





作者:古尔辛·耶尔德勒姆·耶利内克 (Gulcin Yildirim Jelinek)
EDB 的一名高级工程师。她的核心专业领域是:PostgreSQL、软件自动化、云、Kubernetes、Ansible、技术管理、社区建设等。她在 IT 领域工作了 13 年多,担任过从 DBA 到软件自动化开发人员再到 DevOps 和站点可靠性工程师等职位。在加入 EDB 之前,她担任云服务经理,负责构建具有分布式数据库层次结构的数据库即服务平台。目前,她在 EDB 工作了 2 年,致力于开发 TPA,这是一种用于部署 Postgres 集群的开源编排工具。她自 2015 年以来一直为该项目做出贡献。最近,她担任开发者角色,分享她的经验,以建立内部团队之间的联系,并向更广泛的受众展示EDB的未知瑰宝。
前言
有一千种方法(可能更多)可以加速 Postgres 工作负载。这取决于您存储数据、查询数据的方式、数据有多大以及运行这些查询的频率。在这篇博文中,我们将探讨 pgvector 如何帮助处理 Postgres 中基于 AI 的工作负载,使您的数据库向量操作更快、更高效。
pgvector:在 Postgres 中存储和查询向量
pgvector是一个 PostgreSQL 扩展,允许您存储、查询和索引向量。
Postgres 尚不具备原生向量功能(从 Postgres 16 开始),而 pgvector 旨在填补这一空白。您可以将向量数据与其他数据一起存储在 Postgres 中,并进行向量相似性搜索,同时仍然可以利用 Postgres 提供的所有强大功能。
谁需要向量相似性搜索?
在处理高维数据时,尤其是在推荐引擎、图像搜索和自然语言处理等应用中,向量相似性搜索是一项关键功能。许多人工智能应用程序会涉及根据用户行为或内容相似性查找相似的项目或推荐。pgvector 可以高效地执行向量相似度搜索,使其适用于推荐系统、基于内容的过滤和基于相似度的 AI 任务。
pgvector 扩展与 Postgres 无缝集成 - 允许用户在现有数据库基础设施中利用其功能。这简化了人工智能应用程序的部署和管理,因为不需要单独的数据存储或复杂的数据传输过程。
向量到底是什么?
简而言之,向量只是数字列表。如果您曾经学习过线性代数课程,那么现在是获得好处的时候了,因为相似性搜索毕竟是在进行一系列向量运算!
在几何中,向量表示 n 维空间中的坐标,其中 n 是维数。下图中有一个二维向量 (n=2)。在机器学习中,我们使用高维向量,但想象它们并不像下面所示的简单向量那么容易。
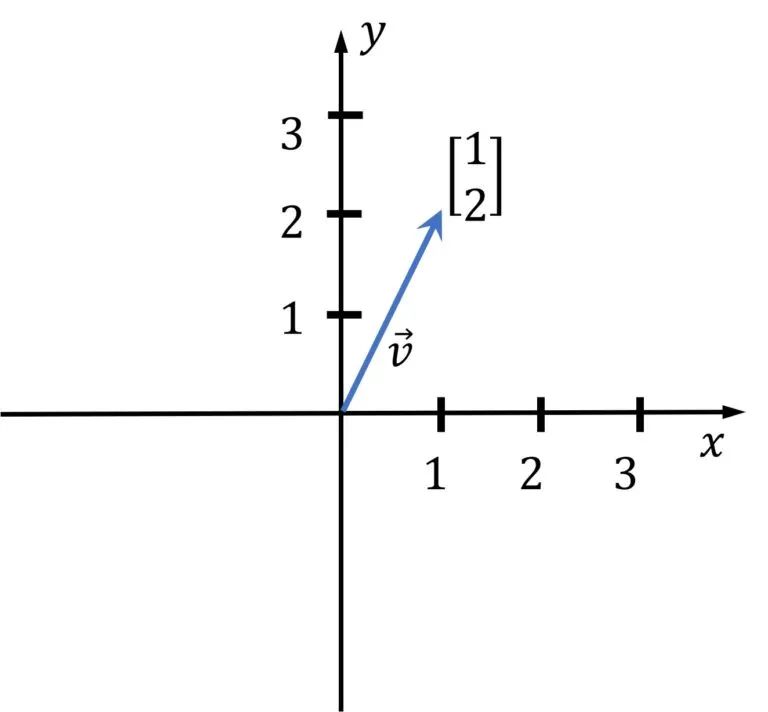
图片来源:https://media5.datahacker.rs/2020/03/Picture36-1-768x712.jpg
应用示例:
在本文示例中,我们将存储一些文档,生成向量嵌入并将它们存储在 Postgres 中。我们将对嵌入数据建立索引并对嵌入运行相似性查询。
示例代码:https://github.com/gulcin/pgvector_blog
先决条件:
已安装 PostgreSQL(pgvector 支持 PostgreSQL 11+)
已安装 pgvector 扩展(请参阅安装说明)
拥有OpenAPI 帐户并有一些信用余额(使用量少于 1 美元)。
安装 pgvector 后,您可以在 Postgres 数据库中通过创建扩展启用它:
postgres=# Create extension vector;
CREATE EXTENSION复制
第 1 步:创建文档表格
让我们创建一个简单的表来存储文档。该表中的每一行代表一个文档,我们存储文档的标题和内容。
创建文档表:
CREATE TABLE documents (
id int PRIMARY KEY,
title text NOT NULL,
content TEXT NOT NULL
);复制
对于我们存储的每个文档,将生成一个嵌入,在这里我们创建一个 document_embeddings 表来存储它们。您可以看到嵌入向量的大小为 1536,这是因为我们使用的 OpenAI 模型有 1536 维。
-- Create document_embeddings table
CREATE TABLE document_embeddings (
id int PRIMARY KEY,
embedding vector(1536) NOT NULL
);复制
让我们使用 HNSW 索引对数据进行索引。
