




大家好,今天分享的主题是 LangChian + ES Dense VECTOR + LLM 构建RAG模式。
最近发了几篇LLM的文章,有人在问是否转行了,怎么不写数据库的文章了?
其实一直在干数据库,但是也要紧跟时代的步伐,把最新的技术应用在自己的工作场景中岂不是更cool!
本文介绍的技术架构就是我们公司黑客松活动中的一个项目: 故障处理的解决方案系统。
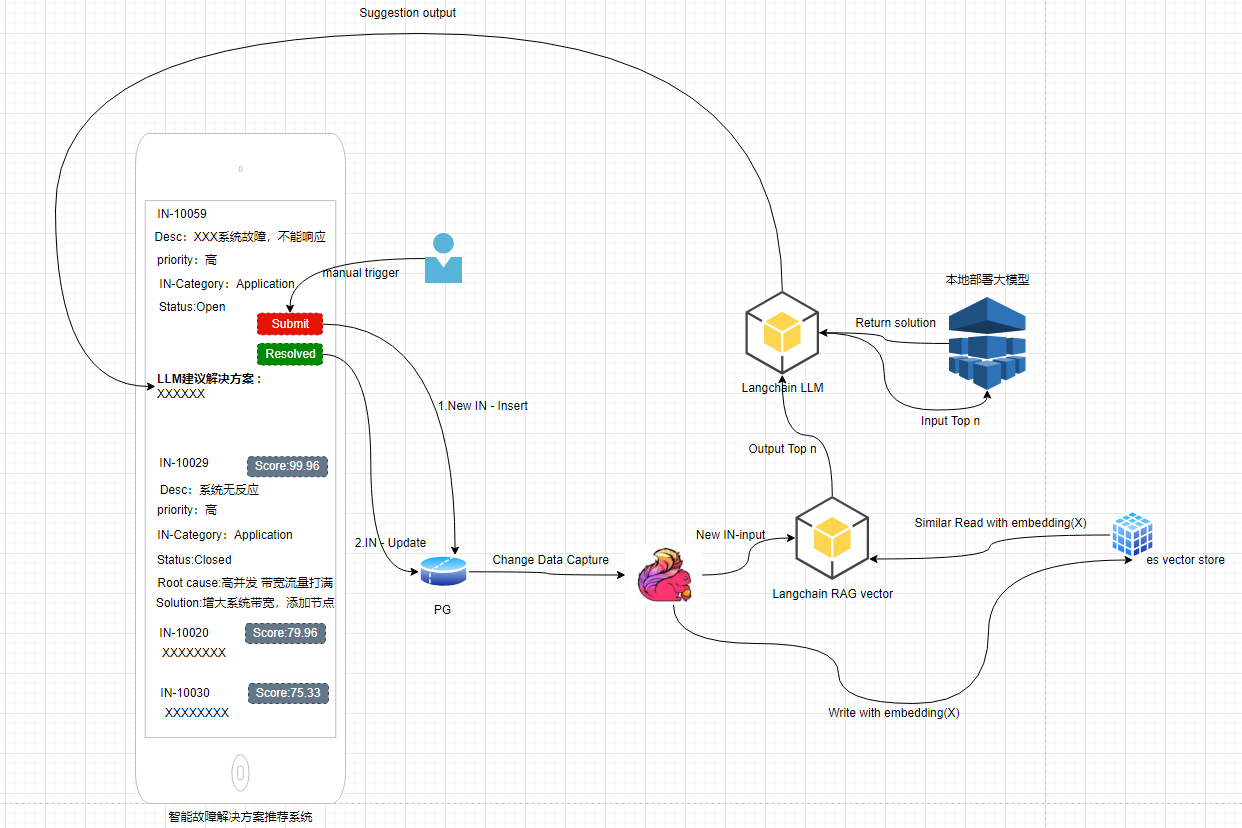
这个架构设计到的技术点众多,有DBA运维的PG数据库,大数据的flink CDC , AI大模型的框架 langchain, elasticsearch 向量类型索引,本地大模型的部署,页面H5的开发等等不同的技术堆栈…
黑客松设计到的团队成员有 DBA, 大数据开发,JAVA开发,helpdesk 人员,WEB前台开发人员等等,这是一个跨越团队的合作的项目。
本文并不会涵盖所有的技术细节,本文只是分享一下其中的RAG 模式构建的过程: LangChian + ES Dense VECTOR + LLM
首先,我们不防先看一下LangChian 这个AI框架对于向量数据库存储的支持: https://python.langchain.com/docs/integrations/vectorstores/
DBA 可以看到很多自己平时运维的老朋友数据库: Elasticsearch, MongoDB Atlas , PGVector, TiDB Cloud Redis vector database
我们本次实验是 选择的是 Elasticsearch, 纯理论输入这块可以看看es vector 官网: https://www.elastic.co/elasticsearch/vector-database
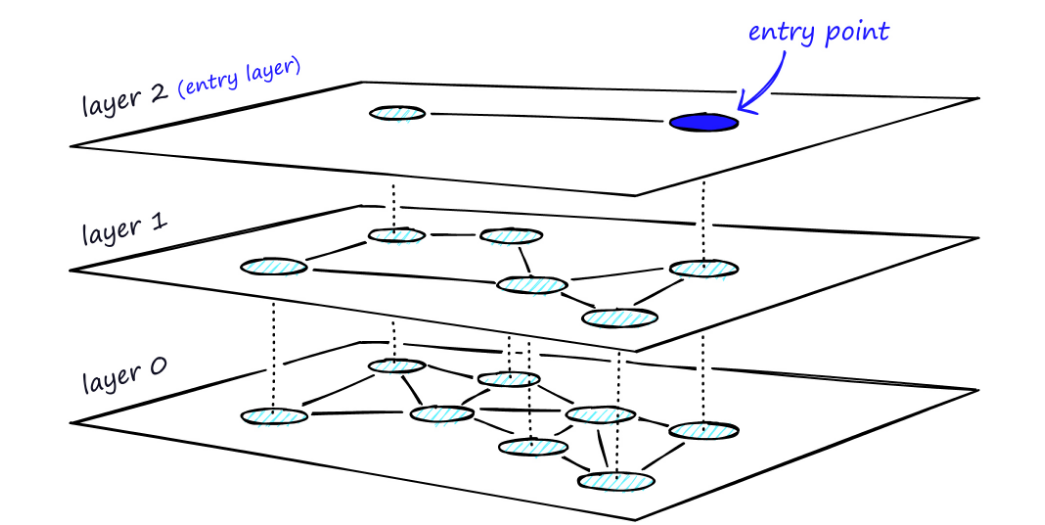
ES的向量存储的算法是 HNSW (Elasticsearch’s vector storage is based on Lucene’s HNSW.) 熟悉JAVA的小伙伴都清楚 lucence 是分布式检索的开源鼻祖。
什么是HNSW呢? Hierarchical Navigable Small Word 网上基本上都翻译成: 分层导航小世界
HNSW 创建过程:
我们本次项目是借助vector embedding :text2vec-large-chinese
关于更多的文本转向量的模型工具参考: https://github.com/shibing624/text2vec
关于文本是如何以向量的模式存入数据库的?
HNSW的创建过程超级白话简单的说分为如下步骤:
1.首先你得有数据集dataset,可以是文件形式 txt,PDF,csv,html, XML 等等,或者其他的数据库中的TEXT,VAHCAR,CLOB 等字段的值
2.把已有的数据集进行组织:假设我有1000个HTML网页,涉及到体育新闻,财经新闻,娱乐新闻等等,每张网页中根据不同的文法断句
进行下一级别的拆分,比如大事件信息体育赛事,娱乐综艺演唱会等等,然后可以根据体育赛事的时间,地点,比赛队伍信息,比分等等再次
分层进行拆解。 (vector embedding :text2vec-large-chinese 正是帮我们拆解的工具)
