





关注我们, 一起成长!
复制


1.Strom 反压机制
1.1 Storm 1.0 以前的反压机制
1.2 Storm Automatic Backpressure
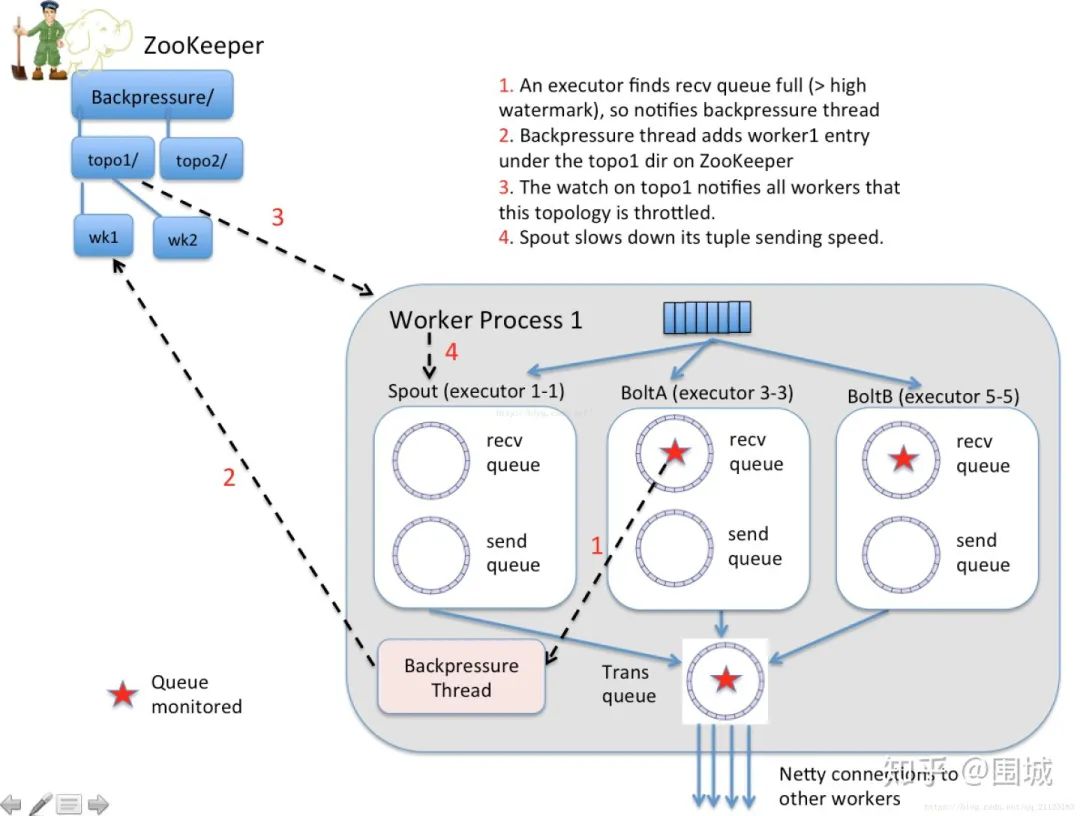
2. JStorm 反压机制
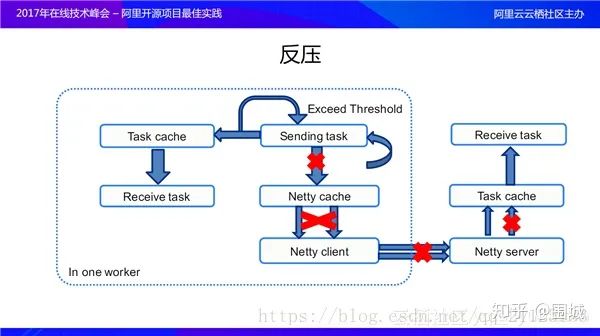
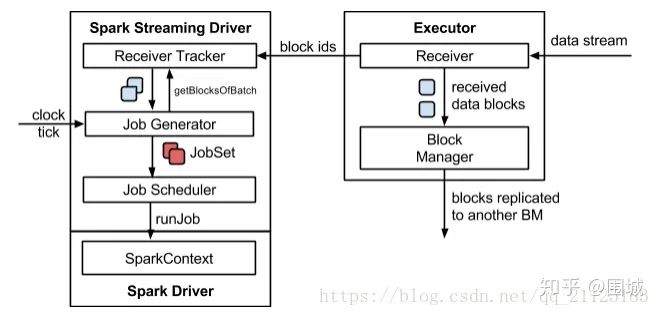
3. SparkStreaming 反压机制
3.1 为什么引入反压机制Backpressure
3.2 反压机制Backpressure
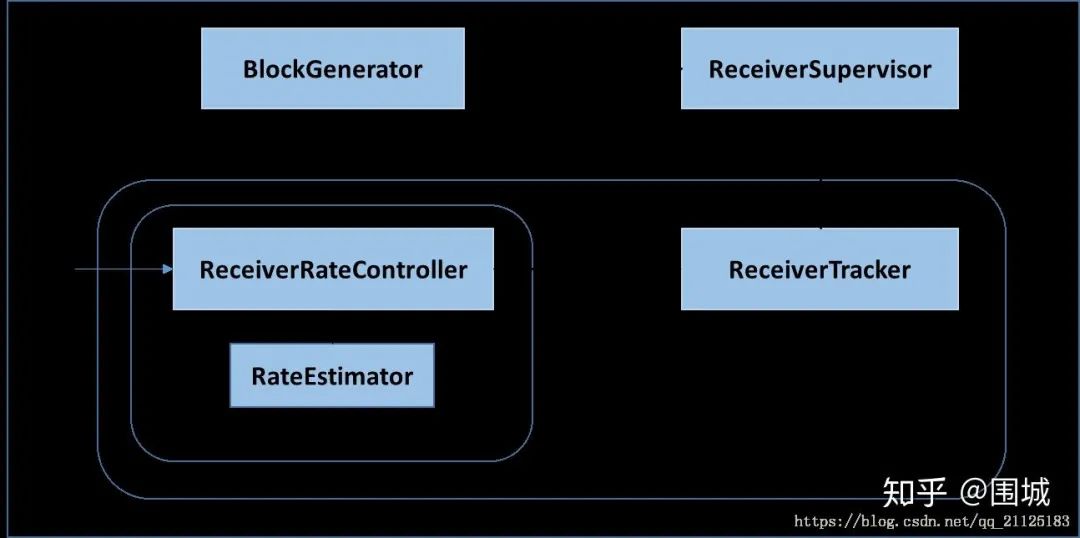
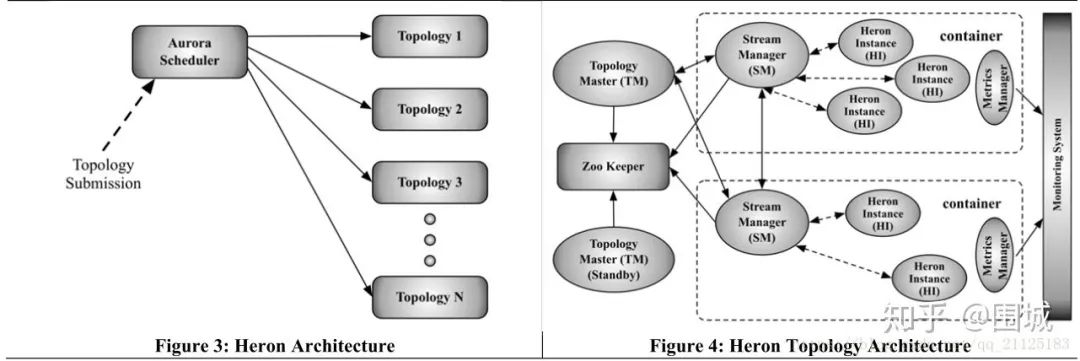
4. Heron 反压机制
5. Flink 反压机制
5.1 Flink 网络传输中的内存管理
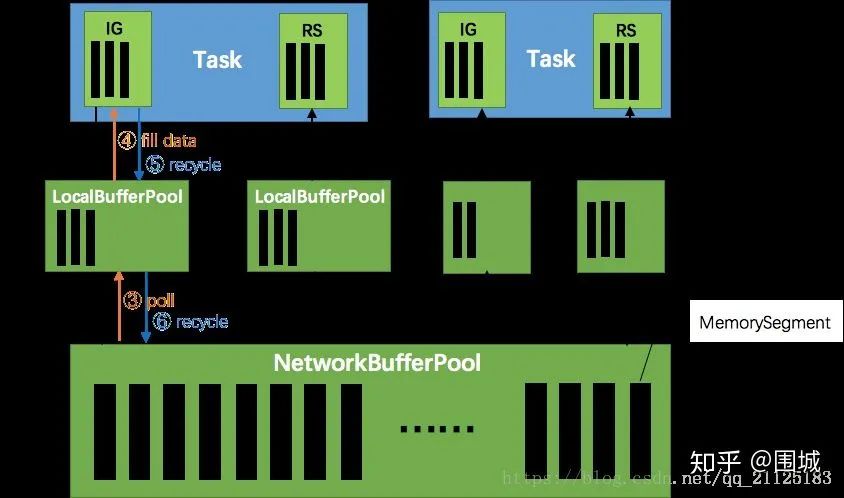
TaskManager(TM)在启动时,会先初始化NetworkEnvironment对象,TM 中所有与网络相关的东西都由该类来管理(如 Netty 连接),其中就包括NetworkBufferPool。根据配置,Flink 会在 NetworkBufferPool 中生成一定数量(默认2048个)的内存块 MemorySegment(关于 Flink 的内存管理,后续文章会详细谈到),内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共享的,每个 TM 只会实例化一个。 Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG)和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment(内存块)数量。IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存块数量与 RP 中的 ResultSubpartition 数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用起那部分闲置的内存块。 在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中,InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的②)并交给 InputChannel 填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者 NetworkBufferPool 也没有可用内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。 当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注册的 Task 导致该池子容量变小),则LocalBufferPool会将该内存块回收给 NetworkBufferPool(上图中的⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
5.2 Flink 反压机制
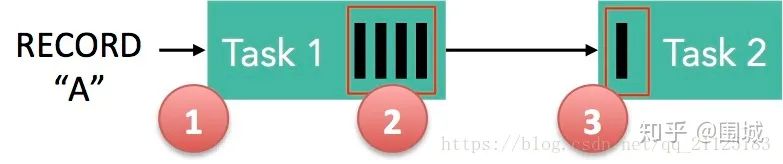
记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程) 记录被序列化到 buffer 中。 该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录。
本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。 远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制来保证不往网络中写入太多数据(后面会说)。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
5.3 反压实验
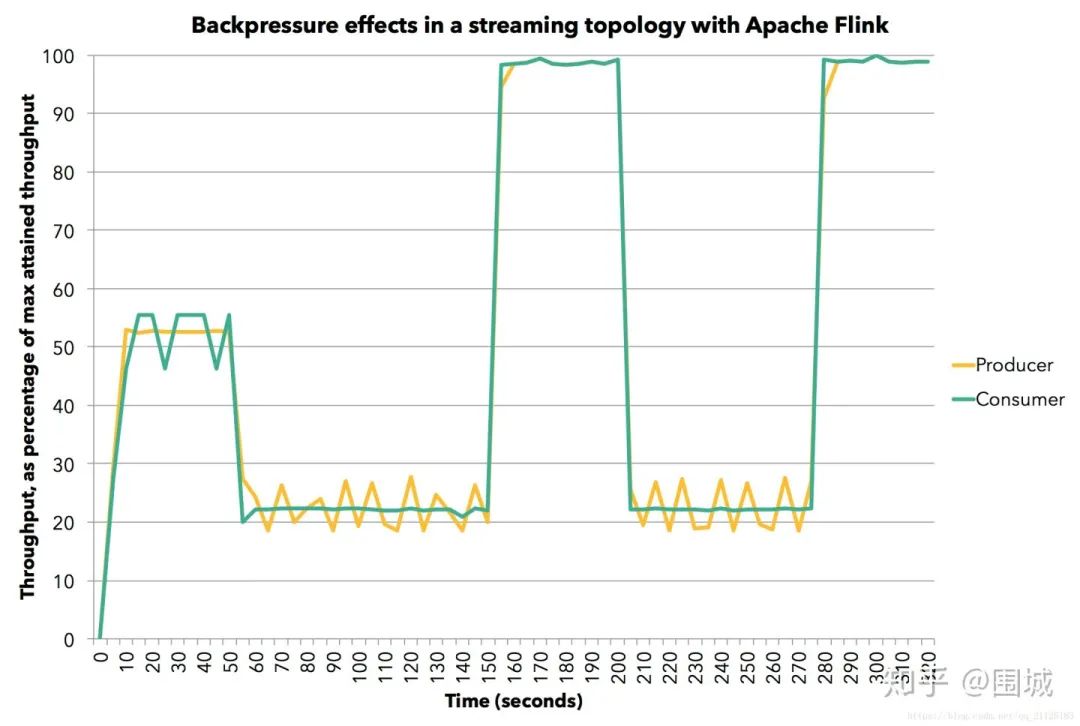
5.4 Flink 反压监控
LocalBufferPool申请内存块上。那么这时候,该 Task 的 stack trace 就会长下面这样:
java.lang.Object.wait(Native Method)o.a.f.[...].LocalBufferPool.requestBuffer(LocalBufferPool.java:163)o.a.f.[...].LocalBufferPool.requestBufferBlocking(LocalBufferPool.java:133) <--- BLOCKING request[...]复制
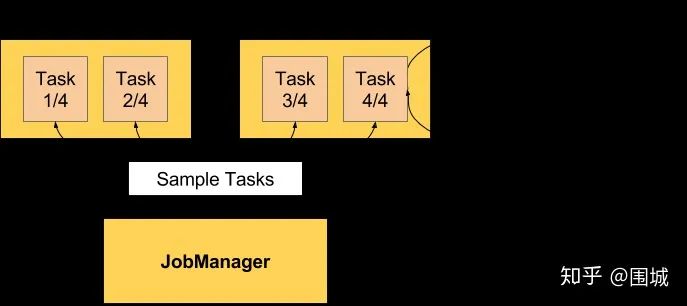
TriggerStackTraceSample消息。默认情况下,TaskManager 会触发100次 stack trace 采样,每次间隔 50ms(也就是说一次反压检测至少要等待5秒钟)。并将这 100 次采样的结果返回给 JobManager,由 JobManager 来计算反压比率(反压出现的次数/采样的次数),最终展现在 UI 上。UI 刷新的默认周期是一分钟,目的是不对 TaskManager 造成太大的负担。
总结

 期待与大佬技术交流、思想碰撞!点个关注,交个朋友↓
期待与大佬技术交流、思想碰撞!点个关注,交个朋友↓

高频面试必问 | MySQL为什么要使用B+树索引?

Flume+Kafka双剑合璧玩转大数据平台日志采集

ClickHouse必知必会 | ClickHouse深度解析

博主微信(渣渣空)
文章转载自实时数仓Flink,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1249次阅读
2025-04-27 16:53:22
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
729次阅读
2025-04-30 15:24:06
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
591次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
506次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
477次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
470次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
361次阅读
2025-04-18 10:01:22
给准备学习国产数据库的朋友几点建议
白鳝的洞穴
282次阅读
2025-05-07 10:06:14
XCOPS广州站:从开源自研之争到AI驱动的下一代数据库架构探索
韩锋频道
275次阅读
2025-04-29 10:35:54
国产数据库图谱又上新|82篇精选内容全览达梦数据库
墨天轮编辑部
275次阅读
2025-04-23 12:04:21
