




 出现了很多库圈大佬的名字,看看大家有认识的吗。
出现了很多库圈大佬的名字,看看大家有认识的吗。
01 INSTALLATION
环境介绍 & 工具安装.
测试环境介绍
Linux操作系统版本:CentOS Linux release 7.5.1804 (Core)
这个工具是直接编译好的,我们可以直接下载即用。
innblock下载
因为GitHub上没有介绍安装教程,所以从网上找了一篇资料,提供了一个编译好的工具下载地址:http://pan.baidu.com/s/1qYnyVWo。
同时我也把下载好的软件放在了百度网盘,为防止原地址丢失,大家也可以从这个地址下载。(链接: https://pan.baidu.com/s/1Yftl1wqFuUhYlcU-CFYKkA,提取码: 38i0)
cd mysql_innblockchmod +x innblock
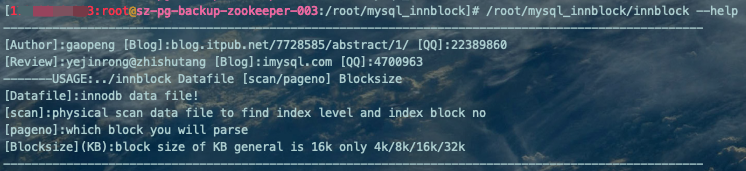
/root/mysql_innblock/innblock --help
02 DATA PREPARE
测试数据准备.
MySQL环境要求
不支持REDUNDANT行格式的数据文件;
只支持LINUX x64平台;
本工具直接读取物理文件,部分Dirty Page可能延时刷盘而未能被读取到,可以让InnoDB及时刷盘再重新读取;
最好在MySQL 5.6/5.7版本下测试;
只能解析索引页,不支持INODE Page、UNDO LOG等类型的Page;
SCAN功能会包含DELETE后的索引块和DROP了的索引块.
不能读取详细的ROW Data;
建议采用独立表空间模式,更便于观察;
建议仅在测试环境下学习和研究使用。
测试数据准备
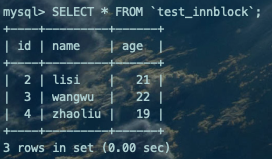
--Create DatabaseCREATE DATABASE test_innblock;--Create TableUSE test_innblock;CREATE TABLE `test_innblock` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(30) DEFAULT NULL, `age` INT(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY(`name`),KEY(`age`)) ENGINE=InnoDB;--Insert Test DataINSERT INTO `test_innblock` VALUES(1,'zhangsan',20),(2,'lisi',21),(3,'wangwu',22),(4,'zhaoliu',19);--Delete Test DataDELETE FROM `test_innblock` WHERE `id`=1;--Query DataSELECT * FROM `test_innblock`;