3.最后我们把一张网页根据拆解成为最细粒度维度数组,可以是1024,512 维度的,维度相当于每个数据的长度。
例如体育新闻的网页中原始文本如下:
2024年4月30号 晚上 7点半 在天津泰达足球场 将进行中超比赛 津门虎对阵北京国安。
这个文本拆分的逻辑有可能是: 时间 地点 人物 比赛时间 城市 。。。
每个维度会生成数字组成一个向量数组 [-0.00112321,-0.9292929,-0.000123123,-0.003333,-0.000229222]
4.最后我们把这个向量数据信息存入到支持向量的数据库中
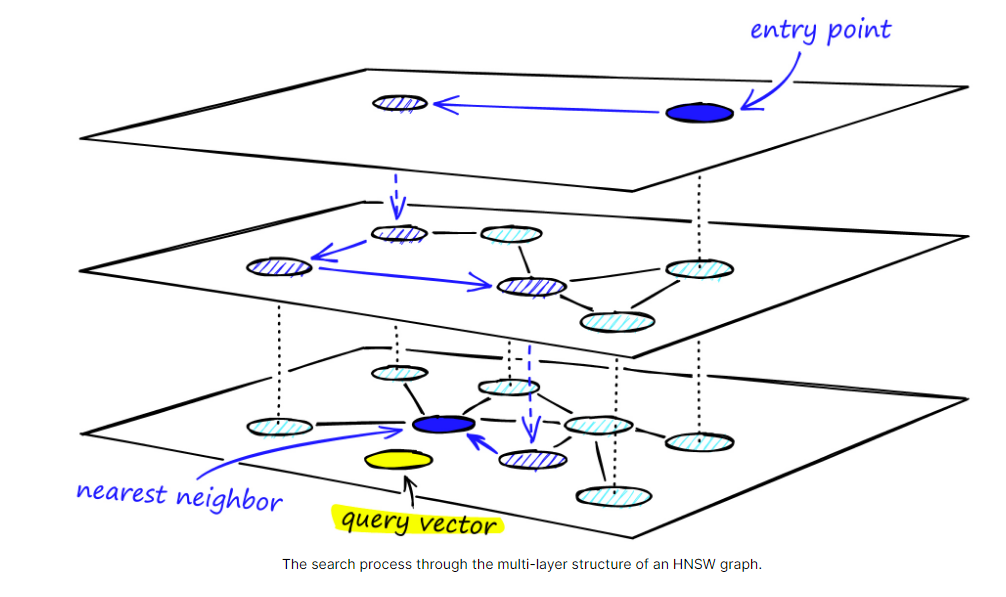
向量数据是如何检索出来的? ES 采用的是 KNN 检索过程:k-nearest neighbor (kNN) search
我们还是通过白话来解释:
我想提问外挂知识库: 中超津门虎最近主场的比赛有那些?
1) 问题语句: “中超津门虎最近主场的比赛有那些” 会再次通过 vector embedding :text2vec-large-chinese 生成向量数组。
例如 中超: 0.0002234234,津门虎: 0.12312312,中超津门虎: 0.12312321, 足球: 0.1000222, 足球比赛:0.1000120002 …
2)通过问题转化的向量[0.0002234234,0.12312312,0.12312321,0.1000222,0.1000120002] 去HNSW类型的索引中进行相似度检索
这个检索是逐层递进的,例如下图中第一层是entry point 是足球, 第二层是中超联赛, 第三层是天津津门虎足球队
当然这里是根据向量数字去匹配,最后找到距离相似度最近的向量返回文本:
返回文本: 2024年4月30号 晚上 7点半 在天津泰达足球场 将进行中超比赛 津门虎对阵北京国安。
关于ES的KNN检索相关描述可以参考: https://www.elastic.co/what-is/knn#knn-search-with-elastic
完成以上的理论输出后,最起码知道向量库是怎么回事,HNSW类型的索引是如何写入和检索的
我们看一下如何使用langchain 这个AI tool 写入 ES 向量类型的索引中。
我们准备2条数据作为数据源:
1.2024年4月30号 晚上 7点半 在天津泰达足球场 将进行中超比赛 津门虎对阵北京国安。
2.林俊杰演唱会在天津4月19号晚上7点奥体中心举行。
from langchain_elasticsearch import ElasticsearchStore from langchain.embeddings.huggingface import HuggingFaceEmbeddings from langchain_community.document_loaders import TextLoader from langchain_text_splitters import CharacterTextSplitter from elasticsearch import Elasticsearch from langchain.schema.document import Document import uvicorn from fastapi import FastAPI app = FastAPI() index_name = 'dabiaoge_vector' embeddings = HuggingFaceEmbeddings(model_name='/logs/model/text2vec-large-chinese') es_connection = Elasticsearch("http://xxx.xxx.xxx.xxx:9233") def _embeddings_hash(self): return hash(self.model_name) def get_text_chunks_langchain(text): text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0) docs = [Document(page_content=x) for x in text_splitter.split_text(text)] return docs def load_vector2es(es_connection,index_name,text): HuggingFaceEmbeddings.__hash__ = _embeddings_hash doc = get_text_chunks_langchain(text) db = ElasticsearchStore.from_documents( doc, embeddings, index_name=index_name, es_connection=es_connection) def query_vector(es_connection,embeddings,index_name,query): db = ElasticsearchStore( embedding=embeddings, index_name=index_name, es_connection=es_connection) db.client.indices.refresh(index=index_name) results = db.similarity_search(query,k=1) return results @app.get("/esvector/{query}") def api_query_vector(query): return query_vector(es_connection,embeddings,index_name,query); if __name__ == '__main__': for text in ['2024年4月30号 晚上 7点半 在天津泰达足球场 将进行中超比赛 津门虎对阵北京国安。','林俊杰演唱会在天津4月19号晚上7点奥体中心举行。'] load_vector2es(es_connection,index_name,text)
执行成功后,我们去ES上看一下这个向量索引
Performance mongo@whdrcsrv402[16:45:26]:~/.virtualenvs/AIOPS/bin $ ./python3 esvector_blog.py
No sentence-transformers model found with name /logs/model/text2vec-large-chinese. Creating a new one with MEAN pooling.
