




“Vae他有一些烦恼
”
反正现在的年轻人
都有许多烦恼
那么多要思考
那么多要寻找
诱惑太多 不坚定就犯错了
哦哦,不对,不是这个Vae,也不是uae~

是接下来出场的VAE~
对比AE,引出VAE
之前介绍了自编码器(AE
)的原理(传送门),当时讲到自编码器并不具有真正的生成能力,以图像为例来说,它只能将输入的图像编码成隐向量,然后将作为解码器的输入,得到输出图像。如果我们尝试将与的shape
一致的"随机特征表示"输入解码器,那么得到的将是毫无意义的噪声图像。
变分自编码器(VAE
)突破了这一限制!
先给出结论:在VAE中,只要随机特征表示(这里也将这些特征表示记作)是从某些分布,如标准正态分布中采样得到的,那么将输入解码器之后可以得到与训练集图像类似但不同于训练集中任何一张图像的新图像。
比如,训练集是手写数字图像,那么在训练完成后,将从标准正态分布中采样得到的输入解码器,可以得到一些新的手写数字图像。
以上所说的特征表示,被称为隐向量(latent vector
)。
VAE究竟是如何做到这一点的呢?且往下看。
VAE的结构
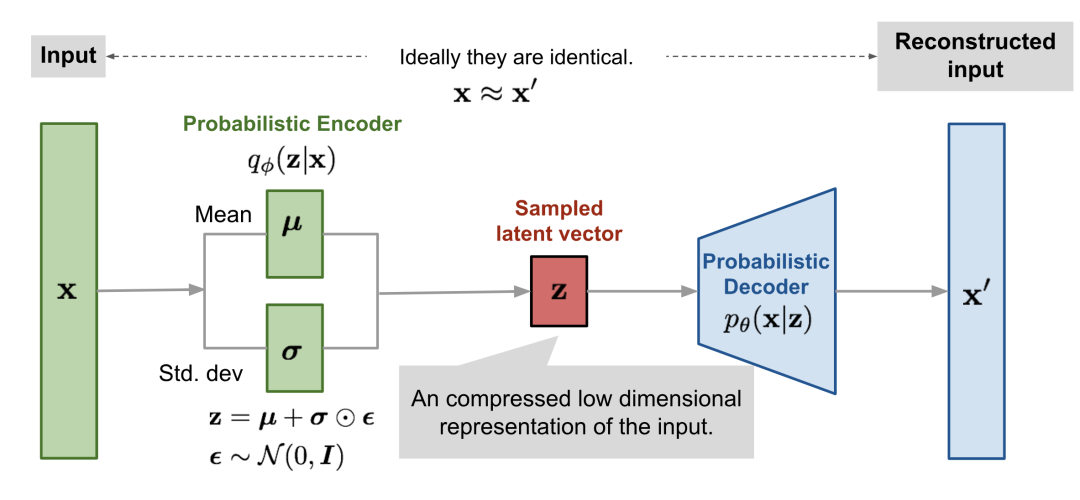
变分自编码器由两部分组成:编码器和解码器。
上图中,从输入到之间的部分(绿色)是编码器,从到输出之间的部分(蓝色)是解码器。
变分自编码器的解码器部分和自编码器相似,但编码器部分是有差异的。具体来说,变分自编码器的编码器并不是直接将输入映射到,而是先将映射为一组组的(均值,标准差),然后由一组组的(均值,标准差)变换得到的各个分量,并组合得到最终的。
上面说的变换,具体来说是,其中的和代表均值和标准差,由编码器拟合得到,不需要我们手动去解。是服从标准正态分布的。
你可能会疑惑,为什么有这么一个变换操作?
原因在于,"采样"这个动作是不可导的,从而无法使用反向传播算法去优化,而变换后得到的是可导的。
这样一来,我们只需从标准正态分布中采样,然后经过变换得到服从均值为,标准差为的正态分布的,再把输入解码器,就能得到期待的输出结果了。
这被称为重参数技巧。
当然,我们也可以直接从标准正态分布中采样一个隐向量,然后输入解码器,得到输出,这就是VAE所谓的生成能力。
损失函数
损失函数有二。
其一为解码器输出的与编码器的输入之间的相似程度,这里用重构损失来衡量,重构损失使用交叉熵;
其二为编码器拟合+变换得到的的分布与标准正态分布之间的距离,这里用KL散度来度量两个分布之间的差异,越小代表分布间差异越小。
我们希望与之间越相似越好,也就是重构损失越小越好;同样,我们希望的分布越接近标准正态分布越好,也就是两者之间的KL散度越小越好。
于是最终的损失函数定义为重构损失与KL散度之和。
使用Pytorch写一个VAE
首先导入相关库:
import torch
import torch.utils.data
from torch import nn, optim
from torch.nn import functional as F
from torchvision.utils import save_image
import torchvision
准备数据集,这里还是使用手写数字数据集,设定训练集的batch_size=128
,测试集的batch_size=32
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_dataset = torchvision.datasets.MNIST(
root="torch_datasets", train=True, transform=transform, download=True
)
test_dataset = torchvision.datasets.MNIST(
root="torch_datasets", train=False, transform=transform, download=True
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=128, shuffle=True, num_workers=4, pin_memory=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=32, shuffle=False, num_workers=4
)
设置常用的一些参数:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
seed = 42
torch.manual_seed(seed)
epochs=20
搭建VAE网络:
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
#编码器
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
#重参数技巧