03 INTRODUCE
工具用法介绍.
两大功能
第一个scan功能用于查找ibd文件中所有的索引页。 第二个analyze功能用于扫描数据块里的ROW Data。
扫描所有Index Page
/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/test_innblock.ibd scan 16
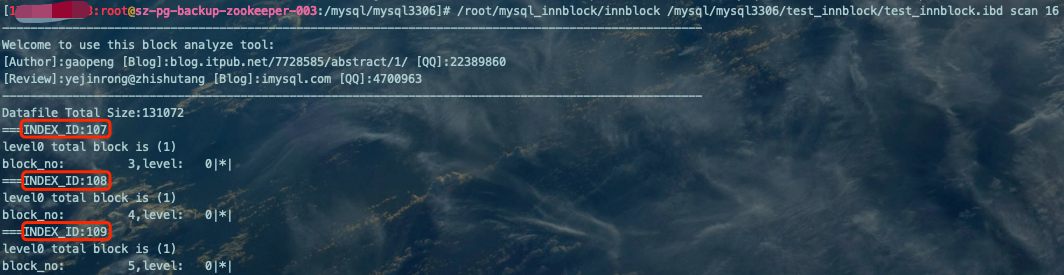
总共扫描出3个索引,索引ID(INDEX_ID)分别是107、108、109。再通过查看数据字典确认:
SELECT A.SPACE AS TBL_SPACEID, A.TABLE_ID, A.NAME AS TABLE_NAME, FILE_FORMAT, ROW_FORMAT, SPACE_TYPE, B.INDEX_ID , B.NAME AS INDEX_NAME, PAGE_NO, B.TYPE AS INDEX_TYPE FROM information_schema.INNODB_SYS_TABLES A LEFT JOIN information_schema.INNODB_SYS_INDEXES B ON A.TABLE_ID =B.TABLE_ID WHERE A.NAME = 'test_innblock/test_innblock';

扫描指定PAGE_NO的索引页
/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/test_innblock.ibd 3 16
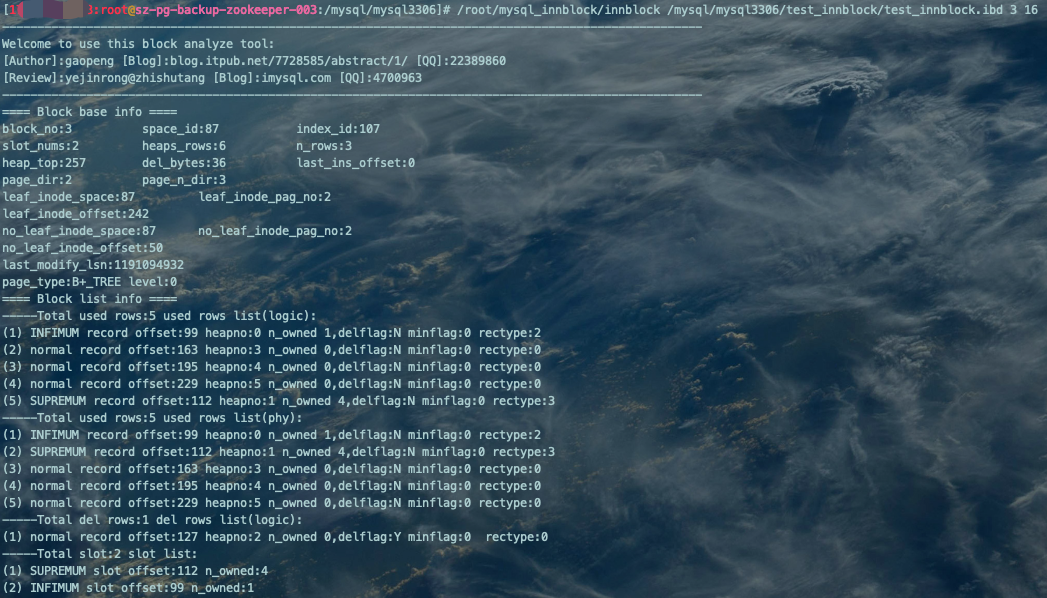
输出信息详解
详解的话还是对照一下这个图看比较方便:
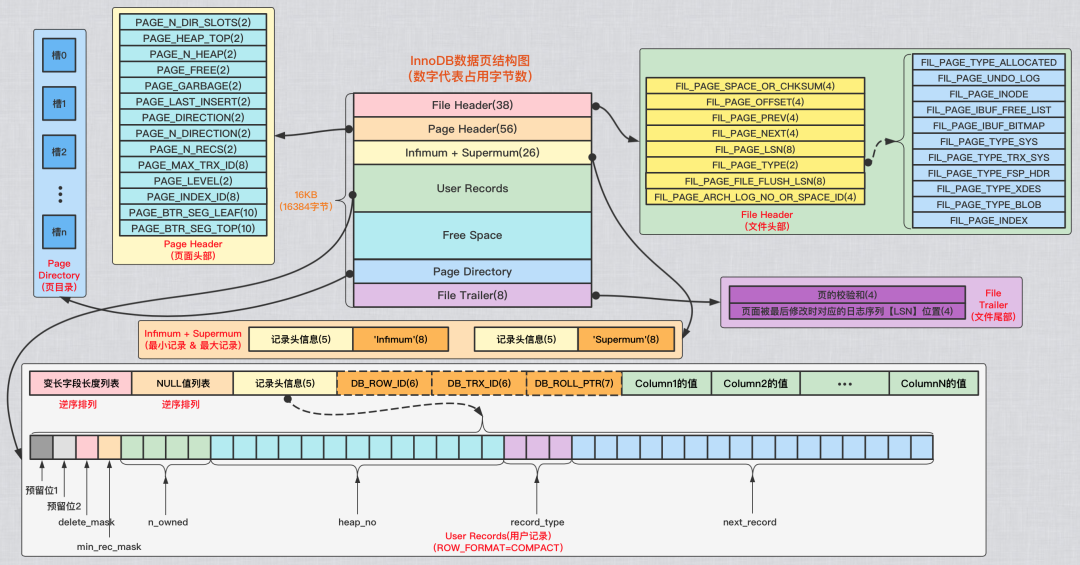
==== Block base info ====(块基本信息):
n_rows:本索引页中的记录数,不含deleted且已被purged的记录,以及两个伪记录INFIMUM、SUPREMUM。该值取自Page Header的PAGE_N_RECS【该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录),2字节】。
heap_top:指向本索引页已分配的最大物理存储空间的偏移量。该值取自Page Header的PAGE_HEAP_TOP【还未使用的空间最小地址,也就是说从该地址之后就是Free Space,2字节】。
