




大家好,今天和大家一起学习一下:RAG模式构建外部知识库 。 即上一篇介绍如何搭建私有大模型后 https://www.modb.pro/db/1776892702617047040,
可能有的朋友会问这个开源的大模型回答得都是一些基础的问题,一点专业性都没有,对我日常的工作没有任何帮助,更没有任何商业价值。
开源的大模型类似于人家训练好的预制菜,肯定是不知道你所从事的专业领域,这个时候需要把自己专业的相关知识组织成外部的知识库提供给大模型作参考。
这样大模型就可以理解我们的专业领域了,并且可以探索在某些垂直领域的场景上是否存在商业价值的可行性。
大模型的RAG方式就是为了解决以上问题的,关于RAG的定义:
RAG is an AI Framework that integrates large language models (LLMs) with external knowledge retrieval to enhance accuracy and transparency.
Pre-trained language models generate text based on patterns in their training data.
RAG supplements their capabilities by retrieving relevant facts from constantly updated knowledge bases
我们看到了RAG定义中的几个关键词: AI 框架, 整合外部知识, 支持即时更新的知识库。
我们再找一张RAG的架构图:
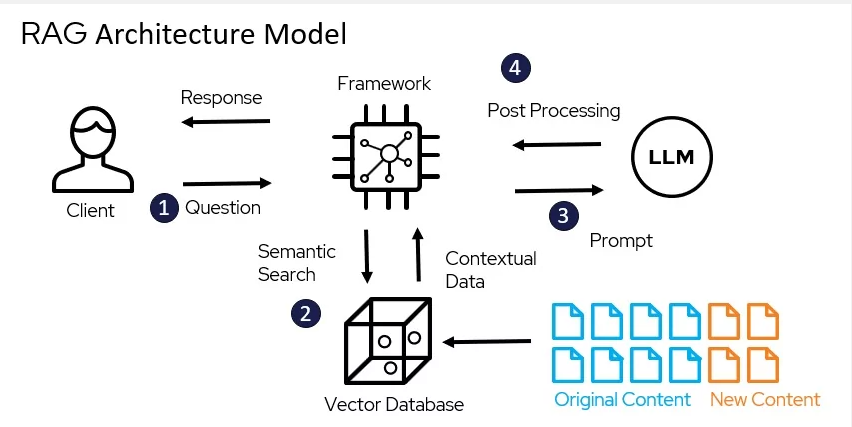
我们看到图中的 Original/New Connect 类似于我们的外部数据(像我们日常写的博客,笔记,邮件,电子书什么的),向量数据库Vector database 类似于存储我们外部知识的数据库:
市面上常见的向量数据库有很多种:对于DBA比较熟悉的mongo,es,pg 等等都对向量数据库有支持,图中的LLM就是我们之前搭建的大模型,最后我们可以看到Framework 在这架构图中
站在了C位,起到了整合RAG架构的核心地位。
关于Framework 我们选择 langchain, 关于langchain的定义:
LangChain is a framework for developing applications powered by large language models (LLMs).
LangChain simplifies every stage of the LLM application lifecycle:
Development: Build your applications using LangChain’s open-source building blocks and components. Hit the ground running using third-party integrations and Templates.
Productionization: Use LangSmith to inspect, monitor and evaluate your chains, so that you can continuously optimize and deploy with confidence.
Deployment: Turn any chain into an API with LangServe.
简单地说就是大模型的一个开发框架,支持开发,持续优化,部署发布API等功能。
至此我们理论上先输出了RAG的基本概念,下面我们来手动实际搭建一个外挂的知识库:
技术组件选型:
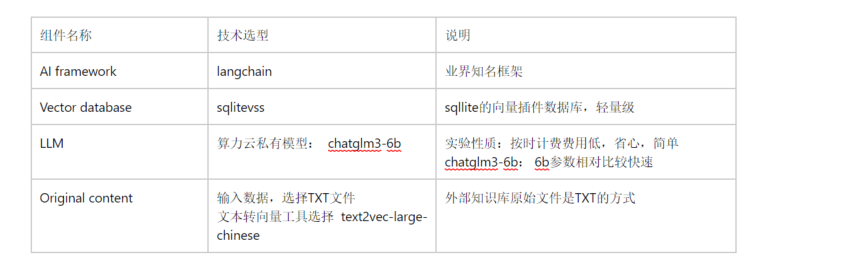
1)我们首先需要安装 langchain等框架组件包
pip install langchain
pip install sentence-transformers
pip install faiss-gpu
2)下载 text2vec-large-chinese 文本转向量工具
https://huggingface.co/GanymedeNil/text2vec-large-chinese
root@autodl-container-24624396c7-b5f6a2a8:~/autodl-tmp/model# git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
Cloning into 'text2vec-large-chinese'...
remote: Enumerating objects: 27, done.
remote: Total 27 (delta 0), reused 0 (delta 0), pack-reused 27
Unpacking objects: 100% (27/27), 160.54 KiB | 322.00 KiB/s, done.
