





DuckDB 是近期非常火的一款 AP 数据库,其独特的定位很有趣。甚至有数据库产品考虑将其纳入进来,作为分析能力的扩展。本文就针对这一数据库做个小评测。
1).DuckDB 产生背景
DuckDB 是一个 In-Process 的 OLAP 数据库,可以理解为 AP 版本的 SQLite,但其底层是列式存储。2019 年 SIGMOD 有一篇 Demo 论文介绍 DuckDB:an embedded analytical database。随着单机内存的变大,大部分 OLTP 数据库都能在内存中放得下,而很多 OLAP 也有在单机就能搞定的趋势。单台服务器的内存很容易达到 TB,加上 SSD,搞个几十甚至上百 TB 很容易。DuckDB 就是为了填补这个空白而生的。
2).DuckDB 开源情况
DuckDB 采用 MIT 协议开源,是荷兰 CWI 数据库组的一个项目,学术气息比较浓厚,项目的组织很有教科书的感觉,架构很清晰,所以非常适合阅读学习。我从 OSS Insight 拉个一个 Star 数对比,可以看到 DuckDB 发展非常迅速。

3).DuckDB 特点
它是免费的开源软件,因此任何人都可以使用和修改代码。 它是嵌入式的,这意味着DBMS(数据库管理系统)与使用它的应用程序在同一进程中运行。这使得它快速且易于使用。 它针对数据分析和OLAP(在线分析处理)进行了优化,而不仅仅是像典型数据库那样只针对事务数据。这意味着数据按列而不是行组织以优化聚合和分析。 它支持标准SQL,因此可以在数据上运行查询、聚合、连接和其他SQL函数。 它在进程中运行,即在应用程序本身内运行,而不是作为单独的进程运行。这消除了进程间通信的开销。 与SQLite一样,它是一个简单的、基于文件的数据库,因此不需要单独安装服务器。只需将库包含在应用程序中即可。
4).DuckDB 优点
DuckDB 易于安装、部署和使用。没有需要配置的服务器,可在应用程序内部嵌入运行,这使得它易于集成到不同编程语言环境中。
DuckDB 尽管它很简单,但DuckDB具有丰富的功能集。它支持完整的SQL标准、事务、二级索引,并且与流行的数据分析编程语言如 Python 和 R 集成良好。
DuckDB 是免费的,任何人都可以使用和修改它,这降低了开发人员和数据分析师采用它的门槛。
DuckDB 兼容性很好,几乎无依赖性,甚至可在浏览器中运行。
DuckDB 具有灵活的扩展机制,这对于直接从 CSV、JSON、Parquet、MySQL 或直接从 S3 读取数据特别重要,能够大大提高开发人员的体验。
DuckDB 可提供数据超出内存限制但小于磁盘容量规模下的工作负载,这样分析工作可通过 "便宜"的硬件来完成。
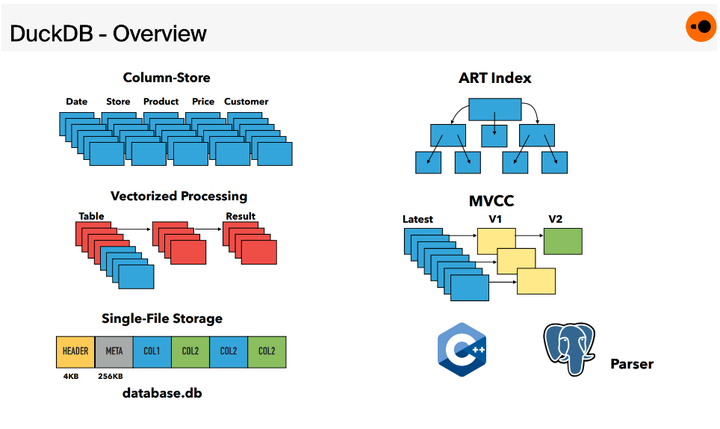
DuckDB 数据库可分为多个组件:Parser、Logical Planner、Optimizer、Physical Planner、Execution Engine、Transaction and Storage Managers。
1).Parser
DuckDB SQL Parser 源自 Postgres SQL Parser。
2).Logical Planner
