




本期直播回顾
大数据时代,厂商对实时数据分析的诉求越来越强烈,数据分析时效从T+1时效趋向于T+0时效,为了给客户提供极速分析查询能力,华为云数仓GaussDB(DWS)基于流处理框架Flink实现了实时数仓构建。
在本期《GaussDB(DWS)基于Flink的实时数仓构建》的主题直播中,华为云数仓GaussDB(DWS)解决方案专家Eric老师,为您深度解析GaussDB(DWS)+Flink如何增强湖仓增量数据在不同数据模型层之间的实时流动能力,如何为消息数据流提供高性能通用入库能力,又如何构建极致的端到端实时数仓解决方案。

增量计算的背景
随着数智化时代的到来,数据量不断增长,为了充分挖掘数据价值,实时获取数据动态,GaussDB(DWS)通过与流引擎Flink结合,优化ETL Pipeline,从而数据分析时效实现T+0。
Flink是一款开源的流处理框架,它能够实时处理大规模数据流,并具有高可靠性和高性能的特点。Flink支持流式数据处理、批处理和图形处理等多种计算模式,并提供了丰富的API和工具,可以方便地进行数据处理和分析。GaussDB(DWS)与Flink结合构建下一代Stream Warehouse,实现增量计算,可以为用户提供更加全面、高效的数据处理和分析能力。
为什么需要增量计算能力?增量计算能力解决了哪些场景的痛点问题?
高性能场景:一些需要高性能的典型场景如下:
(1)增量数据的实时ETL并更新物化视图,秒级更新;
(2)数据在仓湖之间实时流动能力;
(3)实时流数据不落盘,直达实时大屏。
数据入库场景:Kafka的数据直接入湖
GaussDB(DWS)+Flink实现增量计算的架构设计
GaussDB(DWS)与流引擎结合,实现企业数仓模型的分层、增量化加工,统一批流处理逻辑,一站式支持批、流、交互式、点查等多种场景,简化数据生产线架构复杂度,构建新一代实时增量数仓,满足企业日趋便捷化的数据生产线场景。
三大实时能力 | GaussDB(DWS) | Flink |
实时入出仓 | 提升入库性能,支持Binlog表CDC功能,实现 “流表一体” | GaussDB(DWS)对接Flink元数据,GaussDB(DWS)可以作为Flink的源表、结果表 |
实时增量加工 | 支持基于数据流表达的增量加工 | 复杂SQL下推GaussDB(DWS),流表关联,多流关联等 |
实时查询 | 支持数据高效点查 | GaussDB(DWS)对接Flink元数据,GaussDB(DWS)可以作为Flink的维表,支持维表点查 |
如下图,增量数据可以被流引擎实时地感知捕获到,并运行预置的增量计算任务,然后再写回到数仓的下一层模型里面。通过几次流引擎的迭代,使得贴源层的增量数据能迅速的反映到明细层以及最终的集市层,来支撑实时的BI报表分析、交互式分析等业务场景。
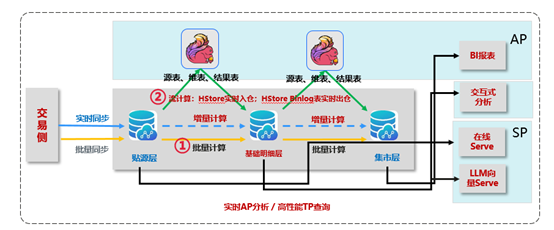
GaussDB(DWS)+Flink增量计算能力图介绍
GaussDB(DWS)结合Flink的能力构建,涵盖以下四大功能:
1. Catalog
打通Flink元数据与湖仓元数据。
-- 映射catalog
create catalog dws
with (
'type' = 'dws',
'base_url' = 'jdbc:gaussdb://****:5432/',
'database' = 'postgres',
'password' = '****',
'username' = '****'
);
2. Source
a. 仓内表通过Binlog将增量数据暴露出来让Flink及时感知,从而驱动实时增量数据运算任务的开始。
-create table transaction_fact (
order_id INT,
product_id INT,
category_id INT,
amount DOUBLE,
customer_id INT,
transaction_date DATE
) with (
'connector' = 'dws’,
‘tableName’ = ‘ transaction_fact’,//hstore表
‘binlog' = 'true’,
‘binlogSlotName' = 'slot',
'url' = 'jdbc:postgresql://****:5432/dws’,
'username' ='****',
'password' = '****'
);
b. Source connector算子,可以将一些条件下推至仓中完成点查任务。
-- 创建信息表
create table information (
category_id INT,
desc STRING
) with (
'connector' = 'dws',
'url' = 'jdbc:gaussdb://****:5432/',
'database' = 'postgres',
'password' = '****',
'username' = '****'
);
3. Sink
Sink connector算子可以将job中的数据写回数仓中。
-- 创建历史商品消费汇总表
create table historical_product_summary (
customer_name STRING,
product_name STRING,
category_name STRING,
total_amount DECIMAL
) with (
'connector' = 'dws’,
'tableName' = 'summary',
'url' = 'jdbc:postgresql://****:5432/dws’,
'username' ='****',
'password' = '****'
);
4. 流维