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
#编码器
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
#前向传播
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
定义损失函数:
def loss_function(recon_x, x, mu, logvar):
#重构损失
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
#这里使用KL散度最终的推导形式:
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
定义训练函数
def train(epoch):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
#每吃掉10个batch打印一次当前进度
if batch_idx % 10 == 0:
#进度条
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item() / len(data)))
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(train_loader.dataset)))
定义测试函数
def test(epoch):
model.eval()
test_loss = 0
with torch.no_grad():
for i, (data, _) in enumerate(test_loader):
data = data.to(device)
recon_batch, mu, logvar = model(data)
test_loss += loss_function(recon_batch, data, mu, logvar).item()
if i == 0:
#测试图片数量为8,不足8则有多少要多少
n = min(data.size(0), 8)
#将n张原图与重构图画在一起(axis默认为0,即上下对应)
comparison = torch.cat([data[:n], recon_batch.view(-1, 1, 28, 28)[:n]])
save_image(comparison.cpu(), 'reconstruction_' + str(epoch) + '.png', nrow=n)
test_loss /= len(test_loader.dataset)
print('====> Test set loss: {:.4f}'.format(test_loss))
最后定义主函数入口:
if __name__ == "__main__":
#实例化一个VAE
model = VAE().to(device)
#定义优化器
optimizer = optim.Adam(model.parameters(), lr=1e-3)
#开始跑代码~
for epoch in range(1, epochs + 1):
#训练
train(epoch)
#测试
test(epoch)
#生成新图像
with torch.no_grad():
#从标准正态分布中采样64个隐向量
sample = torch.randn(64, 20).to(device)
#输入解码器生成64张新的手写数字图像
sample = model.decode(sample).cpu()
#保存图像
save_image(sample.view(64, 1, 28, 28), 'sample_' + str(epoch) + '.png')

训练20个epoch
,每一个epoch
都会产生一张重构图像和一张生成的新图像。以上主函数代码运行完成之后,就得到了20张重构图像与20张生成图像,如下:
这里展示最后一个epoch
对应的图像。
重构图像:
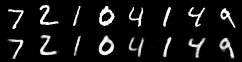
生成图像:

重构图像已经基本能够还原原始图像,只是有些许模糊。
生成图像是训练集中不存在的图像,虽然这些生成图像相比于真实图像来说还有些差距,但基本能够看出手写数字的轮廓,这说明训练的变分自编码器(VAE
)已经学习到了训练集的分布,具备了生成新图像的能力。
参考:
[1][https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html] [2][https://github.com/pytorch/examples/blob/master/vae/main.py] [3][https://spaces.ac.cn/archives/5253]

南极Python交流群已经成立,欢迎扫码加群,如若失效,请在公众号底部菜单栏点击"交流群"入群。



点亮在看吧!

