




前言
上一章节我们讲解了mysql中的子查询,在最后一个案例里面用到了连接,这章节我们就讲一下msyql的连接。在上章节中有两个筛选条件where 和 having ,在这里我们会大致讲一下两者的区别。
where和having的区别
where:行级别的操作【不能跟聚合函数】,通常是筛选数据中每行的需要过滤/展示 的数据,作用于表和视图。
having:分组后条件筛选【可跟聚合函数,也叫做聚合选择】,不能够单独使用,需要在group by xxx 后面使用,作用于组。
两者一般组合使用是:where + group by + having + 查询函数
mysql的几种连接讲解
讲这一章节的时候我突然想起来,在18年的时候,同事曾经执行了一个内连接,当时两张表大小都是接近千万条数据,然而当时忘记写等值条件,造成了“笛卡尔积”,最后造成mysql服务宕机。
这件事让我记忆颇清,因为后续我需要恢复数据,补一些脚本,花了比较长时间。所以后面同学 别忘记写等值条件。
先说一下什么是“笛卡尔积”,看百度解释:

这样看也没有直接的感觉,现在看下面的案例:
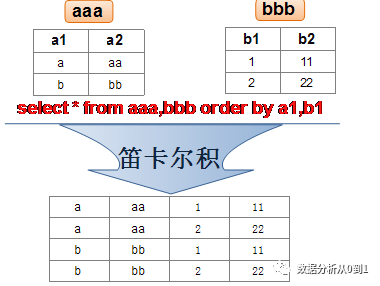
这个还是两个2行的小表造成的 2*2=4 行的表,这样大家感觉没啥感觉,但是当 千万*千万 的时候,数字后的 0 我们都有看好一会吧。
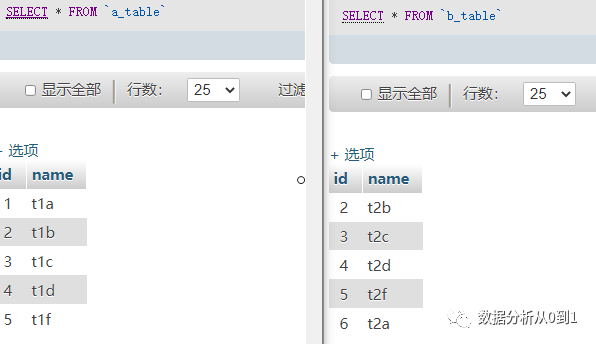
有两组表:a_table 和 b_table:
1、内连接
内连接查询,就是取左连接和右连接的交集,如果两边不能匹配条件,则都不取出。
关键字:inner join on
语句:
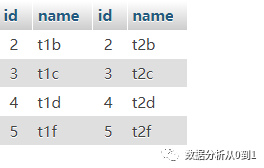
select * from a_table a inner join b_table b on a.id = b.id;
结果是:
2、左连接
左连接查询即【左表】在左不动,【右表】在右滑动,【左表】与【右表】通过一个关系来关联行,【右表】去匹配【左表】,【右表】记录不足的地方均为NULL 。注:left join 是left outer join的简写。
关键字:left join on
语句:
SELECT * FROM a_table a left join b_table b ON a.id = b.id;
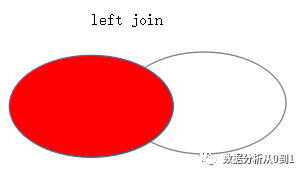
结果是:
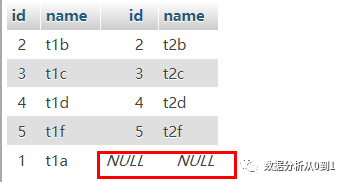
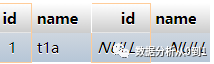
筛选条件:左表中去除共同数据
select * from a_table t1 left join b_table t2 on t1.id = t2.id where t2.id is null
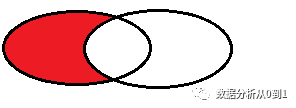
结果是:
3、右连接
右连接是以【右表】为主表,会将【右表】所有数据查询出来,而【左表】则根据条件去匹配,如果【左表】没有满足条件的行,则左边默认显示NULL。
关键字:right join on
语句:
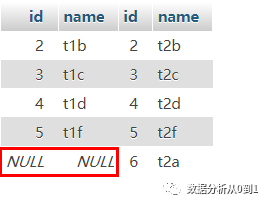
SELECT * FROM a_table a right outer join b_table b on a.id = b.id;
结果是:
筛选条件:右表中去除共同数据
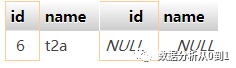
select * from b_table t1 left join a_table t2 on t1.id = t2.id where t2.id is null
结果是:
4、合并
union语句注意事项:
通过union连接的SQL它们分别单独取出的列数必须相同;
不要求合并的表列名称相同时,以第一个sql 表列名为准;
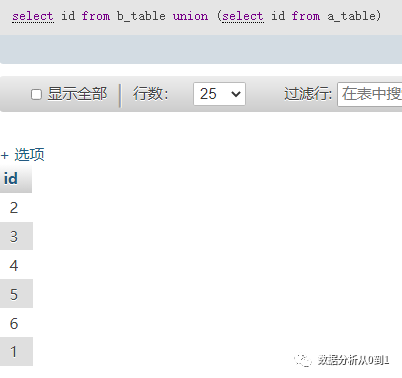
使用union查询会将重复的行过滤掉;
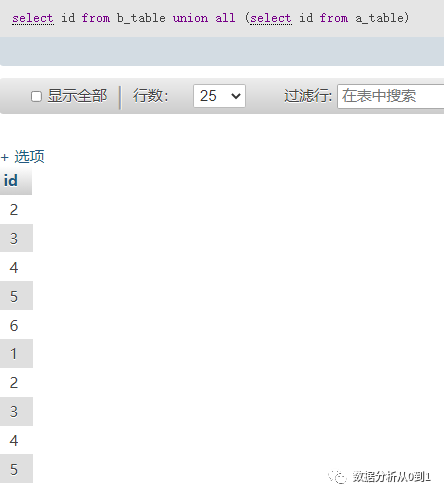
使用union all查询所有,重复的行不会被过滤;
关键字:union /union all
union 的使用
select id from b_table union (select id from a_table)
union all 的使用
select id from b_table union all (select id from a_table)
本章节也是mysql实操讲解的最后一章,介绍了工作中常使用mysql连接,前几章节包含安装、基础查询关键词讲解、去重、排序、子查询、连接。虽然内容不多,没有包含更多的表操作,但是对于数据分析提取和分析数据是够用了。
其中大部分业务场景都是交叉类型的,这样就需要不同的语句交叉使用,但是核心的还是文章介绍的哪些。在后期就是孰能生巧,多练习。
