




点蓝字关注 设为星标 ☆ 优先赏阅
数据化审计 SmartAudit:问题导向、应用至上、解决痛点
应用场景
在审计项目的前审阶段,审计人员通常需进行大量的数据准备工作,为下一步进行数据挖掘与分析提供基础。
通常情况下,对从各类业务系统提取的数据,或是业务部门提供的各类业务报表,审计人员可直接使用Excel进行分析处理。
但如果获取的数据是多源异构的小文件,且文件数目比较多的时候,需打开大量文件,并且受限于电脑自身硬性配置,导致实际处理的数据量较小。
本文主要介绍使用 Python 调用 IBM DB2 数据库接口实现多源异构数据批量建表及数据导入,可大大提高前审阶段的数据准备效率。
处理环境
(1)安装IBM DB2数据库。
(2)安装Python 3.X环境(本文使用anacoda3整合环境),并安装IBM_DB库函数。若可链接外网,可使用“pip install ibm_db”安装。
Python 整合环境 anacoda 的安装参见文章:0基础教程 | 1x01-Python整合平台Anaconda的安装和使用
若无法访问外网或是Python版本较低,建议采取离线安装的方式。
如何在不联网的内部工作环境安装 Python 库,参见文章:应用 | 如何在不联网的离线环境下安装python库
具体步骤如下:
第一步:外网下载ibm_db库函数 (本文版本为3.0.4),并将安装包解压得到ibm_db-3.0.4文件夹,复制到anacoda3/Lib/site-packages文件夹目录下。
第二步:打开解压的文件夹,在cmd窗口执行“python setup.py install”,并根据按照提示,在外网下载驱动软件 后解压得到clidriver文件夹,复制到ibm_db-3.0.4文件夹目录下,在cmd窗口再次执行“python setup.py install”。
第三步:安装完成后,进入Python执行“import ibm_db”语句。若报错显示“ImporError:DLL load failed”或者类似找不到路径的信息,需在site-packages文件夹目录下查找ibm_db-3.0.4、ibm_db-3.0.4.egg-info两个文件夹,确保clidriver文件夹在上述两个文件夹均存在。
解决思路
对于有数据字典的数据:
使用pandas库函数读取数据结构;
生成SQL建表语句,使用ibm_db库函数建表;
使用pandas库函数读取数据文件;
逐行生成插入语句,使用ibm_db库函数导入数据。
对于仅有表头而未配套数据字典的数据:
使用pandas库函数读取数据文件;
确定表头所在行数;
生成SQL建表语句,使用ibm_db库函数建表;
逐行生成插入语句,使用ibm_db库函数导入数据。
实战案例
以常见的有表头而未配置数据字典的数据批量解析和导入为例。
第一步:数据准备和特征分析。
确定数据格式及特征。对需要导入的数据进行预览和分析,总结数据特征。
第二步:程序所需的支持库。
pandas库函数:处理excel文件;
math库函数:数学运算;
os库函数:处理文件;
ibm_db库函数:连接调用数据库。

第三步:建立Python与DB2数据库的连接。
根据需连接的数据库属性,做好用户名、密码等参数的维护。

第四步:获取拟导入DB2数据库的文件名并读取数据。
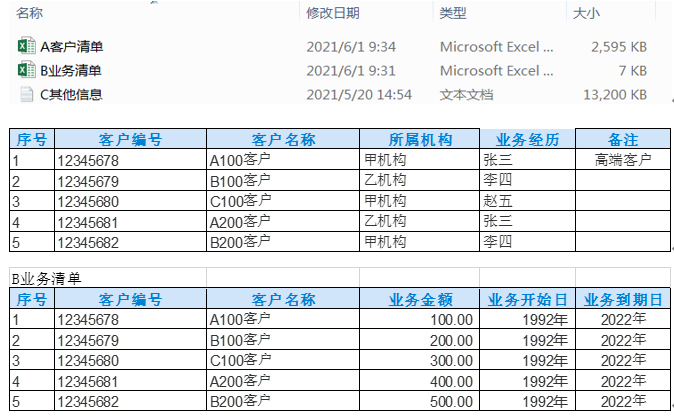
考虑到文件夹内有其他数据,可通过if判读语句选取拟导入数据库的文件,并通过for循环语句逐个提取文件数据。例如,本文对应文件夹中有txt和xlsx两类文件(如图一所示),通过判断语句选择拟导入数据库的xlsx文件。
考虑到每个业务报表的第一行可能是表头,也可能是表名,为避免读取缺失,在使用pandas函数读取文件时,设置header=None,即所读取的文件没有列名。

第五步:确定表头并生成表结构。
此类数据中,通常是“第一行为表名+第二行为列名+第三行及以后行为数据”或“第一行为列名+第二行及以后行为数据”两类格式。针对前者,python读取的第一行仅第一列有数据,其他列均为空值;针对后者,python读取的第一行均有数据。结合数据特征,使用math函数判断第一行第二列数据是否为空值,进而确定列名所在行数。
考虑到math语句仅能处理数值计算,若第一行为列名,则第二列为字符串无法使用math函数从而导致程序会报错,故使用try语句,避免程序报错后无法运行。
DB2对数据表头有一定限制,部分特定字符无法作为表头,故使用replace替换对应字符串的特定字符,确保表头无限制字符。最后,生成表结构(sql_list),并设置参数a作为对表头所在行数的标识,便于后续程序的数据导入。

第六步:建表并导入数据。
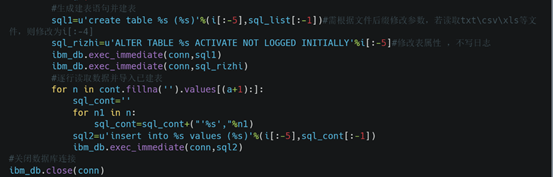
根据第五部分生成的表结构,生成SQL建表语句(sql1),并执行相关程序。
读取、生成插入的数据(sql_cont),生成数据插入语句(sql2),并逐行插入DB2对应的新建表。其中,Python空值是Nan,而DB2空值是Null,故使用“cont.fillna('')”语句替换Python读取数据中的空值Nan。
使用说明
1-导入速率
Python调用DB2插入数据,效率等同于使用Import对已建成表格导入数据。
因此,该程序更适用于多文件、小数据量的批量导入,而对于数据量大且仅能存储为文本类型的文件,建议使用DB2命令窗口Load导入。
2-编码格式
Python 2.X默认编码是ascii,而Python 3.X、IBM DB2默认编码均是utf-8。因此,建议使用Python 3.X进行程序实现,避免编码问题。
使用Python 3.X的pandas库函数读取Excel文件时,支持utf-8和GBK(可兼容GB2312)的自动识别;而使用pandas、io等库函数读取txt、csv等类型文件时,无法实现utf-8和GBK的自动识别,即文件编码若不是utf-8,均需转码后才能导入DB2。因此,建议使用前确定数据编码格式,若不属于utf-8、GBK或者可兼容的编码,需先对数据进行转码操作。
在案例中,为方便处理,SQL建表将字段类型统一设置成varchar。而得益于Python 3.X的pandas库函数读取Excel文件时,可自动将GBK转码成utf-8,使千分符格式的数字转换成纯数字,从而在编辑SQL脚本时,可使用cast语句对数字进行转码操作,即可直接使用相关字段进行数值计算。