del_bytes:本索引页中所有deleted了的且已被purged的记录的总大小。该值取自Page Header的PAGE_GARBAGE【已删除记录占用的字节数,2字节】。
last_ins_offset:指向本索引页最后插入记录的位置偏移量,如果最后操作是delete,则这个偏移量为空。通过判断索引页内数据最后插入的方向,用于索引分裂判断。该值取自Page Header的PAGE_LAST_INSERT【最后插入记录的位置,2字节】。
page_dir:本索引页中数据最后插入的方向,同样用于索引分裂判断。该值取自Page Header的PAGE_DIRECTION【记录插入的方向,2字节】。
page_n_dir:向同一个方向插入数据的行数,同样用于索引分裂中进行判断。该值取自Page Header的PAGE_N_DIRECTION【一个方向连续插入的记录数量,假如新插入的一条记录的主键值比上一条记录的主键值大,我们说这条记录的插入方向是右边,反之则是左边,2字节】。
leaf_inode_space leaf_inode_pag_no leaf_inode_offset & no_leaf_inode_space no_leaf_inode_pag_no no_leaf_inode_offset:这6个值只在root节点会有信息,分别表示了叶子段和非叶子段的inode的位置和在inode块中的偏移量,其他块都为0。分别取自Page Header的PAGE_BTR_SEG_LEAF【B+树叶子段的头部信息,仅在B+树的Root页定义,10字节】、PAGE_BTR_SEG_TOP【B+树非叶子段的头部信息,仅在B+树的Root页定义,10字节】。
last_modify_lsn:本块最后一次修改的LSN。该值取自File Header的FIL_PAGE_LSN【页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number),8字节】。
page_type:对于本工具而言始终为B+TREE,因为不支持其它Page Type。该值取自File Header的FIL_PAGE_TYPE【该页的类型,2字节】。
level:本索引页所处的B+TREE的层级。注意,叶子结点的PAGE LEVEL为0。该值取自Page Header的PAGE_LEVEL【当前页在B+树中所处的层级,2字节】。
==== Block list info ====(块链表信息):
