




这个文章主要是由《Orcle数据库存储管理与性能优化》和IT邦德的文章加上自己的遇到的实际问题领悟写出
1、数据库基础内容
表空间-数据文件-段-区-块
一个表空间由一个或者多个数据文件组成
高水位线和表碎片的示意图
其中被划掉的字代表delete删除,其中 耶 就是后续的insert,只会在末尾增加,而不是填充被删除的字段,这样就会导致数据库在搜寻数据时会浪费很多资源。
我 | 管 | 理 |
|
| 数据库 |
我 |
|
| 很 | 厉 | 害 |
|
| 负 | 责 | Oracle | MySQL |
|
| 也 | 有 | Dm | Guass |
|
|
|
|
| 耶 |
整理碎片后
我 | 管 | 理 | 数据库 |
我 | 很 | 厉 | 害 |
负 | 责 | Oracle | MySQL |
也 | 有 | Dm | Guass |
耶 |
大概是这个意思
2、正式操作
2.1问题描述
服务器Centos7.6 + Oracle 11.2.0.4 + 23年10月最新补丁,数据库表空间使用率34%就报警空间不足,这个问题在以前的文章我写过,但是以前就写了如何解决,但是具体的原理却不太清楚,这次不仅要知其然,还要知其所以然。
2.2处理步骤
还是这套库,每次整理完碎片大概两个月就会报空间不足一次,这次刚过了一个月咱们就处理一下,虽然整理碎片的效果没有那么好,但是也足以说明一些问题
2.2.1首先是检查表空间大小
select a.tablespace_name,
round(a.bytes / 1024 / 1024 / 1024, 0) "sum G",
round((a.bytes - b.bytes) / 1024 / 1024 / 1024, 0) "used G",
round(b.bytes / 1024 / 1024 / 1024, 0) "free G",
round(((a.bytes - b.bytes) / a.bytes) * 100, 2) "used%"
from (select tablespace_name, sum(bytes) bytes
from dba_data_files
group by tablespace_name) a,
(select tablespace_name, sum(bytes) bytes, max(bytes) largest
from dba_free_space
group by tablespace_name) b
where a.tablespace_name = b.tablespace_name
order by ((a.bytes - b.bytes) / a.bytes) desc;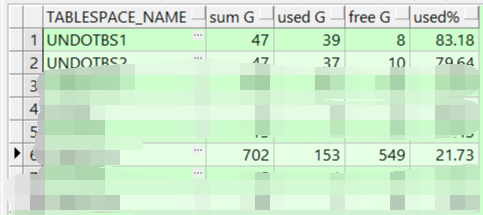
可以看到,702G的表空间只使用了153G,还剩下549G,使用率21.73%
2.2.2检查表空间碎片查询
FSFI的值越小,表空间碎片越多,当小于30%说明碎片很可观了。
SELECT a.tablespace_name,
round(sqrt(MAX(a.blocks) / SUM(a.blocks)) * (100 / sqrt(sqrt(COUNT(a.blocks)))),2) "FSFI(碎片率)"
FROM dba_free_space a,
dba_tablespaces b
WHERE a.tablespace_name = b.tablespace_name
AND b.contents NOT IN ('TEMPORARY',
'UNDO')
GROUP BY a.tablespace_name
ORDER BY 2;
第一行是咱们需要关注的表空间,碎片率高的吓人
2.2.3收集统计信息
exec dbms_stats.gather_schema_stats(ownname => '用户',estimate_percent => 80,method_opt => 'for all columns size repeat',no_invalidate => FALSE,degree => 16, granularity => 'ALL',cascade => TRUE);收集统计信息有利于咱们进行前后比较好的对比
2.2.4整理碎片前的空间统计
select file_id,bytes/1024/1024,count(1) from dba_free_space where tablespace_name='CWDATA1' group by file_id,bytes/1024/1024 order by 3 asc;这个是计算数据文件剩余空间大于1M的情况。这个是大概看一眼心里有谱就行。
这个是大于1M的条数和小于1M条数的统计
select sum(case when bytes/1024/1024 >=1 then 1 else 0 end) "greater then",sum(case when bytes/1024/1024 <1 then 1 else 0 end) "less then" from dba_free_space where tablespace_name='CWDATA1' ;
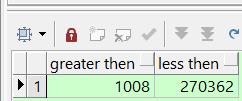
这个是计算大于1M的空间,代表着能使用的空间
select round(sum(bytes/1024/1024),2) from dba_free_space where tablespace_name='CWDATA1' and bytes/1024/1024 >=1;
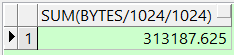
这个是计算小于1M的空间,代表着不能使用的空间
select round(sum(bytes/1024/1024),2) from dba_free_space where tablespace_name='CWDATA1' and bytes/1024/1024 < 1;
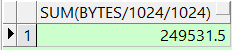
2.2.5查询表的碎片率
round((BLOCKS * 8192 / 1024 / 1024),2) 这个判断条件要根据实际情况来,你说就分给他1M的空间,他再怎么浪费,你整理碎片也没意义。
