




作者简介
Paul Ramsey
crunchydata工程师
译者简介
王志斌
PostgreSQL爱好者
校对者简介
崔鹏
PostgreSQL爱好者
对点进行聚类是地理空间数据分析中的常见任务,PostGIS提供了几个用于聚类的函数。
lST_ClusterDBSCAN
lST_ClusterKMeans
lST_ClusterIntersectingWin
lST_ClusterWithinWin
我们之前看过流行的DBSCAN空间聚类算法,它基于空间密度构建聚类。
本文探讨了PostGIS中ST_ClusterKMeans函数的特性。K均值聚类目前很流行,是一种将高维LLM嵌入进行分组的方法,但在低维度中进行空间聚类也很有用。
ST_ClusterKMeans将对二维和三维数据进行聚类,并在提供了点的“measure”维度中提供权重时执行加权聚类。
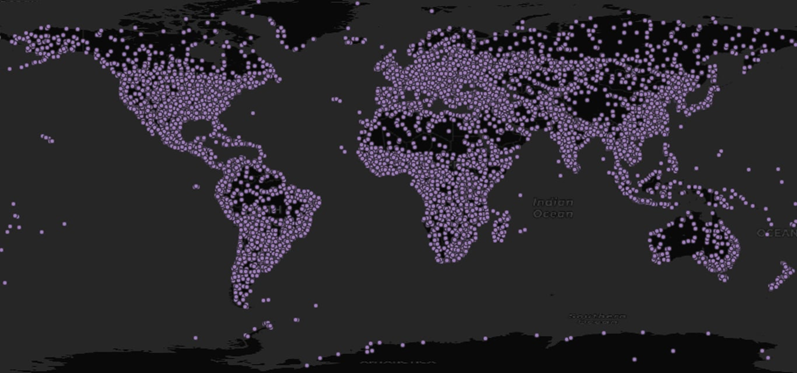
一些要进行聚类的点
为了尝试K-means聚类,我们需要一些要进行聚类的点。在这种情况下,我们可以使用Natural Earth提供的1:10M人口聚居地数据集。下载GIS文件并加载到您的数据库中,在本例中使用ogr2ogr。
ogr2ogr \-f PostgreSQL \-nln popplaces \-lco GEOMETRY_NAME=geom \PG:'dbname=postgres' \ne_10m_populated_places_simple.shp
平面聚类
在2D空间中进行简单的聚类如下,使用10作为聚类的数量:
CREATE TABLE popplaces_geographic ASSELECT geom, pop_max, name,ST_ClusterKMeans(geom, 10) OVER () AS clusterFROM popplaces;
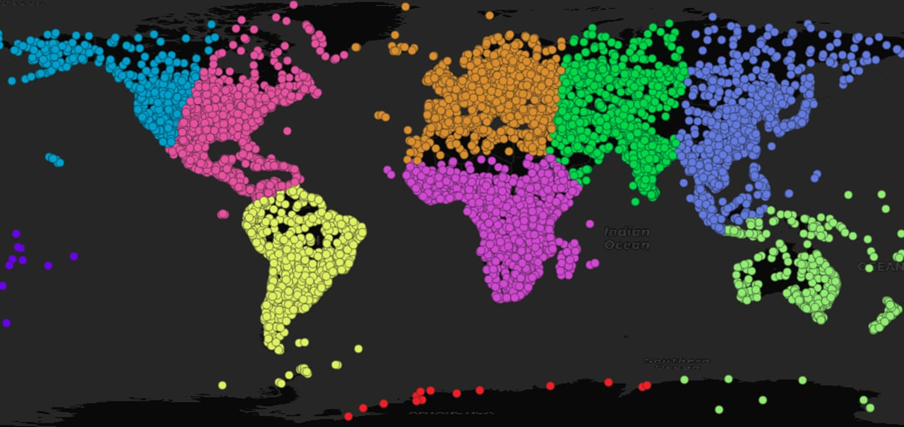
请注意,俄罗斯的部分地区与阿拉斯加聚类在一起,大洋洲被分割开。这是因为我们将点的经度/纬度坐标视为在一个平面上,所以阿拉斯加与西伯利亚相距很远。对于局限于小区域的数据,像在日期变更线处分割的影响并不重要,但对于我们的全球示例,这很重要。幸运的是,有一种方法可以解决这个问题。
地心聚类
我们可以使用ST_Transform 将原始数据的经度/纬度坐标转换为地心坐标系。"地心"坐标系是一种以地球中心为原点,位置由它们与该中心的 X、Y 和 Z 距离来定义的坐标系。