CREATE INDEX document_embeddings_embedding_idx ON document_embeddings USING hnsw (embedding vector_l2_ops);复制
我将在下一篇博客文章中讨论向量数据库中的索引,因此我不会在这里详细介绍,但我们知道HNSW比 IVFFlat 具有更好的查询性能。
同样对于IVFFlat索引,建议在表有一些数据后创建索引,但 HNSW 索引没有像 IVFFlat 那样的训练步骤,因此可以在表中没有任何数据的情况下创建索引。您可能已经注意到,我在按照建议将数据插入表之前创建了索引。
现在我们可以将一些示例数据插入表中。对于示例数据,我选择了 Postgres 扩展及其简短描述。
-- Insert documents into documents table
INSERT INTO documents VALUES ('1', 'pgvector', 'pgvector is a PostgreSQL extension that provides support for vector similarity search and nearest neighbor search in SQL.');
INSERT INTO documents VALUES ('2', 'pg_similarity', 'pg_similarity is a PostgreSQL extension that provides similarity and distance operators for vector columns.');
INSERT INTO documents VALUES ('3', 'pg_trgm', 'pg_trgm is a PostgreSQL extension that provides functions and operators for determining the similarity of alphanumeric text based on trigram matching.');
INSERT INTO documents VALUES ('4', 'pg_prewarm', 'pg_prewarm is a PostgreSQL extension that provides functions for prewarming relation data into the PostgreSQL buffer cache.');复制
第 2 步: 生成嵌入
现在我们已经存储了文档,我们将使用嵌入模型将文档转换为嵌入(复杂的问题交给大模型来处理)。
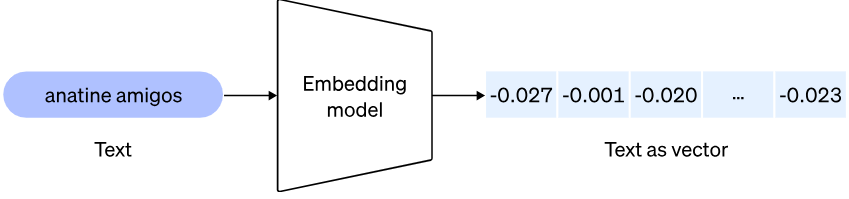
图片来源:https://cdn.openai.com/new-and-improved-embedding-model/draft-20221214a/vectors-1.svg
首先,我们来谈谈嵌入。我最喜欢OpenAI 文档中的定义,因为它简单切题:
“嵌入是浮点数的向量(列表)。两个向量之间的距离衡量它们的相关性。距离小表明相关性高,距离大表明相关性低。”
因此,如果我们要比较两个文档在语义上的相关程度,则必须将这些文档转换为嵌入并对它们运行相似性搜索。
在本示例中,我使用了 OpenAI API 和 Python。有多个 API 提供商可供选择,可以通过您选择的语言使用这些 API。考虑简单性以及我之前的使用经验,我选择了 OpenAI API,Python 是我的首选语言。示例中使用的嵌入模型是“text-embedding-ada-002”,它非常适合我们的使用案例,因为它便宜且易于使用。在实际应用程序中使用此模型时,您可能需要根据具体用例评估不同的模型。
让我们开始吧!下面的 Python 代码,您需要获取 OpenAI API 密钥,并填写连接字符串以连接到 Postgres 数据库。
# Python code to preprocess and embed documents
import openai
import psycopg2
# Load OpenAI API key
openai.api_key = "sk-..." #YOUR OWN API KEY
# Pick the embedding model
model_id = "text-embedding-ada-002"
# Connect to PostgreSQL database
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