包含了两个过程 binder、plan generator。前者是解析所有引用的 schema 中的对象(如 table 或 view)的表达式,将其与列名和类型匹配。后者将 binder 生成的 AST 转换为由基本 logical query 查询运算符组成的树,就得到了一颗 type-resolved logical query plan。
3).Optimizer
优化器部分,会采用多种优化手段对 logical query plan 进行优化,最终生成 physical plan。例如,其内置一组 rewrite rules 来简化 expression tree,例如执行公共子表达式消除和常量折叠。针对表关联,会使用动态规划进行 join order 的优化,针对复杂的 join graph 会 fallback 到贪心算法会消除所有的 subquery。
4).Execution Engine
DuckDB 最开始采用了基于 Pull-based 的 Vector Volcano 的执行引擎,后来切换到了 Push-based 的 pipelines 执行方法。DuckDB 采用了向量化计算来来加速计算,具有内部实现的多种类型的 vector 以及向量化的 operator。另外出于可移植性原因,没有采用 JIT,因为 JIT引擎依赖于大型编译器库(例如LLVM),具有额外的传递依赖。
5).Transactions
DuckDB 通过 MVCC 提供了 ACID 的特性,实现了HyPer专门针对混合OLAP OLTP系统定制的可串行化MVCC 变种 。该变种立即 in-place 更新数据,并将先前状态存储在单独的 undo buffer 中,以供并发事务和 abort 使用。
6).Persistent Storage
DuckDB 使用面向读取优化的 DataBlocks 存储布局(单个文件)。逻辑表被水平分区为 chunks of columns,并使用轻量级压缩方法压缩成 physical block 。每个块都带有每列的min/max 索引,以便快速确定它们是否与查询相关。此外,每个块还带有每列的轻量级索引,可以进一步限制扫描的值数量。
1).部署安装
DuckDB 提供了非常简单的安装方法,从官网 duckdb.org 直接下载安装解压即可使用。此外,DuckDB 还可以内置在多种开发语言中使用,下文会以 Python 举例说明。
2).启动数据库
[root@hfserver1 soft]# ./duckdb
v0.10.1 4a89d97db8
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
上文提示连接到内存库。默认情况下,DuckDB 是运行在内存数据库中,这意味着创建的任何表都存储在内存中,而不是持久化到磁盘上。可以通过启动命令行参数的方式,将 DuckDB 连接到磁盘上的持久化数据库文件。任何写入该数据库连接的数据都将保存到磁盘文件中,并在重新连接到同一文件时重新加载。
[root@hfserver1 soft]# ls -al *db
-rwxr-xr-x 1 root root 44784232 Mar 18 20:47 duckdb
-rw-r--r-- 1 root root 18886656 Apr 9 16:06 testdb
[root@hfserver1 soft]# ./duckdb testdb
v0.10.1 4a89d97db8
Enter ".help" for usage hints.