-----Total used rows:5 used rows list(logic):这个链表是逻辑有序链表,也是我们平时所说的块内数据有序的展示。它的顺序当然按照主键或者ROWID进行排列,因为是通过物理偏移量链表实现的,实际上就是逻辑上有序。作者在实现的时候实际上是取了INFIMUM的偏移量开始进行扫描直到最后,但是注意被deleted且已经被purged的记录不在其中。
-----Total used rows:5 used rows list(phy):这个链表是物理上的顺序,实际上就是heap no的顺序,我在实现的时候实际上就是将上面的逻辑链表按照heap no进行排序完成的,所以块内部是逻辑有序物理无序的,同样注意被deleted且已被purged的记录不在其中。
-----Total del rows:1 del rows list(logic):这个链表是逻辑上的,也就是被deleted且被purged后的记录都存在于这个链表中,通过读取块的PAGE_FREE获取链表信息。(就是我们一开始删除的那条数据就加入到了这个链表)
-----Total slot:2 slot list:这是slot(槽的)信息,通过扫描块尾部8字节以前信息进行分析得到,我们可以发现在slot中存储的是记录的偏移量。
链表中包含的属性信息(取自记录头信息Record Header):
04 EXAMPLE
使用示例.
--Create TableUSE test_innblock;CREATE TABLE `example_innblock` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(30) DEFAULT NULL, `age` INT(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY(`name`),KEY(`age`)) ENGINE=InnoDB;--Insert Test DataINSERT INTO `example_innblock` VALUES(1,'zhangsan',20),(2,'lisi',21),(3,'wangwu',22),(4,'zhaoliu',19);
查看一下当前记录:
SELECT * FROM `test_innblock`.`example_innblock`;

BEGIN;DELETE FROM `test_innblock`.`example_innblock` WHERE id=1;

/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/example_innblock.ibd 3 16
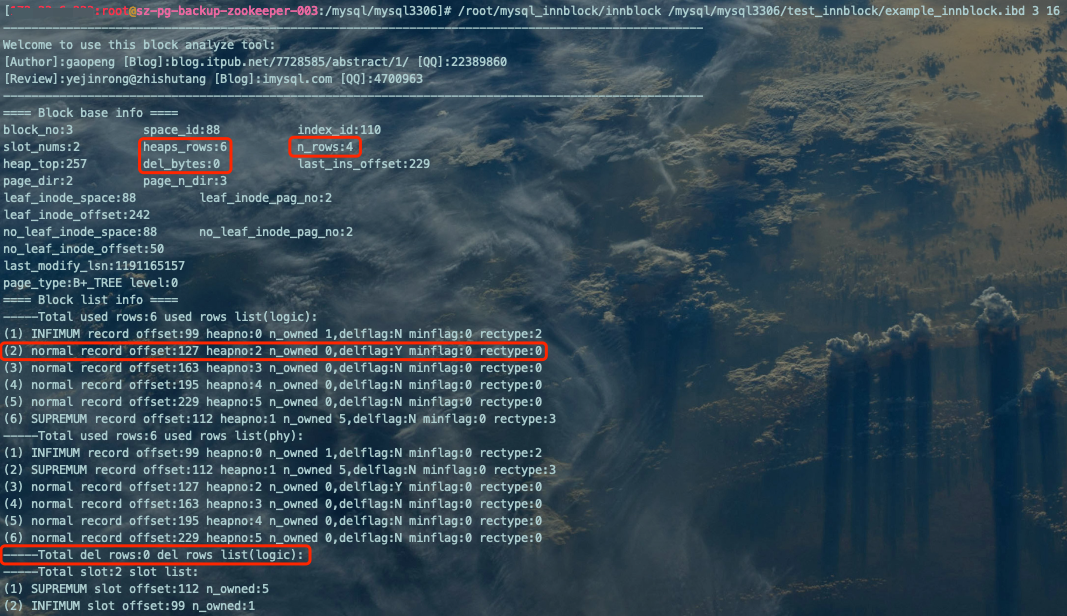
