




前言
前情提要:最近做了不少 SQL 优化相关的工作,也将梁大师的《收获,不止 SQL 优化》啃了几遍,全书脉络清晰,由浅入深,层层递进,虽是针对 Oracle 的书籍,但笔者还是从此书中收获了不少。借此契机,我也理了一个针对 PostgreSQL 的优化思维脑图,借鉴了书中的思路,并加上了一些我个人的理解与经验。
前一篇讲了如何用改写 SQL 的方式减少开销,书接上回,让我们接着唠。
批量提交
批量提交的好处不言而喻,比如多条事务提交转化为一次提交,减少网络交互。批量提交有多种方式:
values (),(),()... insert into select .. copy
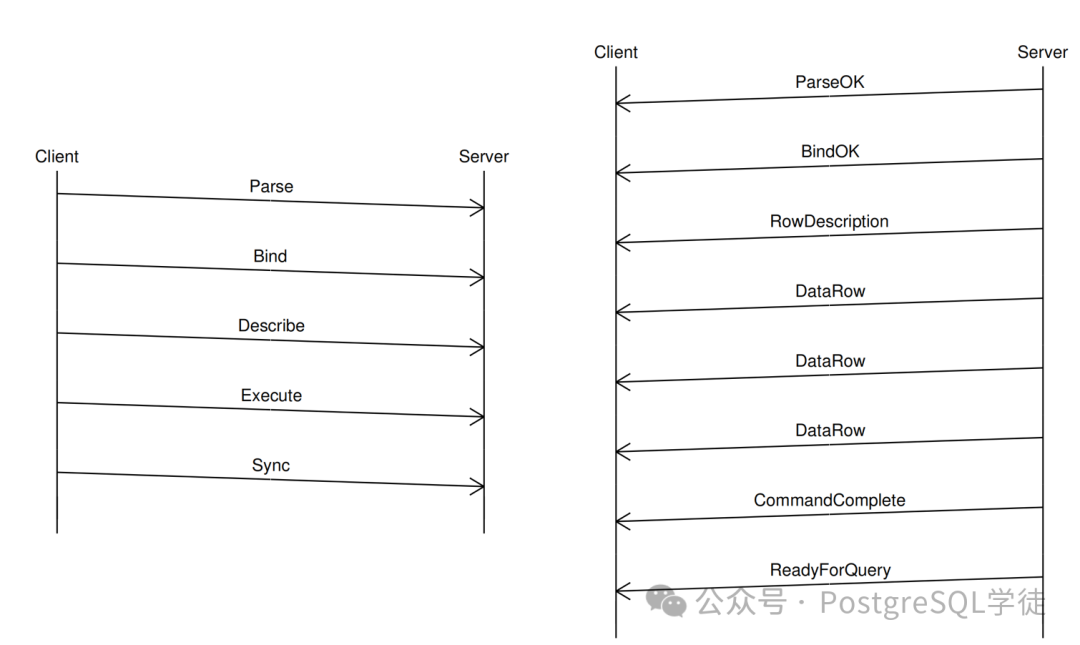
JDBC 也支持 reWriteBatchedInserts 参数,将多条 insert 转化为 insert .. values(),()的形式,另外 PreparedStatement 还支持 addBatch() 方法,其行为类似这样:
execute query
...