D PRAGMA database_list;
┌───────┬─────────┬─────────┐
│ seq │ name │ file │
│ int64 │ varchar │ varchar │
├───────┼─────────┼─────────┤
│ 1080 │ testdb │ testdb │
└───────┴─────────┴─────────┘
3).简单 CRUD
[root@hfserver1 soft]# ./duckdb
v0.10.1 4a89d97db8
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
-- 创建一张表
D create table t1( a int,b int);
-- 查看表
D .tables
t1
-- 插入数据
D insert into t1 values(1,1);
-- 修改输出格式
D .mode table
-- 查看数据
D select * from t1;
+---+---+
| a | b |
+---+---+
| 1 | 1 |
+---+---+
-- 更新数据
D update t1 set b=2 where a=1;
-- 查看数据
D select * from t1;
+---+---+
| a | b |
+---+---+
| 1 | 2 |
+---+---+
-- 查看表结构
D describe t1;
+-------------+-------------+------+-----+---------+-------+
| column_name | column_type | null | key | default | extra |
+-------------+-------------+------+-----+---------+-------+
| a | INTEGER | YES | | | |
| b | INTEGER | YES | | | |
+-------------+-------------+------+-----+---------+-------+
4).数据加载
-- 读取外部数据
D select * from read_csv('tmp.csv');
+----+-------+
| id | name |
+----+-------+
| 1 | user1 |
| 2 | user2 |
| 3 | user3 |
+----+-------+
-- 加载数据到本地
D create table csv_table as select * from read_csv('tmp.csv');
D select count(*) from csv_table;
+--------------+
| count_star() |
+--------------+
| 3 |
+--------------+
-- COPY 复制数据
D COPY csv_table FROM 'tmp.csv';
D select count(*) from csv_table;
+--------------+
| count_star() |
+--------------+
| 6 |
+--------------+
5).应用集成
[root@hfserver1 soft]# pip install duckdb
[root@hfserver1 soft]# cat test.py
import duckdb
con = duckdb.connect("file.db")
con.sql("CREATE TABLE test (i INTEGER)")
con.sql("INSERT INTO test VALUES (42)")
con.table("test").show()
con.close()
[root@hfserver1 soft]# python test.py
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
└───────┘
6).插件扩展
[root@hfserver1 soft]# ./duckdb
v0.10.1 4a89d97db8
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D install mysql;
100% ▕████████████████████████████████████████████████████████████▏
D
-- 加载本地的 MySQL 数据库
D ATTACH 'host=localhost user=root port=3307 database=test' AS mysqldb (TYPE MYSQL);
D use mysqldb;
D show tables;
┌────────────────────┐
│ name │
│ varchar │
├────────────────────┤
│ AA │
│ COMMITTEE │
...
7).性能对比
-- MySQL 环境
mysql> select count(*) from big_emp;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
mysql> show create table big_emp\G;
*************************** 1. row ***************************
Table: big_emp
Create Table: CREATE TABLE `big_emp` (
`empno` int NOT NULL,
`ename` varchar(30) DEFAULT NULL,
`job` varchar(9) DEFAULT NULL,
`mgr` int DEFAULT NULL,
`hiredate` date DEFAULT NULL,
`sal` int DEFAULT NULL,
`comm` int DEFAULT NULL,
`deptno` int DEFAULT NULL,
PRIMARY KEY (`empno`),
KEY `fk_deptno` (`deptno`),
KEY `idx_sal` (`sal`),
CONSTRAINT `fk_deptno1` FOREIGN KEY (`deptno`) REFERENCES `big_dept` (`deptno`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
mysql> select * from big_emp limit 3;
+-------+--------+-------+-------+------------+-------+------+---------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+-------+--------+-------+-------+------------+-------+------+--------+
| 1 | user1 | job | 1 | 2000-01-01 | 1 | 1 | 925 |
| 2 | user2 | job | 1 | 2000-01-01 | 1 | 1 | 594 |
| 3 | user3 | job | 1 | 2000-01-01 | 1 | 1 | 307 |
+-------+--------+-------+------+-------------+-------+------+---------+
-- 构建 DuckDB 环境
[root@hfserver1 soft]# ./duckdb testdb
v0.10.1 4a89d97db8
Enter ".help" for usage hints.