我们再来看看ES的索引类型: “type”:“dense_vector” , “dims”:1024: 1024个维度 ,similarity 近似度算法是 cosine(貌似就是我们初中学的余弦函数)
curl -XGET "http://10.25.2.105:9233/dabiaoge_vector/_mapping" {"dabiaoge_vector":{"mappings":{"properties":{"metadata":{"type":"object"},"text":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"vector":{"type":"dense_vector","dims":1024,"index":true,"similarity":"cosine"}}}}}
我们看一下ES中是个doc是如何存储的 , vector数组长度是 1024, 由"dims":1024 决定
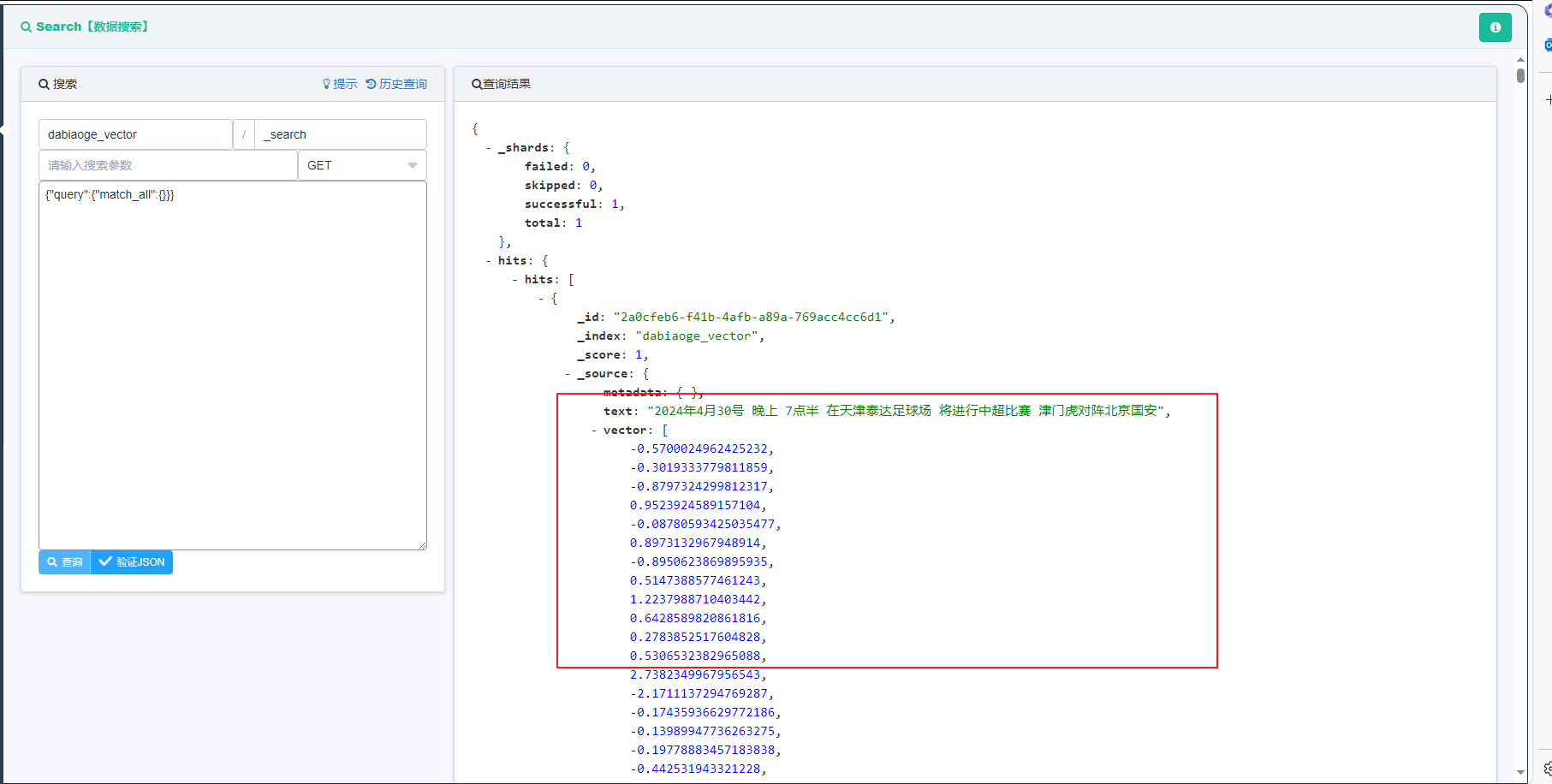
我们再来看一下ES中如何进行相似度的查询:similarity_search
def query_vector(es_connection,embeddings,index_name,query): db = ElasticsearchStore( embedding=embeddings, index_name=index_name, es_connection=es_connection) db.client.indices.refresh(index=index_name) results = db.similarity_search(query,k=1) return results @app.get("/esvector/{query}") def api_query_vector(query): return query_vector(es_connection,embeddings,index_name,query); if __name__ == '__main__': recommand_text = euery_vector(es_connection,embeddings,index_name,"我想看演唱会有什么推荐的?") print(recommand_text)
返回:林俊杰演唱会在天津4月19号晚上7点奥体中心举行
Performance mongo@whdrcsrv402[16:54:44]:~/.virtualenvs/AIOPS/bin $ ./python3 esvector_blog.py