SELECT TABLE_NAME,
round((BLOCKS * 8192 / 1024 / 1024),2) "使用大小M",
round((NUM_ROWS * AVG_ROW_LEN / 1024 / 1024 / 0.9),2) "实际大小M",
round((NUM_ROWS * AVG_ROW_LEN / 1024 / 1024 / 0.9) / (BLOCKS * 8192 / 1024 / 1024),3) * 100 || '%' "实际使用率%"
FROM DBA_TABLES
where blocks > 100
and tablespace_name='表空间'
and (NUM_ROWS * AVG_ROW_LEN / 1024 / 1024 / 0.9) /
(BLOCKS * 8192 / 1024 / 1024) < 0.3
and round((BLOCKS * 8192 / 1024 / 1024),2) > 100
order by 2 desc;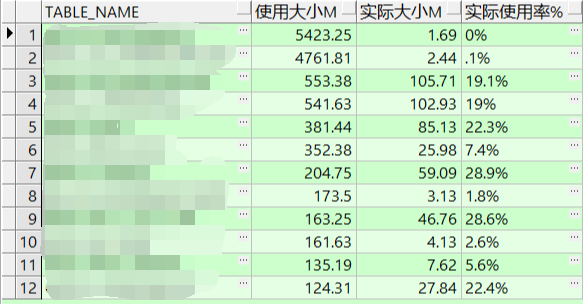
2.2.6 move表
alter table AA move;我这里没加具体的表空间,就代表这个是原表空间移动,不管你是用这个表的用户去操作,还是用系统用户去操作,都会在这个表的原表空间移动,所以不用担心用系统用户move表会移动到system表空间。
我这里之所以选择move因为原因如下
1、这几个表都我都选择了在业务低峰期操作,不会影响业务
2、而且本身表属于小表但是撑大了,不会因为move而花费太多时间
3、就算没有dba权限,也能在本用户下操作,不涉及服务器
2.2.7 重建失效的索引
select 'alter index ' || owner || '.' || INDEX_NAME || ' rebuild ONLINE PARALLEL 6;'
from dba_indexes
where
--owner ='用户' and
status = 'UNUSABLE';2.2.8 再次收集这些具体表的统计信息
exec DBMS_STATS.GATHER_TABLE_STATS(OWNNAME => '用户',TABNAME => '表',ESTIMATE_PERCENT => 100,METHOD_OPT => 'for all columns size repeat',no_invalidate => FALSE,DEGREE => 8,GRANULARITY => 'ALL',CASCADE => TRUE);
查询数据文件分区1M的区,这个是条数
select sum(case when bytes/1024/1024 >=1 then 1 else 0 end) "greater then",sum(case when bytes/1024/1024 <1 then 1 else 0 end) "less then" from dba_free_space where tablespace_name='表空间' ;操作前
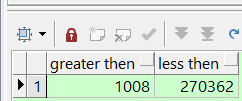
操作后
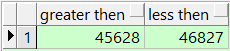
你可以发现大于1M的空间大大增多了,小于1M的空间大大减少了
这个是计算大于1M的空间
select round(sum(bytes/1024/1024),2) from dba_free_space where tablespace_name='表空间' and bytes/1024/1024 >=1;操作前
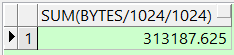
操作后
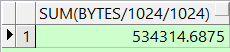
适用空间也增大了
这个是计算小于1M的空间
select round(sum(bytes/1024/1024),2) from dba_free_space where tablespace_name='表空间' and bytes/1024/1024 < 1;操作前
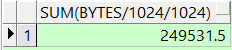
操作后
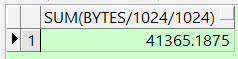
小于1M的空间也减少了
3、领导问答
领导:为什么表空间剩余这么多还报警了?
我:因为剩余空间多,但是剩余空间中没有连续且空闲的1M空间了,数据库中的区最小是1M,不满足这个条件,看着剩余空间大,但是都是不能用的。
领导:为什么会发生你说的这种情况?
我:因为这个项目会有大量的增删,这个增删会导致这样的情况,在表中删除的数据的空间会一直空着,而新增添的数据会在末尾一直添加,就导致了这个情况。
领导:为什么其他项目也会有大量的增删,就没有这样的报警?
我:爆发问题的这个项目是因为数据库在alter报警日志的确出了ORA报警,说明的确发生了这种切碎的数据情况,也表示很严重,具体为什么其他项目没有,而这个项目没有,需要和开发沟通才能了解。而且我也积极协助了这个项目的其他数据库,也多多少少发现了这个问题,他们是通过大量扩容表空间,然后定期导出导入解决的。
领导:你是怎么解决的?
我:我以前是通过定期用数据泵解决,但是这个方式需要停业务,而且重启应用也需要别人的配合,非常浪费人力和精力。再根据我的调查发现,涉及的这些表终归是少数,shrink太浪费时间,也容易发生行锁、CATS(create table as select ...)在这个表拥有默认值的情况不会创建,容易丢数据、而数据泵停业务时间较长,根据和实施沟通发现,这些问题表平常不会有大动作,适合中午或者晚上解决,解决时间也会在15分钟以内。
领导:有没有自动定期解决的办法?
我:有,我想用存储过程,但是编写不太成功。
领导:你怎么证明你做的这些有效果了?
我:经过整理完后,在一个半月的时间以内不会再报错,这个是事实证明的。其他的我也在做之前进行了截图前后对比,图如上。
领导:好的。
以上是问题爆发后,领导和我的对话,这几行对话是我一直测试验证最后得出来的,具体的证据也是让我找了很久,感谢邦德老师的博客。