D ATTACH 'host=localhost user=root port=3307 database=test' AS mysqldb (TYPE MYSQL);
D create table big_emp as select * from mysqldb.big_emp;
100%
-- 查询对比
[root@hfserver1 soft]# time mysql -e "select deptno,count(*) from big_emp group by deptno" test
real 0m0.192s
user 0m0.014s
sys 0m0.000s
[root@hfserver1 soft]# time ./duckdb testdb -c "select deptno,count(*) from big_emp group by deptno"
real 0m0.015s
user 0m0.010s
sys 0m0.009s
8).参数管理
-- 查看参数
D select name,value from duckdb_settings();
+-----------------------------------+-------------------------------------------+
| ame | value |
+-----------------------------------+-------------------------------------------+
| access_mode | automatic |
| allow_persistent_secrets | true |
| checkpoint_threshold | 16.0 MiB |
| debug_checkpoint_abort | none |
| debug_force_external | false |
| debug_force_no_cross_product | false |
...
| Calendar | gregorian |
+-----------------------------------+-------------------------------------------+
-- 修改参数
D set threads=10;
-- 查看单个参数
D SELECT current_setting('threads') AS threads;
+---------+
| threads |
+---------+
| 10 |
+---------+
9).数据字典
-- information_schema
information_schema.schemata: Database, Catalog and Schema
information_schema.tables: Tables and Views
information_schema.columns: Columns
information_schema.character_sets: Character Sets
information_schema.key_column_usage: Key Column Usage
information_schema.referential_constraints: Referential Constraints
information_schema.table_constraints: Table Constraints
-- catalog function
current_catalog()
Return the name of the currently active catalog. Default is memory.
current_schema()
Return the name of the currently active schema. Default is main.
current_schemas(boolean)
Return list of schemas. Pass a parameter of true to include implicit schemas.
10).Pragma 扩展
PRAGMA 语句是DuckDB从SQLite中采用的SQL扩展。PRAGMA语句可以以与常规SQL语句类似的方式发出。PRAGMA命令可能会改变数据库引擎的内部状态,并可能影响引擎的后续执行或行为。
-- 数据库信息
D PRAGMA database_list;
+------+------+---------------------------------------+
| seq | name | file |
+------+------+---------------------------------------+
| 1080 | file | ...file.db |
+------+------+---------------------------------------+
-- 数据库信息(大小)
D CALL pragma_database_size();
+---------------+---------------+------------+--------------+-------------+-------------+----------+--------------+--------------+
| database_name | database_size | block_size | total_blocks | used_blocks | free_blocks | wal_size | memory_usage | memory_limit |
+---------------+---------------+------------+--------------+-------------+-------------+----------+--------------+--------------+
| file | 512.0 KiB | 262144 | 2 | 2 | 0 | 0 bytes | 256.0 KiB | 25.0 GiB |
+---------------+---------------+------------+--------------+-------------+-------------+----------+--------------+--------------+
-- 所有表信息
D PRAGMA show_tables;
+------+
| name |
+------+
| t1 |
| t2 |
| test |
+------+
-- 表详细信息
D PRAGMA show_tables_expanded;
+----------+--------+------+--------------+--------------------+-----------+
| database | schema | name | column_names | column_types | temporary |
+----------+--------+------+--------------+--------------------+-----------+
| file | main | t1 | [a, b] | [INTEGER, INTEGER] | false |
| file | main | t2 | [a, b] | [INTEGER, INTEGER] | false |
| file | main | test | [i] | [INTEGER] | false |
+----------+--------+------+--------------+--------------------+-----------+
-- 函数信息
D PRAGMA functions;
D PRAGMA functions;
┌────────────┬─────────┬────────────────────────┬─────────┬─────────────┬──────────────┐
│ name │ type │ parameters │ varargs │ return_type │ side_effects │
│ varchar │ varchar │ varchar[] │ varchar │ varchar │ boolean │
├────────────┼─────────┼────────────────────────┼─────────┼─────────────┼──────────────┤
│ !__postfix │ SCALAR │ [INTEGER] │ │ HUGEINT │ false │
│ !~~ │ SCALAR │ [VARCHAR, VARCHAR] │ │ BOOLEAN │ false │
│ !~~* │ SCALAR │ [VARCHAR, VARCHAR] │ │ BOOLEAN │ false │
│ % │ SCALAR │ [SMALLINT, SMALLINT] │ │ SMALLINT │ false │
│ % │ SCALAR │ [UBIGINT, UBIGINT] │ │ UBIGINT │ false │
│ % │ SCALAR │ [UINTEGER, UINTEGER] │ │ UINTEGER │ false │
...