No sentence-transformers model found with name /logs/model/text2vec-large-chinese. Creating a new one with MEAN pooling.
[Document(page_content='林俊杰演唱会在天津4月19号晚上7点奥体中心举行')]
Langchain API 还可以帮我们返回 相似度的打分 similarity_search_with_relevance_scores
def query_vector(es_connection,embeddings,index_name,query): db = ElasticsearchStore( embedding=embeddings, index_name=index_name, es_connection=es_connection) db.client.indices.refresh(index=index_name) results = db.similarity_search_with_relevance_scores(query,k=2) return results @app.get("/esvector/{query}") def api_query_vector(query): return query_vector(es_connection,embeddings,index_name,query); if __name__ == '__main__': recommand_text = query_vector(es_connection,embeddings,index_name,"我想看中超?") print(recommand_text)
返回结果: 我们可以看到打分结果, 根据score 得分高的 排在前面
page_content=‘2024年4月30号 晚上 7点半 在天津泰达足球场 将进行中超比赛 津门虎对阵北京国安’), 0.736536
page_content=‘林俊杰演唱会在天津4月19号晚上7点奥体中心举行’), 0.6912221
Performance mongo@whdrcsrv402[17:02:30]:~/.virtualenvs/AIOPS/bin $ ./python3 esvector_blog.py
No sentence-transformers model found with name /logs/model/text2vec-large-chinese. Creating a new one with MEAN pooling.