Filtering content: 100% (2/2), 2.42 GiB | 5.58 MiB/s, done.
3)编写测试程序(文件写入SQLITE向量数据库)
本地的知识文本输入是:
templates = [‘墨天伦大表哥原名陈旭,英文名JASON’,
‘从事数据库一线运维工作多年’,
‘熟悉ORACLE,MONGO,PG,MYSQL等多种数据库的日常操作’,
‘博客代表作《一条SQL的奇幻旅程》’
‘目前忙于公司的去O大业,深陷多个项目,墨天伦相关博客暂时停止更新’,
‘未来会为大家来为接地气,实际工作中的去O问题以及解决方案的文章,大表哥 不完虚的!!!’]
import sys
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from functools import lru_cache
import pdb
from transformers import AutoTokenizer, AutoModel
# patch HuggingFaceEmbeddings to make it hashable
def _embeddings_hash(self):
return hash(self.model_name)
HuggingFaceEmbeddings.__hash__ = _embeddings_hash
embeddings = HuggingFaceEmbeddings(model_name='/root/autodl-tmp/model/text2vec-large-chinese')
# 缓存知识库数量
CACHED_VS_NUM = 1
# 知识库检索时返回的匹配内容条数
VECTOR_SEARCH_TOP_K = 2
VS_PATH = '/root/autodl-tmp/vctdb'
# will keep CACHED_VS_NUM of vector store caches
@lru_cache(CACHED_VS_NUM)
def load_vector_store():
return FAISS.load_local(VS_PATH, embeddings,allow_dangerous_deserialization=True)
def write_templates(templates):
vector_store = FAISS.from_texts(templates, embeddings)
vector_store.save_local(VS_PATH)
def get_template(inputs):
vector_store = load_vector_store()
related_docs_with_score = vector_store.similarity_search_with_score(inputs, k=VECTOR_SEARCH_TOP_K)
#print(related_docs_with_score)
tempalte = related_docs_with_score[0][0].page_content
return tempalte
templates = ['墨天伦大表哥原名陈旭,英文名JASON',
'从事数据库一线运维工作多年',
'熟悉ORACLE,MONGO,PG,MYSQL等多种数据库的日常操作',
'博客代表作《一条SQL的奇幻旅程》'
'目前忙于公司的去O大业,深陷多个项目,墨天伦相关博客暂时停止更新',