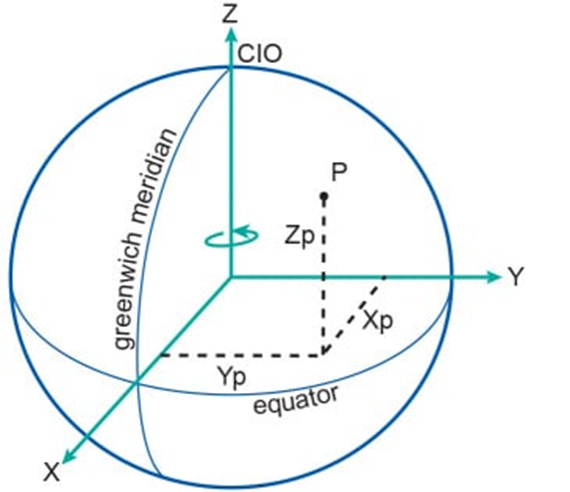
在地心坐标系中,日期线两侧的位置在空间中仍然非常接近,因此它非常适用于在不考虑极点或日期线影响的情况下对全球数据进行聚类。对于这个示例,我们将使用EPSG:4978作为我们的地心坐标系。
以下是纽约的坐标,转换为地心坐标系:
SELECT ST_AsText(ST_Transform(ST_PointZ(74.0060, 40.7128, 0, 4326), 4978), 1);POINT Z (1333998.5 4654044.8 4138300.2)
以下是在地心坐标系中执行的聚类操作。
CREATE TABLE popplaces_geocentric ASSELECT geom, pop_max, name,ST_ClusterKMeans(ST_Transform(ST_Force3D(geom),4978),10) OVER () AS clusterFROM popplaces;
结果看起来与平面聚类非常相近 ,但您可以看到一些地方的“整个平面”效果,比如澳大利亚和整个大洋洲的岛屿现在都在一个聚类中,以及西伯利亚和阿拉斯加聚类之间的分界点已经向西移动越过了日期线。
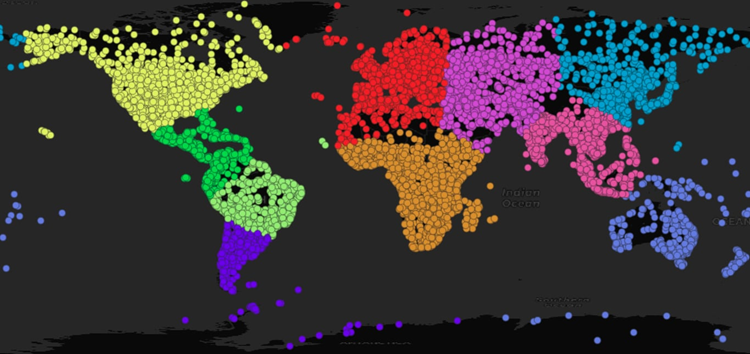
值得注意的是,这个聚类是在三维空间中执行的(因为地心坐标需要 X、Y 和 Z),尽管我们在二维中显示结果。
加权聚类
除了简单的k-means之外,ST_ClusterKMeans还可以进行加权k-means聚类,以使用输入点的“M”维度(第四个坐标)中的额外信息来调整聚类位置。
由于我们有一个“有人居住的地方”数据集,因此在这个示例中使用人口作为权重是有意义的。加权算法要求权重严格为正,因此我们过滤掉了那些非正数的少数记录。
CREATE TABLE popplaces_geocentric_weighted ASSELECT geom, pop_max, name,ST_ClusterKMeans(ST_Force4D(ST_Transform(ST_Force3D(geom), 4978),mvalue => pop_max),10) OVER () AS clusterFROM popplacesWHERE pop_max > 0;
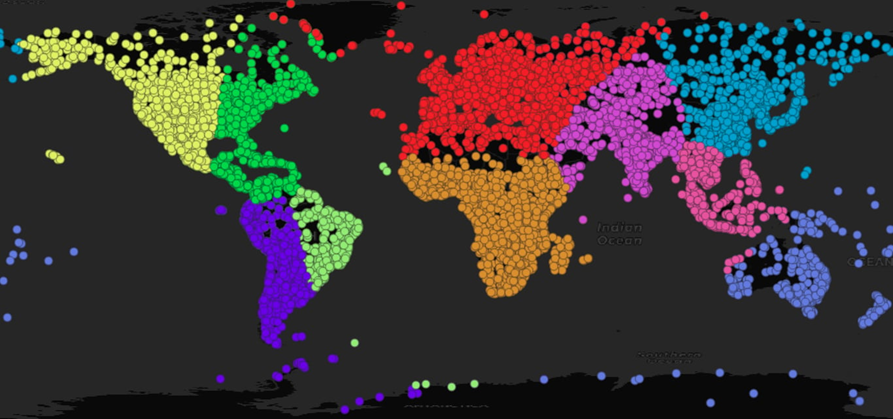
再次强调,差异是微妙的,但请注意印度现在是一个单一的聚类,巴西聚类现在倾向于人口密集的东海岸,以及北美现在被分为东西两部分。
点击文章底部“阅读原文”查看原文内容!