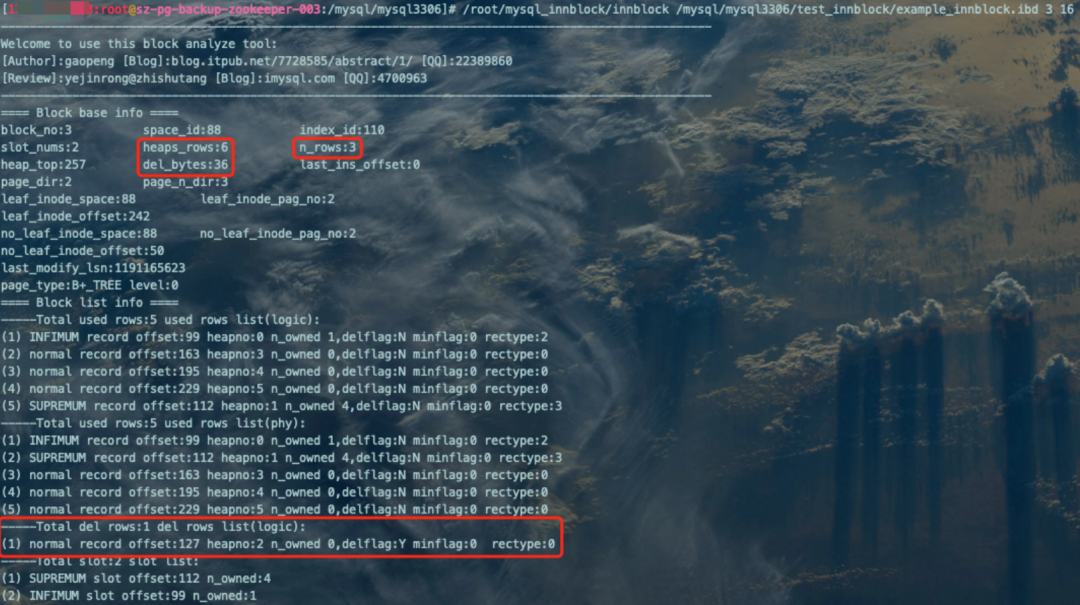
'(2) normal record offset:127 heapno:2 n_owned 0,delflag:Y minflag:0 rectype:0':偏移量为127的普通记录,被标记delete了。 '-----Total del rows:0 del rows list(logic):'显示为空:被标记delete的偏移量为127的记录所在事务没有COMMIT,也还没被purged(还没有被放到garbage队列),所以del rows List链表显示为空。 'heaps_rows:6':表示该文件中加上最大、最小记录和真实记录,一共6行记录。 'del_bytes:0':已删除并加入到garbage队列记录占用的字节数为0,就是没有加入garbage队列的记录。 'n_rows:4':该页中真实用户记录的数量(不包括最小和最大记录以及被标记为删除的记录)为4。
COMMIT;

/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/example_innblock.ibd 3 16
如图可得:
'-----Total del rows:1 del rows list(logic): (1) normal record offset:127 heapno:2 n_owned 0,delflag:Y minflag:0 rectype:0':执行commit,偏移量为127的普通记录被purged后加入了del rows List链表。
'heaps_rows:6':和上次看到的值一样,一共还是6行记录,这里计算的是物理记录数,虽然数据被delete且被purged,但只是逻辑上加入了del rows List链表,物理上这行记录仍在。
'del_bytes:36':上一次看到的值是0,表示删除的数据占用36字节大小。
'n_rows:3':上一次看到的值是4,表示真实用户记录被删除了1条。
综上,commit且被purged的记录才是真正的删除(清除)。
INSERT INTO `example_innblock` VALUES(5,'zhangsanfeng',28);

/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/example_innblock.ibd 3 16
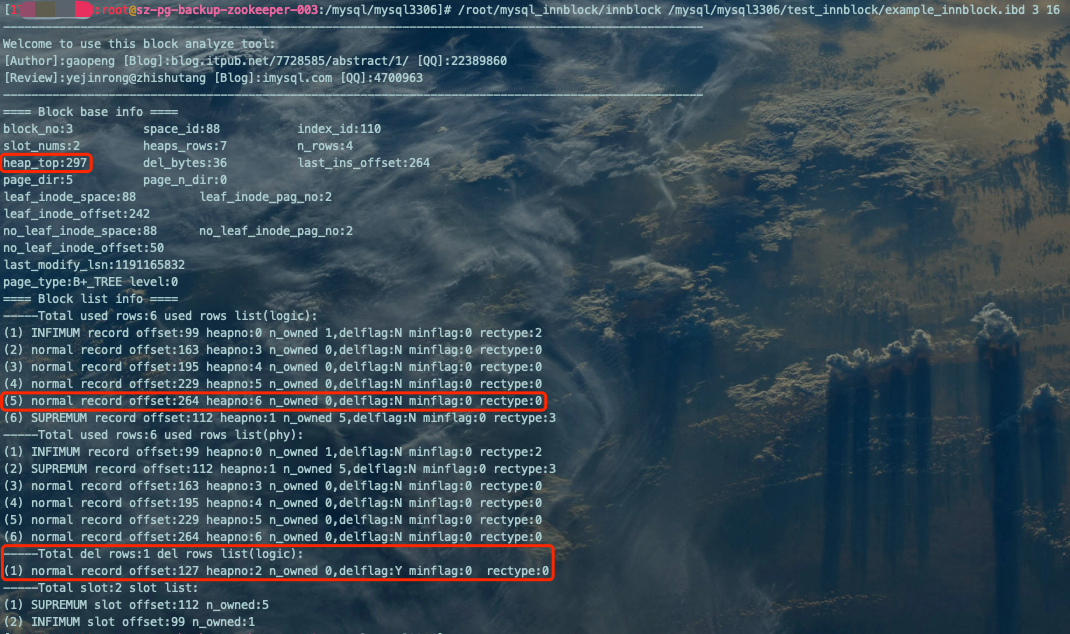