'未来会为大家来为接地气,实际工作中的去O问题以及解决方案的文章,大表哥 不完虚的!!!']
write_templates(templates)
运行程序之后,我们可以看见已经写进去了向量数据库文件
root@autodl-container-24624396c7-b5f6a2a8:~/autodl-tmp/vctdb# ls -lhtr
total 28K
-rw-r--r-- 1 root root 2.3K Apr 9 13:34 index.pkl
-rw-r--r-- 1 root root 21K Apr 9 13:34 index.faiss
4)调用大模型读取本地向量库
from transformers import AutoTokenizer, AutoModel def llm(message): model_path="/root/autodl-tmp/model/chatglm3-6b" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda() model = model.eval() response, history = model.chat(tokenizer, message, history=[]) return response; PROMPT_TEMPLATE = """已知信息: {context} 根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}""" while True: query = input("请输入问题:") context = get_template(query) prompt = PROMPT_TEMPLATE.replace("{context}", context).replace("{question}", query) print(f"\nprompt内容:\n{prompt}\n\n") resp = llm(prompt) print(f"大模型输出:{resp}\n\n")
运行报错: You will need to set allow_dangerous_deserialization to True to enable deserialization
解决方式:FAISS.load_local 方法添加参数 allow_dangerous_deserialization=True
@lru_cache(CACHED_VS_NUM) def load_vector_store(): return FAISS.load_local(VS_PATH, embeddings,allow_dangerous_deserialization=True)
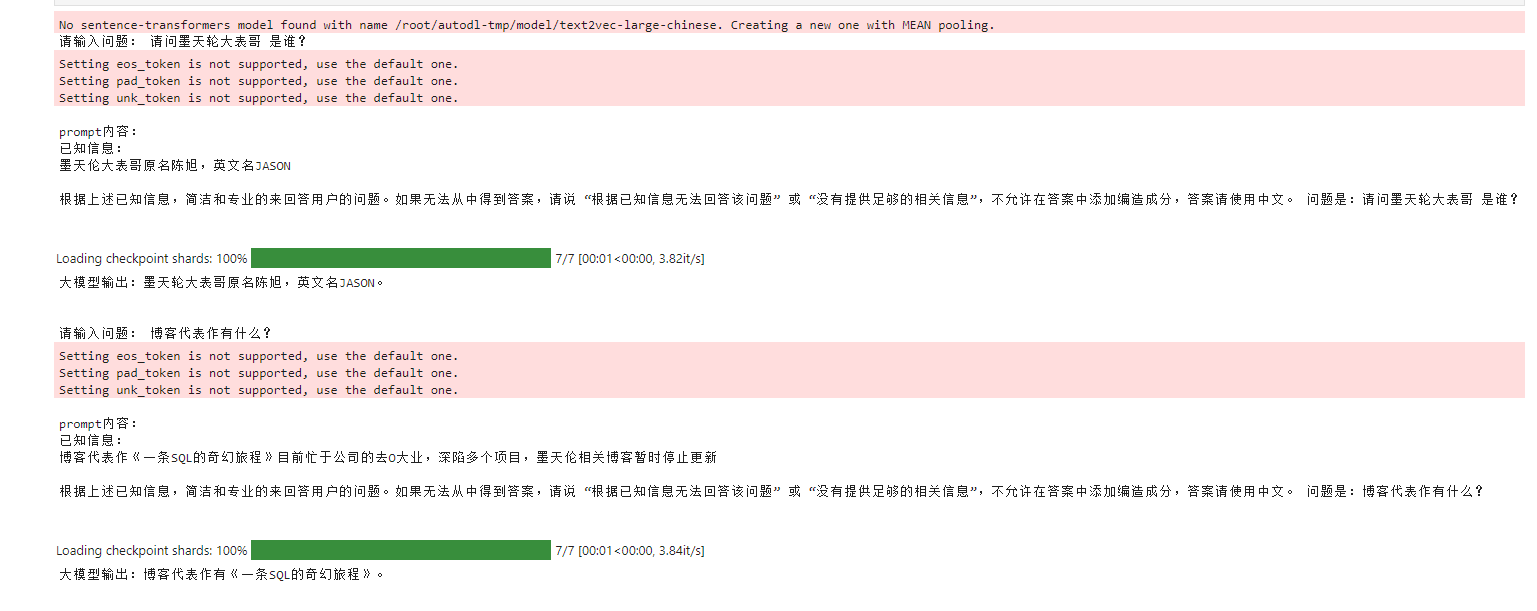
5)最后我们在juper的终端上测试一下:
提问: 请问墨天轮大表哥 是谁?
已知信息:(vector 检索)
墨天伦大表哥原名陈旭,英文名JASON
大模型输出:墨天轮大表哥原名陈旭,英文名JASON
请输入问题: 博客代表作有什么?
prompt内容:
已知信息:(vector 检索)
博客代表作《一条SQL的奇幻旅程》目前忙于公司的去O大业,深陷多个项目,墨天伦相关博客暂时停止更新
大模型输出:博客代表作有《一条SQL的奇幻旅程》。
最后分享AI翻车的花絮:
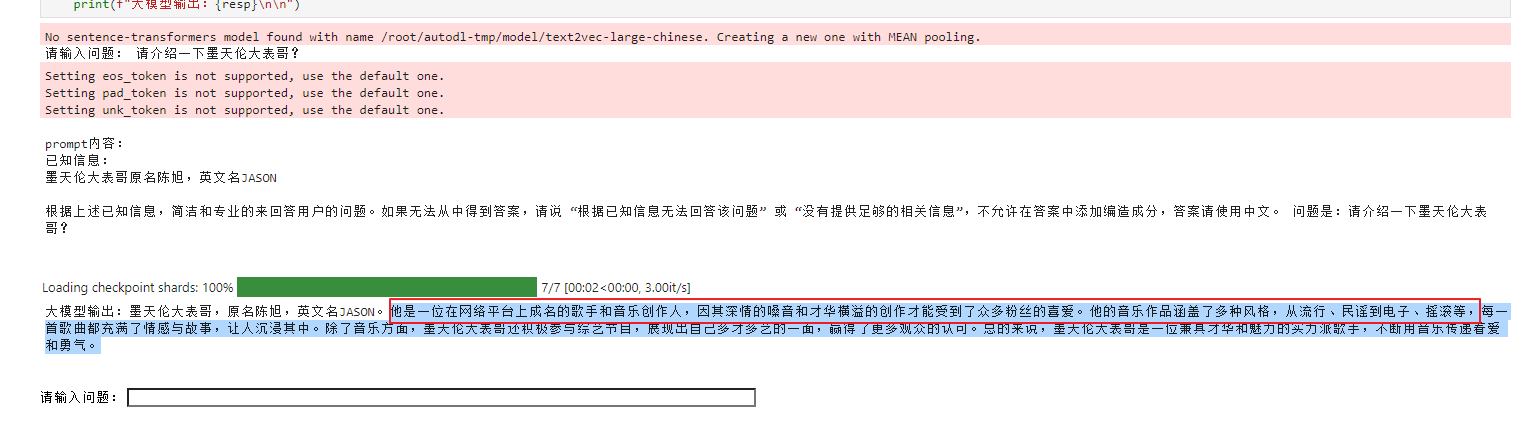
Have a fun 🙂 !
