




减少扫描次数:当使用小表去驱动大表时,数据库引擎需要遍历的记录数会减少,因为它首先处理的是行数较少的表。这意味着在查找匹配项时,对大表的扫描次数会相应减少。
举例说明:
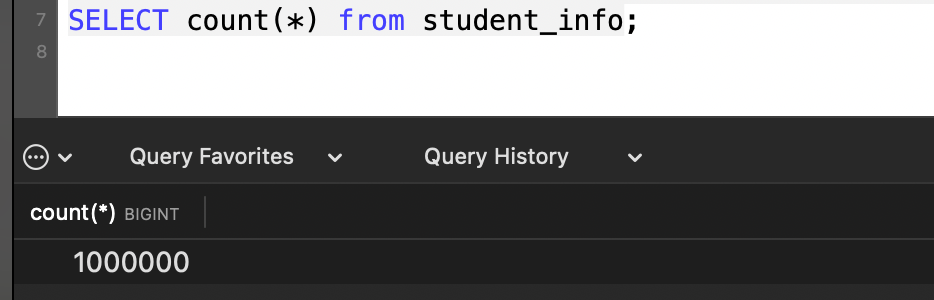
假设我们有两个表:employees(员工表)和sales(销售记录表)。employees表包含公司所有员工的信息,假设有1,000行数据;sales表记录了所有的销售活动,假设有100,000行数据。
现在我们想要查询所有员工及其对应的销售记录总数。这里涉及到一个JOIN操作。
如果我们让sales表(大表)驱动employees表(小表),数据库引擎需要遍历sales表中的每一行,对于每一行销售记录,都去employees表中查找匹配的员工信息。这种情况下,数据库引擎的工作量非常大,因为它需要执行大量的查找操作。
for(int i=1000;.......){
for(int j=5;......){
}
}
相反,如果我们让employees表(小表)驱动sales表(大表),数据库引擎只需要遍历employees表的每一行,然后对于每个员工,去sales表中查找匹配的销售记录。虽然最终还是要处理所有的销售记录,但通过这种方式,数据库引擎可以更有效地利用sales表上的索引来快速定位数据,从而减少查找时间和资源消耗
类似于:
for(int i=5;.......){
for(int j=1000;......){
}
}