'(5) normal record offset:264 heapno:6 n_owned 0,delflag:N minflag:0 rectype:0'、'-----Total del rows:1 del rows list(logic):(1) normal record offset:127 heapno:2 n_owned 0,delflag:Y minflag:0 rectype:0':新增这条记录heapno=6。而删除的旧记录是heapno=2且还在del rows List链表中,这表明新增heapno=6的记录没有重用del rows List中的空间,因为删除记录的空间根本放不下这条新记录,所以只能重新分配。 'heap_top:297':上一次看到的值是257,这也实际表明为这行新增数据分配了新的heapno。
INSERT INTO `example_innblock` VALUES(6,'zhangli',20);

分析结果:
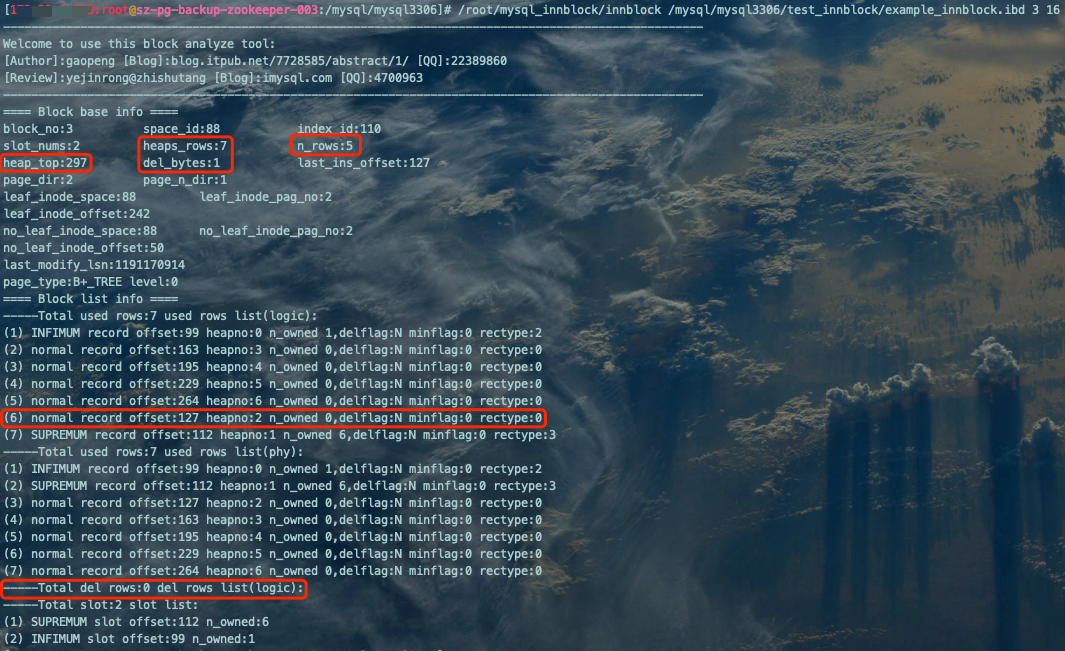
如图可得:
'(6) normal record offset:127 heapno:2 n_owned 0,delflag:N minflag:0 rectype:0'、'-----Total del rows:0 del rows list(logic):':我们这次新写入的数据长度较删除的数据长度较短,heapno=2的位置被重用,同时heapno=2的记录delflag不再是Y了,del rows List链表中的记录没有了,而在数据逻辑顺序中多了一条。
'heap_top:297':与E.g.3的值一致。
'del_bytes:1':也减少到1。
综上,删除原记录后再insert数据长度更小或者相同大小记录,旧的heapno会重用。
--先清空旧表TRUNCATE TABLE `example_innblock`;--按顺序执行以下操作INSERT INTO `example_innblock` VALUES(1,'zhangsan',20),(2,'lisi',21),(3,'wangwu',22),(4,'zhaoliu',19);DELETE FROM `example_innblock` WHERE id=4;DELETE FROM `example_innblock` WHERE id=3;INSERT INTO `example_innblock` VALUES(5,'zhangsa',20);
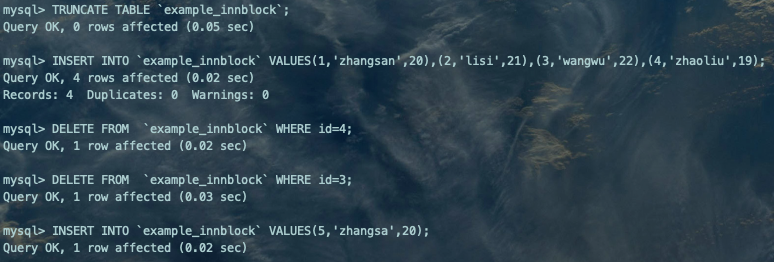
本例中,我们先删除id=4的记录,后删除id=3的记录。