[(Document(page_content='2024年4月30号 晚上 7点半 在天津泰达足球场 将进行中超比赛 津门虎对阵北京国安'), 0.736536), (Document(page_content='林俊杰演唱会在天津4月19号晚上7点奥体中心举行'), 0.6912221)]
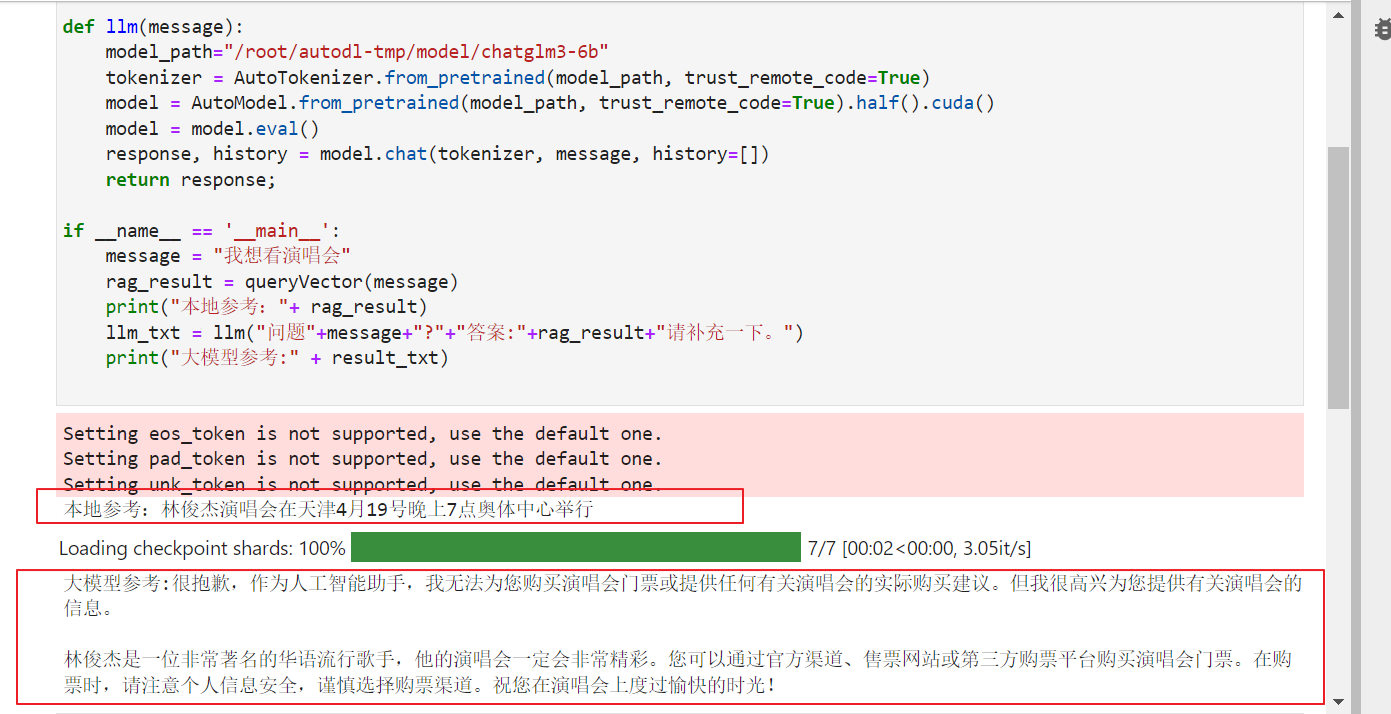
最后我们来看一下向量库返回的数据推送给LLM的效果:
import sys from langchain.embeddings.huggingface import HuggingFaceEmbeddings from langchain.vectorstores import FAISS from functools import lru_cache import requests from transformers import AutoTokenizer, AutoModel def queryVector(message): response = requests.get("http://xx.xx.xx.xx:8868/esvector/{}".format(message)) return response.json(); def llm(message): model_path="/root/autodl-tmp/model/chatglm3-6b" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda() model = model.eval() response, history = model.chat(tokenizer, message, history=[]) return response; if __name__ == '__main__': message = "我想看演唱会" rag_result = queryVector(message) llm_txt = llm("问题"+message+"?"+"答案:"+rag_result+"请补充一下。") print(result_txt)
返回结果:
最后你要对数据库运维场景人工智能化感兴趣可以加我私下交流。 (包括我们黑客松AIOPS那个项目)
目前国内中文领域的AI博客分享不是理论性的文章,就是让你头晕的算法和高等数学的公式。
还是那句话我们不玩虚的,我们不是科学家,理论派! 我们需要AI结合实际的场景是要做出来东西帮助我们更好的生活的! Less work, less code, more happy, more money, more fun!
Have a fun 🙂 !
参考资料:
https://www.elastic.co/what-is/knn#knn-search-with-elastic
https://www.pinecone.io/learn/series/faiss/hnsw/