execute query
execute query
execute query
sync <-- wait for the response from the DB
但是这种方式数据库还是要分别处理每一条语句,只是将多次网络交互转化为了一次,最后发起 sync 消息,效率没有 reWriteBatchedInserts 高。
更多细节可以参考:https://stackoverflow.com/questions/47664889/jdbc-batch-operations-understanding/48349524#48349524
其次便是 FetchSize 了,控制着服务器执行完成之后,结果是一股脑全部返回给客户端,还是说批次返回
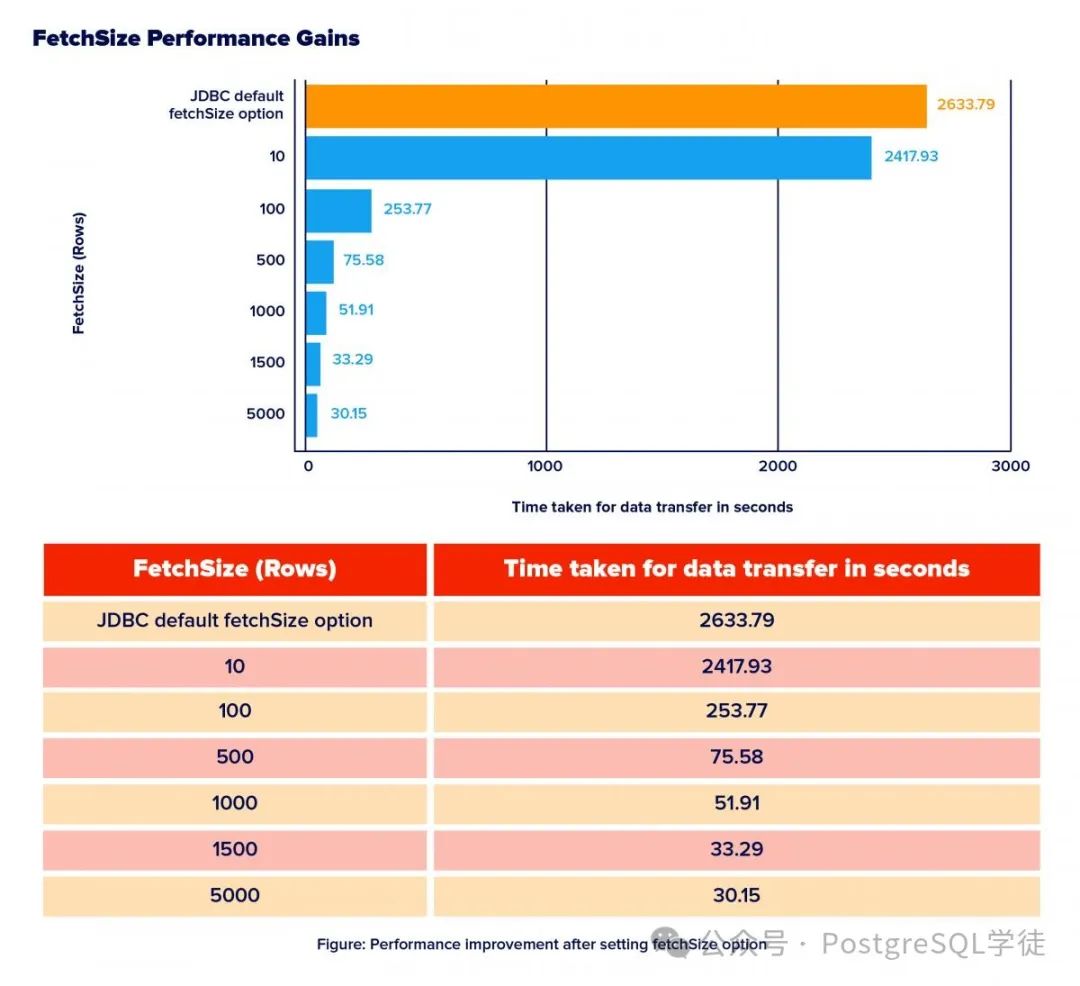
不难理解,FetchSize 越大,耗时越短,但是相应 OOM 的概率就越大。另外特别值得注意的是,如果采用 Simple Query Protocal,FetchSize 是不生效的,这一点很好验证,自己写一段 java 代码,同时配置 preferQueryMode 验证。
Another downside of the simple query protocol is that the client receives the whole result at once, regardless of the number of rows it may contain.