由于del rows List链表是头插法(类似于栈的数据结构),所以后删除的id=3的记录会放在del rows List链表的最头部,也就是del list header → id=3 → id=4。虽然id=4的记录空间足以容下新记录(5,'zhangsa',20),但并没被重用。因为InnoDB只检测第一个del rows List链表中的第一个空位id=3的记录,显然这个记录(3,'wangwu',22)空间不足以容下新记录(5,'zhangsa',20),所以还是开辟了新的heap。
/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/example_innblock.ibd 3 16
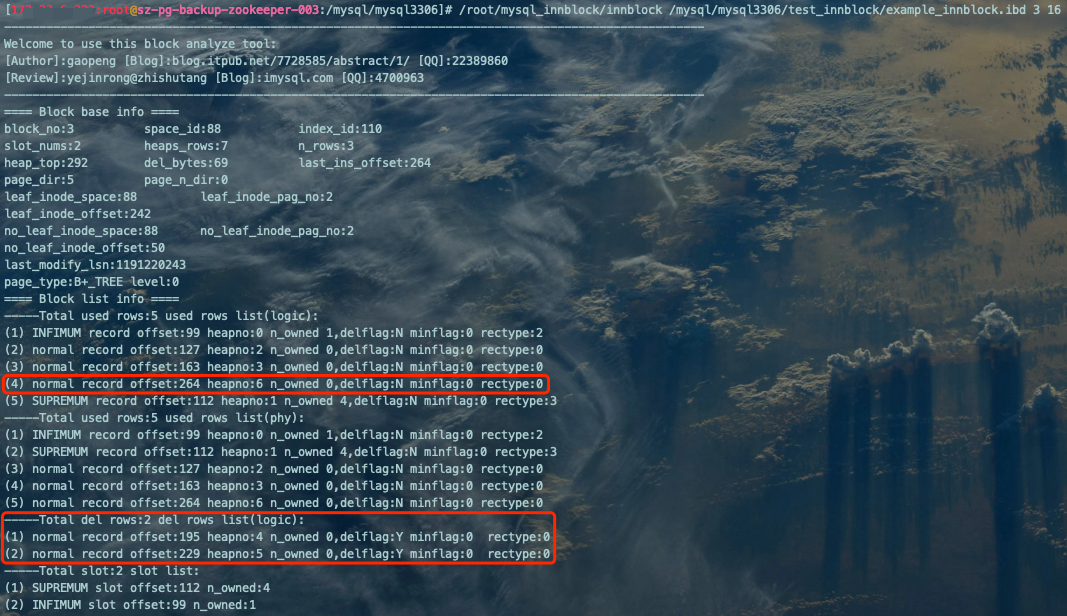
'-----Total del rows:2 del rows list(logic):(1) normal record offset:195 heapno:4 n_owned 0,delflag:Y minflag:0 rectype:0(2) normal record offset:229 heapno:5 n_owned 0,delflag:Y minflag:0 rectype:0':del rows List链表中共有2条记录,证明我们删除的记录位置没有被重用。 '(4) normal record offset:264 heapno:6 n_owned 0,delflag:N minflag:0 rectype:0':新增加了heapno=6的记录。
--先清空旧表TRUNCATE TABLE `example_innblock`;--按顺序执行以下操作INSERT INTO `example_innblock` VALUES(1,'lulu',20),(2,'lulu',21),(3,'lulu',22),(4,'luluzhang',19);DELETE FROM `example_innblock` WHERE id=4;
/root/mysql_innblock/innblock /mysql/mysql3306/test_innblock/example_innblock.ibd 3 16
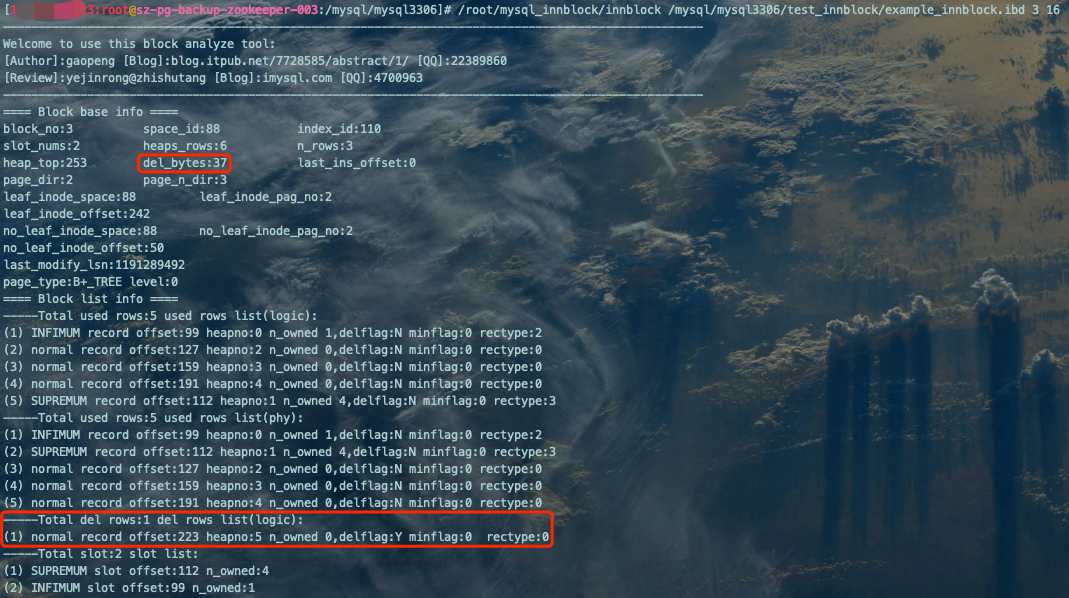
INSERT INTO `example_innblock` VALUES(5,'lulu',20);


如图可得,虽然空间被复用了,但是del_bytes:5表示PAGE_GARBAGE的空间占用为5字节,这5字节就是传说中的碎片【浪费不可再被利用的空间】(注意这里的碎片和之前MySQL之InnoDB表空间说过的碎片(fragment)区不是一回事儿,大家一定要区分开来)。这里的del_bytes:5是怎么得出来的:删除的'luluzhang'占用9字节,插入的'lulu'占用4字节,虽然空间被复用,但是没有被用完,所以就浪费掉了9-4=5字节的空间。