SELECT * FROM table WHERE EXISTS(sub_query)
sub_query:子查询语句
SELECT * FROM a WHERE EXISTS(SELECT 1 FROM b WHERE a.`key` = b.`key`)
SELECT * FROM a WHERE a.`key` IN (SELECT b.`key` FROM b)
IN查询步骤如下:
a.执行子查询:首先执行括号内的子查询SELECT b.key FROM b。这一步会扫描表b,并得到所有存在于表b中的key值,形成一个结果集。
b.缓存结果集:将上一步得到的结果集缓存起来。这个结果集包含了所有在表b中可以找到的key值。
c.执行外部查询:然后执行外部查询SELECT * FROM a,但在检索表a的每一行时,会检查每行的key值是否存在于第一步得到的结果集中。
所以:可以推断出:上面的sql中,b表越小越好

 用IN
用IN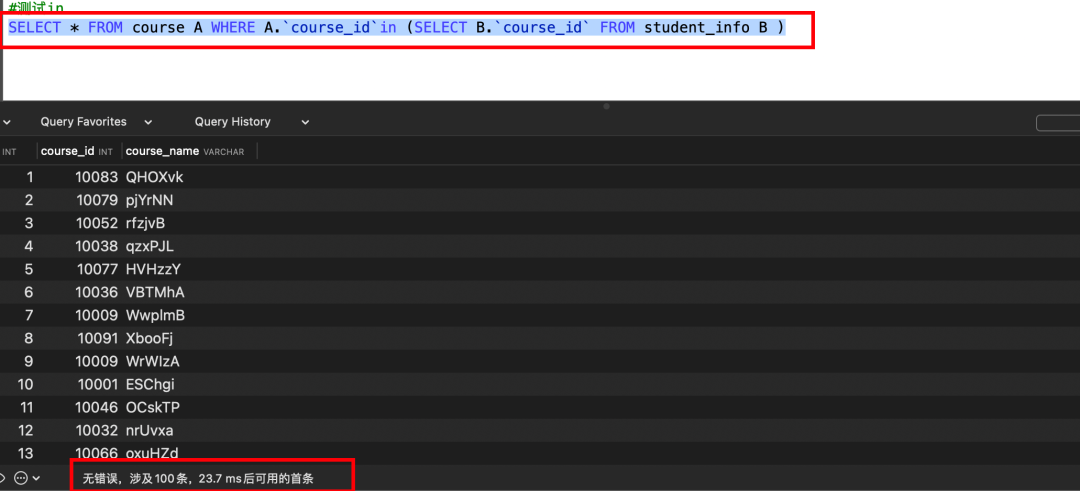
SELECT * FROM course WHERE EXISTS(SELECT 1 FROM student_info WHERE course.`course_id` = student_info.`course_id`)
#创建索引
CREATE INDEX idx_course_id ON course(course_id);
#创建索引
CREATE INDEX idx_course_id ON student_info(course_id);