# Fetch documents from the database
cur = conn.cursor()
cur.execute("SELECT id, content FROM documents")
documents = cur.fetchall()
# Process and store embeddings in the database
for doc_id, doc_content in documents:
embedding = openai.Embedding.create(input=doc_content, model=model_id)['data'][0]['embedding']
cur.execute("INSERT INTO document_embeddings (id, embedding) VALUES (%s, %s);", (doc_id, embedding))
conn.commit()
# Commit and close the database connection
conn.commit()复制
以上代码只是从数据库中获取文档内容,并使用 OpenAI API 生成嵌入并将其存储回数据库中。这对于我们的小型数据库来说很好,但在现实场景中,您可能希望对现有数据使用批处理,并且可能需要某种事件触发器或更改流,以在数据库更改时保持向量最新。
第 3 步:查询嵌入
现在我们已经将嵌入存储在数据库中,我们可以使用 pgvector 查询它们。下面的代码显示了如何执行相似性搜索来查找与给定查询文档相似的文档。
# Python code to preprocess and embed documents
import psycopg2
# Connect to PostgreSQL database
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
cur = conn.cursor()
# Fetch extensions that are similar to pgvector based on their descriptions
query = """
WITH pgv AS (
SELECT embedding
FROM document_embeddings JOIN documents USING (id)
WHERE title = 'pgvector'
)
SELECT title, content
FROM document_embeddings
JOIN documents USING (id)
WHERE embedding <-> (SELECT embedding FROM pgv) < 0.5;"""
cur.execute(query)
# Fetch results
results = cur.fetchall()
# Print results in a nice format
for doc_title, doc_content in results:
print(f"Document title: {doc_title}")
print(f"Document text: {doc_content}")
print()复制
该查询首先获取标题为“pgvector”的文档的嵌入向量,然后使用相似性搜索来获取具有相似内容的文档。
请注意 <->
运算符,这是所有 pgvector 魔法发生的地方。这就是我们如何使用 HNSW 索引获得两个向量之间的相似性。“0.5”是一个相似性阈值,它将高度依赖于用例,并且需要在实际应用程序中进行微调。
返回结果时刻
当我们对导入的数据运行查询脚本时,我们看到相似性搜索找到了两个与 pgvector 相似的文档,其中之一就是 pgvector 本身。
❯ python3 query.py
Document title: pgvector
Document text: pgvector is a PostgreSQL extension that provides support for vector similarity search and nearest neighbor search in SQL.
Document title: pg_similarity
Document text: pg_similarity is a PostgreSQL extension that provides similarity and distance operators for vector columns.复制