-- 表结构
D PRAGMA table_info('t1');
+-----+------+---------+---------+------------+-------+
| cid | name | type | notnull | dflt_value | pk |
+-----+------+---------+---------+------------+-------+
| 0 | a | INTEGER | false | | false |
| 1 | b | INTEGER | false | | false |
+-----+------+---------+---------+------------+-------+
-- 版本与平台
D PRAGMA version;
+-----------------+------------+
| library_version | source_id |
+-----------------+------------+
| v0.10.1 | 4a89d97db8 |
+-----------------+------------+
D PRAGMA platform;
+---------------+
| platform |
+---------------+
| windows_amd64 |
+---------------+
-- Profiling
PRAGMA enable_profiling;
SET profiling_mode = 'detailed';
SET enable_profiling = 'query_tree'; logical query plan:
SET enable_profiling = 'query_tree_optimizer'; physical query plan:
PRAGMA disable_profiling;
-- Optimizer
PRAGMA disable_optimizer;
PRAGMA enable_optimizer;
-- Storage Info
D PRAGMA storage_info('t1');
+--------------+-------------+-----------+-------------+------------+--------------+-------+-------+--------------+------------------------------------------------------+-------------+------------+----------+--------------+--------------+
| row_group_id | column_name | column_id | column_path | segment_id | segment_type | start | count | compression | stats | has_updates | persistent | block_id | block_offset | segment_info |
+--------------+-------------+-----------+-------------+------------+--------------+-------+-------+--------------+------------------------------------------------------+-------------+------------+----------+--------------+--------------+
| 0 | a | 0 | [0] | 0 | INTEGER | 0 | 3 | Uncompressed | [Min: 1, Max: 3][Has Null: false, Has No Null: true] | false | true | 1 | 0 | |
| 0 | a | 0 | [0, 0] | 0 | VALIDITY | 0 | 3 | Constant | [Has Null: false, Has No Null: true] | false | true | -1 | 0 | |
| 0 | b | 1 | [1] | 0 | INTEGER | 0 | 3 | Uncompressed | [Min: 1, Max: 3][Has Null: false, Has No Null: true] | false | true | 1 | 16 | |
| 0 | b | 1 | [1, 0] | 0 | VALIDITY | 0 | 3 | Constant | [Has Null: false, Has No Null: true] | false | true | -1 | 0 | |
+--------------+-------------+-----------+-------------+------------+--------------+-------+-------+--------------+------------------------------------------------------+-------------+------------+----------+--------------+--------------+
11).性能调优
-- 查看执行计划
D explain select deptno,count(*) from big_emp group by deptno;
┌─────────────────────────────┐
│┌───────────────────────────┐│
││ Physical Plan ││
│└───────────────────────────┘│
└─────────────────────────────┘
┌───────────────────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│__internal_decompress_integ │
│ ral_integer(#0, 1) │
│ #1 │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PERFECT_HASH_GROUP_BY │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ #0 │
│ count_star() │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ deptno │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│__internal_compress_integra │
│ l_usmallint(#0, 1) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ big_emp │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ deptno │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 1000000 │
└───────────────────────────┘
-- 关闭优化器后,再观察看下
D PRAGMA disable_optimizer;
D explain select deptno,count(*) from big_emp group by deptno;
┌─────────────────────────────┐
│┌───────────────────────────┐│
││ Physical Plan ││
│└───────────────────────────┘│
└─────────────────────────────┘
┌───────────────────────────┐
│ HASH_GROUP_BY │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ #0 │
│ count_star() │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ deptno │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ SEQ_SCAN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ big_emp │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ EC: 1000000 │
└───────────────────────────┘