#优化原则,小表驱动大表
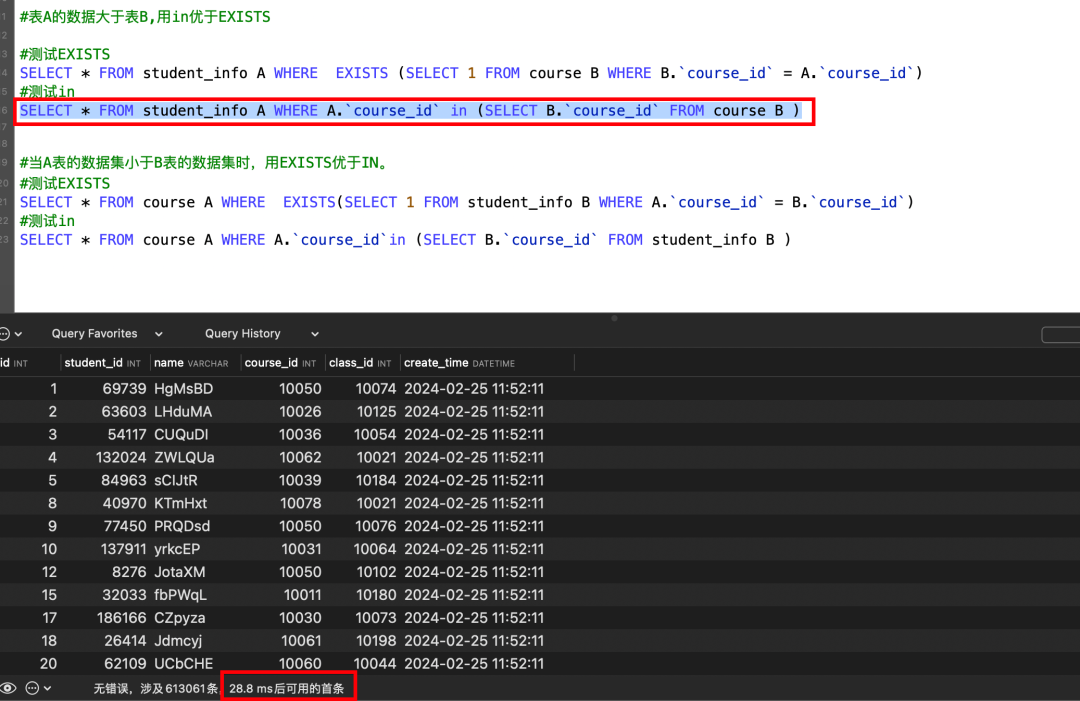
#表A的数据大于表B,用in优于EXISTS
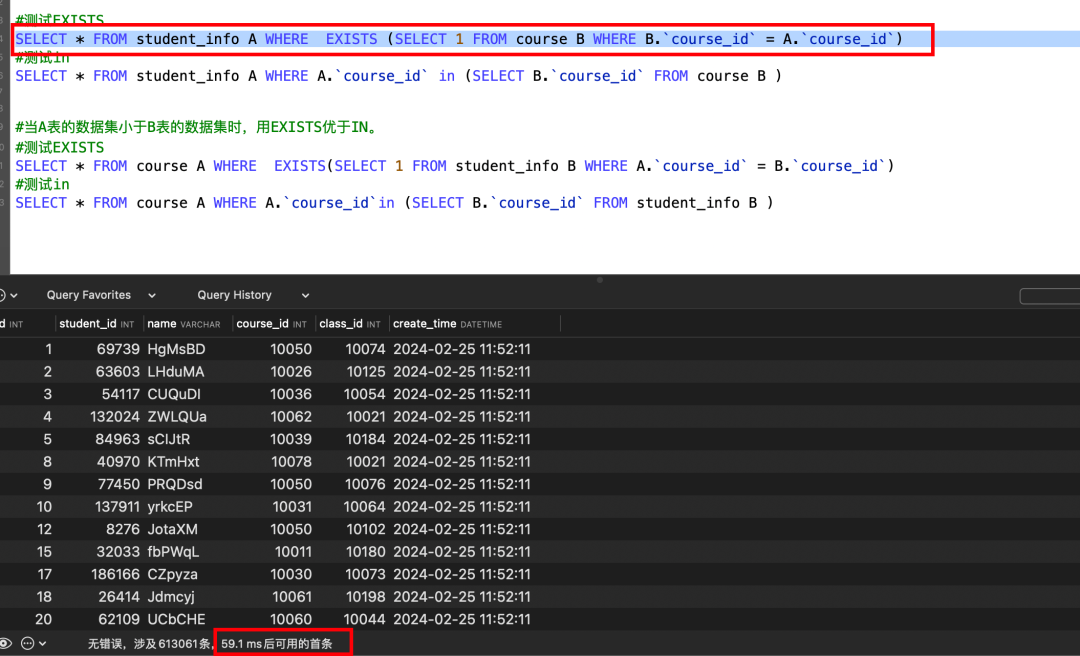
#测试EXISTS
SELECT * FROM student_info A WHERE EXISTS (SELECT 1 FROM course B WHERE B.`course_id` = A.`course_id`)
#测试in
SELECT * FROM student_info A WHERE A.`course_id` in (SELECT B.`course_id` FROM course B )
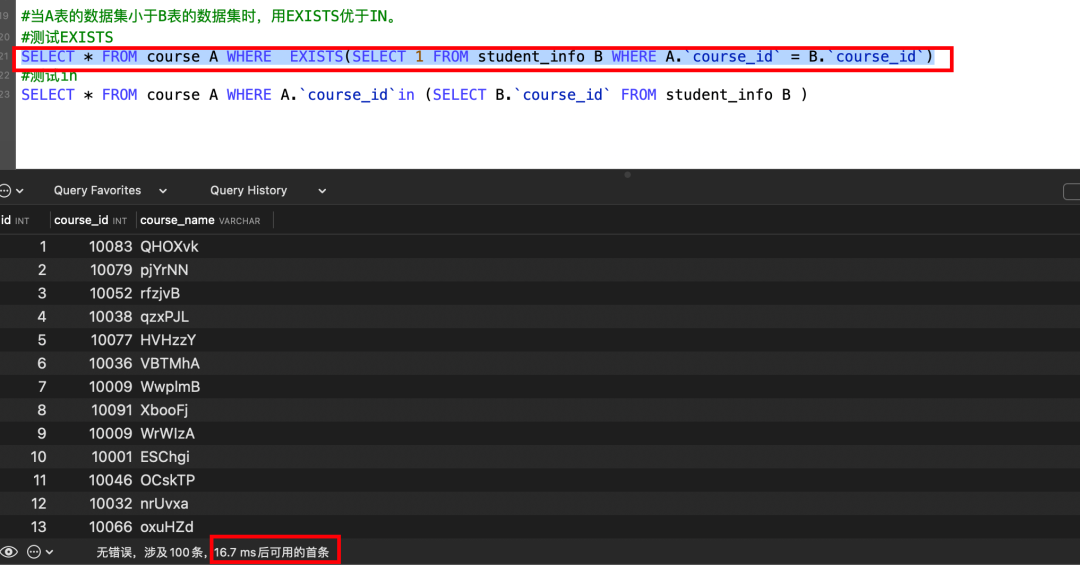
#当A表的数据集小于B表的数据集时,用EXISTS优于IN。
#测试EXISTS
SELECT * FROM course A WHERE EXISTS(SELECT 1 FROM student_info B WHERE A.`course_id` = B.`course_id`)
#测试in
SELECT * FROM course A WHERE A.`course_id`in (SELECT B.`course_id` FROM student_info B )


文章转载自程序员恰恰,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