E.g.7:UPDATE操作,del_bytes(PAGE_GARBAGE)是否包含碎片空间:
基于上面的步骤,我们继续插入一条数据:
INSERT INTO `example_innblock` VALUES(6,'luluzhang',21);


UPDATE `example_innblock` SET name='lulu' WHERE id=6;


UPDATE `example_innblock` SET name='lululuzhang' WHERE id=6;

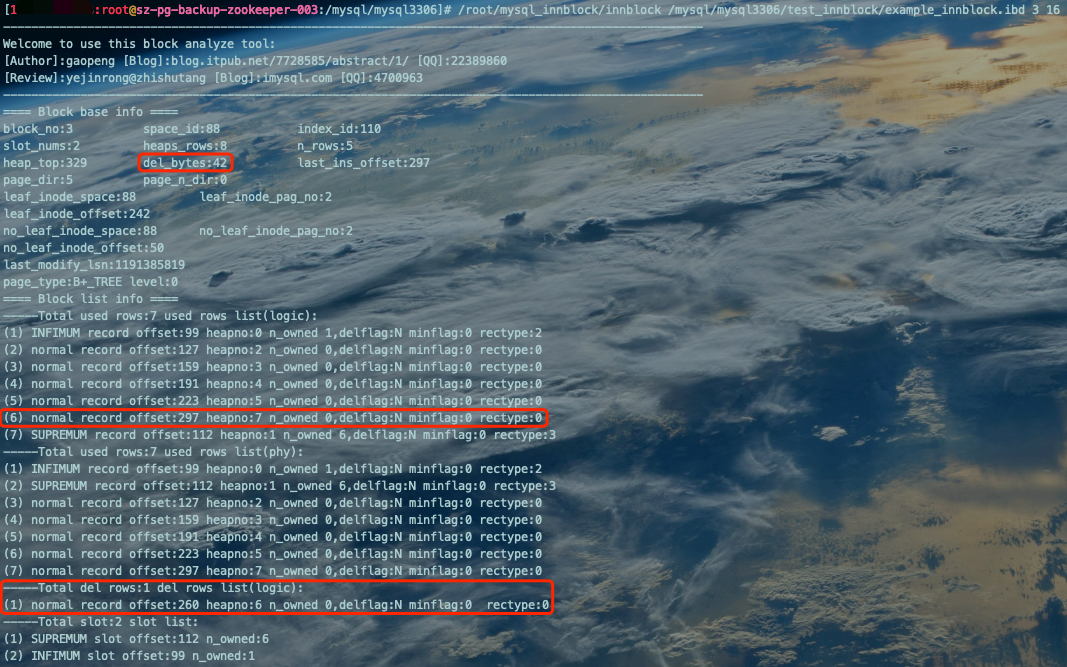
INSERT INTO `example_innblock` VALUES(7,'luluzhang',21);

分析结果:
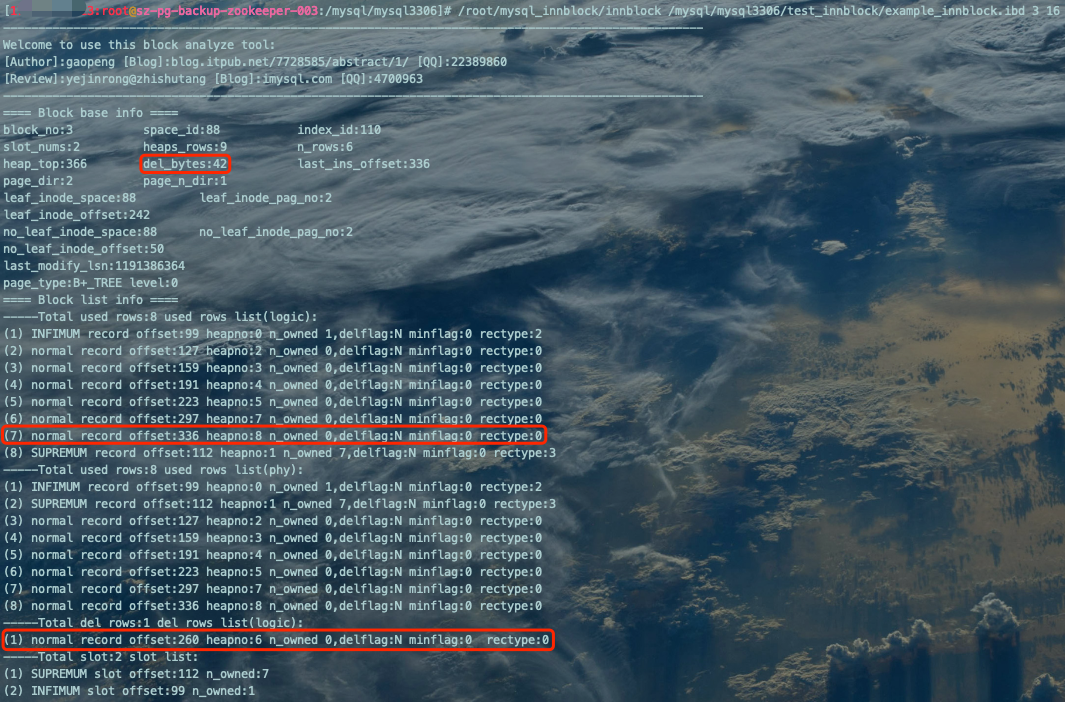
由图可得:heapno=6的空间没有被复用,新增数据申请了heapno=8的新空间,del_bytes的值停留在了42字节。至此,得到结论,频繁的DML操作确实会产生表空间碎片。
05 END
小结.
delete但还未commit的记录没有真正被清除,只是打了一个delete_mask的标记(将值从0变为1),即delflag → Y。 commit且被purged的记录(加入到del rows List链表中的记录)才是真正的删除(清除)。 删除原记录后insert数据长度更长的新记录,加入到del rows List链表中旧的heapno(空间)不会复用,会申请新的空间来存放。 删除原记录后再insert数据长度更短或者数据长度相同的记录,加入到del rows List链表中旧的heapno会复用。 加入到del rows List链表中旧的heapno(空间)复用机制是InnoDB只检测第一个del rows List链表中的第一个空位(头插法,最近操作加入到del rows List链表的空间)是否满足空间要求,满足则复用,不满足则放弃并申请新空间。 删除原记录后再insert数据长度较短的数据,加入到del rows List链表中旧的heapno会复用,但会生成新旧两条数据相差长度的碎片。 UPDATE更新的新记录较原记录数据长度短的情况,原空间会被复用,但会生成新旧两条数据相差长度的碎片;UPDATE更新的新记录较原记录数据长度长的情况,原空间不会被复用且加入到del rows List链表,不会打delete_mask标记,会申请新的空间来存放新数据。 频繁的DML操作确实会产生表空间碎片。


end