在 ExtendProtocal 里面,消息后面有个 row limit,其内容中还包含着 SQL 请求的要返回的最大行数,默认为 0,表示不限制。

缓存结果集
缓存结果集值得好好唠唠,也就是我们通常说的 CTE——Common Table Expressions,或者说 with 语句。
CTE 的好处很直观,以官网例子为例
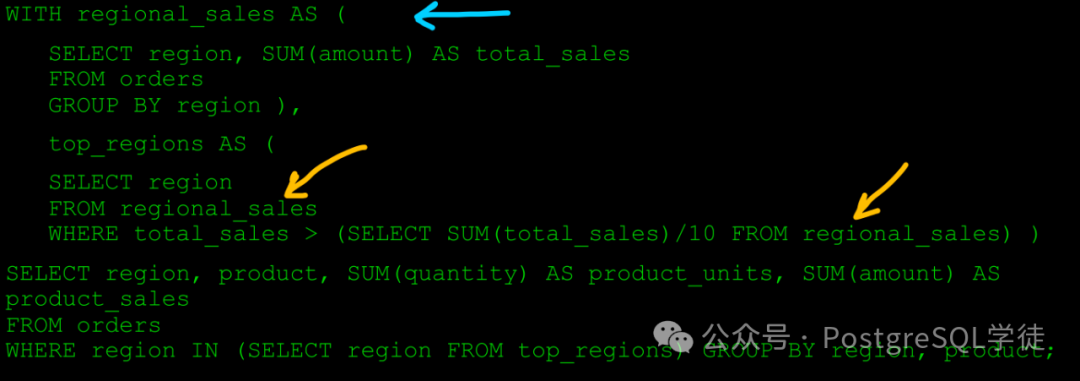
可读性 + 复用性,借助 CTE,我们可以将一些 SQL 进行改写,比如谓词下推,提前过滤数据,减少后续的计算量。其次 CTE 还可以实现递归,在 14 版本中还支持了 SEARCH DEPTH。
那么 CTE 有什么注意事项呢?让我们看个例子
postgres=# create table t1(id int,info text);
CREATE TABLE
postgres=# insert into t1 select n,md5(random()::text) from generate_series(1,1000000) as n;
INSERT 0 1000000
postgres=# create index on t1(id);
CREATE INDEX
postgres=# explain (buffers,analyze) with mycte as MATERIALIZED (select * from t1) select * from mycte where id = 99;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
CTE Scan on mycte (cost=18334.00..40834.00 rows=5000 width=36) (actual time=0.067..633.958 rows=1 loops=1)
Filter: (id = 99)
Rows Removed by Filter: 999999
Buffers: shared hit=8334, temp written=5737
CTE mycte
-> Seq Scan on t1 (cost=0.00..18334.00 rows=1000000 width=36) (actual time=0.013..173.929 rows=1000000 loops=1)
Buffers: shared hit=8334
Planning:
Buffers: shared hit=20 read=1
Planning Time: 0.267 ms
Execution Time: 641.108 ms
(11 rows)
在 12 版本以前,CTE 的行为和此例一样,很明显,虽然 id 列有索引,但是由于物化,id = 99 这个条件并没有内联到 CTE 中,导致 CTE SCAN 是全表扫描,那让我们看下 12 版本以后的样子
postgres=# explain (buffers,analyze) with mycte as (select * from t1) select * from mycte where id = 99;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Index Scan using t1_id_idx on t1 (cost=0.42..8.44 rows=1 width=37) (actual time=0.052..0.053 rows=1 loops=1)
Index Cond: (id = 99)
Buffers: shared hit=1 read=3
Planning:
Buffers: shared hit=23
Planning Time: 0.301 ms
Execution Time: 0.078 ms
(7 rows)
如果将 MATERIALIZED 关键字去掉,执行计划就要高效多了,使用了索引,因此对于 12 以前的版本,CTE 就要小心,优化器不是那么得聪明。
另外,在 14 以后,还支持了 Memoization,相较于 MATERIALIZED 更为智能,Materialize 节点只是简单地保存所有子节点返回的行,而 Memoize 则确保不同参数值返回的行分开保存。就像内存逐出一样,分为"冷端"和"热端",淘汰的数据从冷端逐出,内存大小受限于 work_mem × hash_mem_multiplier。
细心的读者可能发现了,上方存在 temp written,因为 CTE 的结果会保存在后端进程的本地内存中,如果 work_mem 够大,那么就不会涉及到磁盘溢出,老样子,要注意 OOM 的风险。
postgres=# set work_mem to '1GB';
SET
postgres=# explain (buffers,analyze) with mycte as MATERIALIZED (select * from t1) select * from mycte where id = 99;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
CTE Scan on mycte (cost=18334.00..40834.00 rows=1 width=36) (actual time=0.080..552.927 rows=1 loops=1)
Filter: (id = 99)
Rows Removed by Filter: 999999
Buffers: shared hit=8334
CTE mycte
-> Seq Scan on t1 (cost=0.00..18334.00 rows=1000000 width=37) (actual time=0.015..142.190 rows=1000000 loops=1)
Buffers: shared hit=8334
Planning Time: 0.086 ms
Execution Time: 577.407 ms
(9 rows)
另外一个耳熟能详的机制便是物化视图了,由于物化视图目前还不支持增量刷新 (pg_ivm 扩展限制颇多,基本不具备实操性),光是一个分区表不支持就劝退许多人了。

每次都得全量刷新,只不过支持 concurrently 不阻塞 DML 的形式进行刷新,但是其代价便是可能会膨胀,原理之前已经叙述过多次,感兴趣的同学翻翻过往文章。
小结
下一期让我们再聊聊 PL/pgSQL 的高级特性以及其他优化方式。
