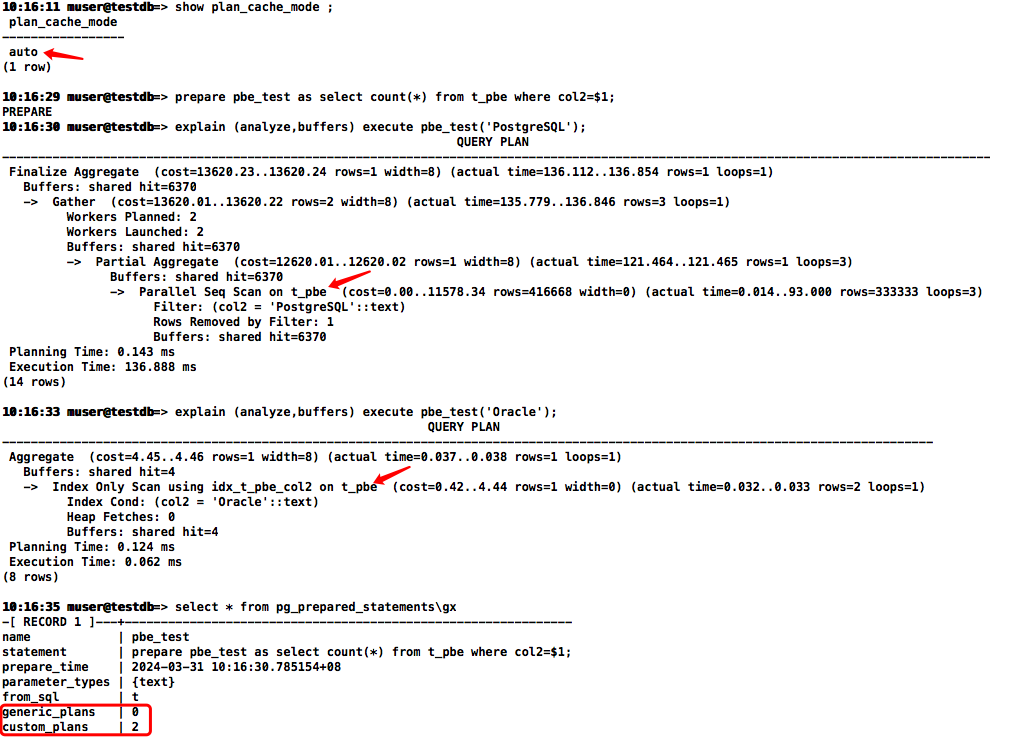
PBE模拟执行计划,将参数值改成force_generic_plan,两次gplan的执行计划都是走一样的执行路径,即无论参数值是什么执行计划已经被固定了
set plan_cache_mode TO force_generic_plan;
复制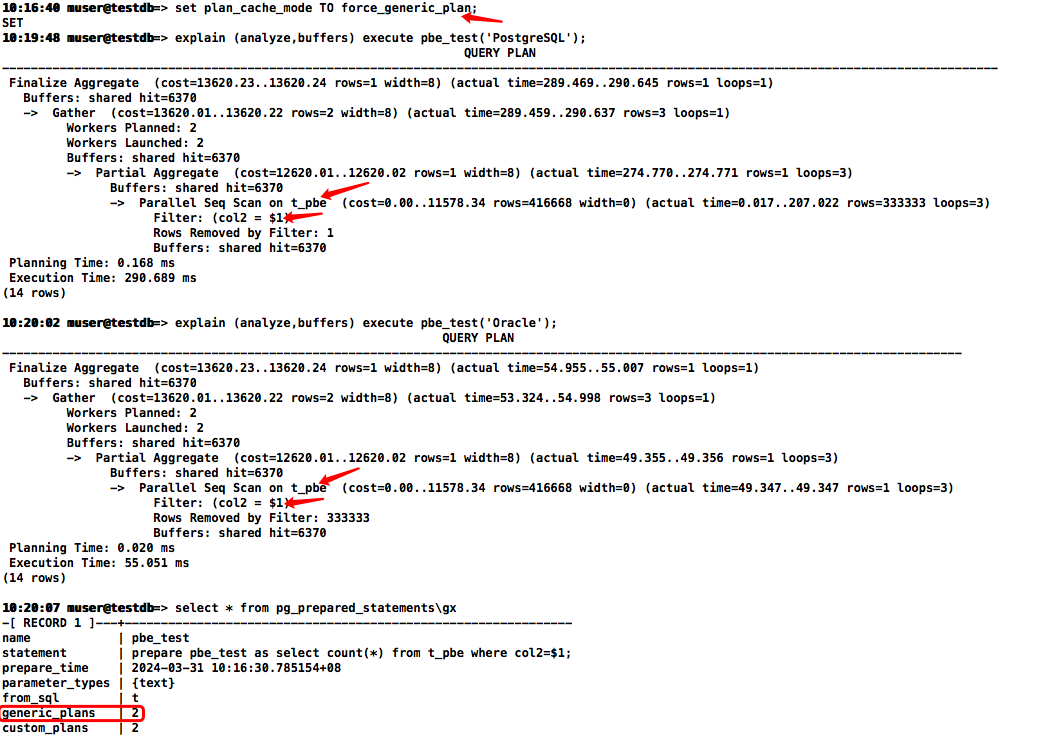
总结
- 针对PostgreSQL默认参数plan_cache_mode为auto,即前五次自定义生成执行计划第六次再固定执行计划,在针对数据倾斜严重的OLTP或OLAP场景,可能就会出现严重的性能抖动问题,即同一条SQL语句突然变慢。对此可调整参数plan_cache_mode为force_custom_plan也能提升这个SQL的性能,但建议是会话级别set调整。不建议实例级调整,毕竟面对DML操作,如果每次都要生成计划,会很影响效率。
- 对OLAP(复杂分析查询)由于并发低,每次请求的条件输入评估选择性可能差异较大,每条SQL(只是输入参数、WHERE条件不一样)也许使用不同的执行计划才能达到最佳的执行效率,因此OLAP系统,建议可以使用force_custom_plan。
- 对于OLTP请求,并发高,数据倾斜较少,建议使用AUTO(自动修正)。 针对数据倾斜场景会话级使用force_custom_plan。