流维算子提供了流数据关联维表的能力。
-- 创建维度表,以商品维度表为例
create table product_dimension (
product_id INT PRIMARY KEY,
product_name STRING,
category_id INT
) WITH (
'connector' = 'dws',
'url' = 'jdbc:postgresql://****:5432/dws',
'tableName' = 'schema.product_dimension',
'username' ='****',
'password' = '****'
);
GaussDB(DWS)结合Flink的非功能性构建:
CKPT建设
每个算子implements flink的指定接口,将计算中间结果持久化下去,并做到功能幂等,即可接入flink灾难恢复处理能力,做到job的端到端数据exactly once。
public class DwsBinlogSourceFunction extends RichSourceFunction<RowData>
implements CheckpointListener, CheckpointedFunction {
@Override
public void notifyCheckpointComplete(long checkpointId) throws Exception {
dwsBaseBinlogSourceFunction.notifyCheckpointComplete(checkpointId);
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
dwsBaseBinlogSourceFunction.snapshotState(context, getBinlogSlotName());
}
}
public class DwsGenericSinkFunction<T> extends RichSinkFunction<T>
implements CheckpointListener, CheckpointedFunction {
@Override
public void notifyCheckpointComplete(long checkpointId) throws Exception {
client.flush();
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
client.flush();
}
}
生态工具streamer介绍
为了便于用户一键操作数据入库,GaussDB(DWS)研发了streamer生态工具,用户不再需要自己写SQL,只需要在IDE中进行操作。
操作步骤如下:
第一步:配置kafka及数仓表。
# Configurations for DWS Flink streamer
# Kafka
Kafka .bootstrap.servers=x.x.x.x:9092
Kafka .topic=xxxx
Kafka .group.id=xxxx
# Flink
flink.checkpoint-interval=2000
# DWS
dws.url=jdbc:postgresql://x.x.x.x:5432/xxxx
dws.username=xxxx
dws.password=xxxx
dws.table-name=schema.table
第二步:创建POJO类分别对应kafka消息体及数仓表行数据。
-- 创建source的POJO,以商品维度表为例
public class ProductDimension {
private int productId;
private String productName;
}
-- 创建sink表的POJO,历史商品消费汇总表
public class HistoricalProductSummary {
private String customerName ;
private String productName;
private String CategoryName;
private BigDecimal totalAmount ;
}
第三步:编写自定义算子,实现自定义Mapping功能。系统提供默认1对1 Mapping算子,可直接使用。
public class DirectMappingOperation<T, R> implements OperatorFunction<T, R> {
@Override
public void convert(T source, R sink) throws DwsClientException {
try {
BeanUtils.copyProperties(sink, source);
} catch (IllegalAccessException | InvocationTargetException e) {
throw new DwsClientException(ExceptionCode.INTERNAL_ERROR, "Failed to convert data from Source to Sink.", e);
}
}
}
本期分享到此结束,更多关于GaussDB(DWS)产品技术解析、数仓产品新特性的介绍,请关注GaussDB(DWS)开发者平台,GaussDB(DWS)开发者平台为开发者们提供最新、最全的信息咨询,包括精品技术文章、最佳实践、直播集锦、热门活动、海量案例、智能机器人。让您学+练+玩一站式体验GaussDB(DWS)。


往期精彩回顾

 戳“阅读原文”,了解更多GaussDB(DWS)开发者平台。
戳“阅读原文”,了解更多GaussDB(DWS)开发者平台。
