





Oracle Database 23ai 来了,虽然目前只是云上可商用,但是 OP 有 FREE 版本可以进行开发。
本文将介绍 Oracle 23ai 的新特性之一: AI 向量搜索,的部分内容。
向量数据类型
23ai 新增向量数据类型,可以用于表示一系列的数值,这些数值可以代表不同的含义,比如在几何学中代表点的坐标,在机器学习中代表特征向量等。
示例:
创建一张订单表,并使用 VECTOR 字段类型。
-- vector data type
CREATE TABLE orders
(order_id INT, order_vector VECTOR);
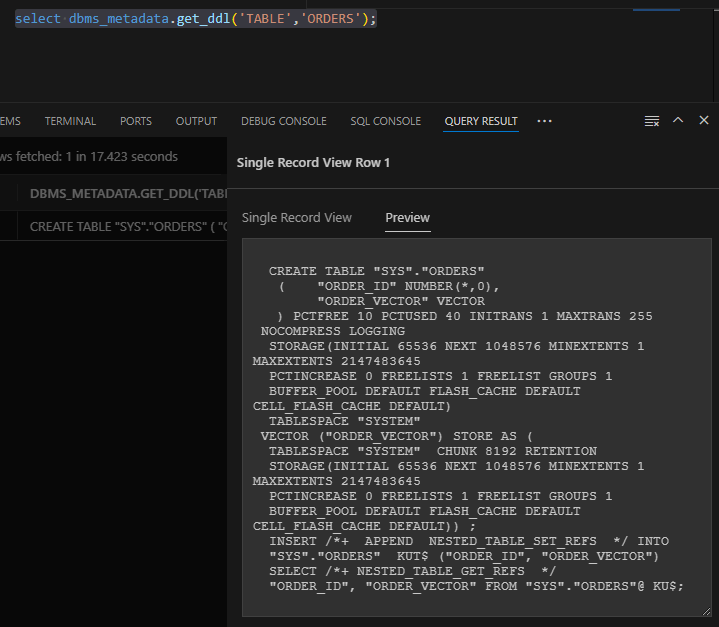
查看表定义:
SQL> select dbms_metadata.get_ddl('TABLE','ORDERS');
DBMS_METADATA.GET_DDL('TABLE','ORDERS')
--------------------------------------------------------------------------------
CREATE TABLE "SYS"."ORDERS"
( "ORDER_ID" NUMBER(*,0),
"ORDER_VECTOR" VE
这里被截断了,换个窗口查看。
插入数据:
insert into orders values (1, '[1, 2]'), (2, '[2, 2]'), (3, '[3, 3]');
查看数据:
SELECT * FROM ORDERS;
SQL> SELECT * FROM ORDERS;
ORDER_ID ORDER_VECTOR
___________ ______________________
1 [1.0E+000,2.0E+000]
2 [2.0E+000,2.0E+000]
3 [3.0E+000,3.0E+000]
向量内存池
向量内存池(Vector Memory Pool) 是在 SGA 中分配的内存,用于存储 HNSW (Hierarchical Navigable Small World) 向量索引和所有相关的元数据。它还用于加速倒置平面文件(IVF)索引的创建以及对具有IVF索引的基表的DML操作。
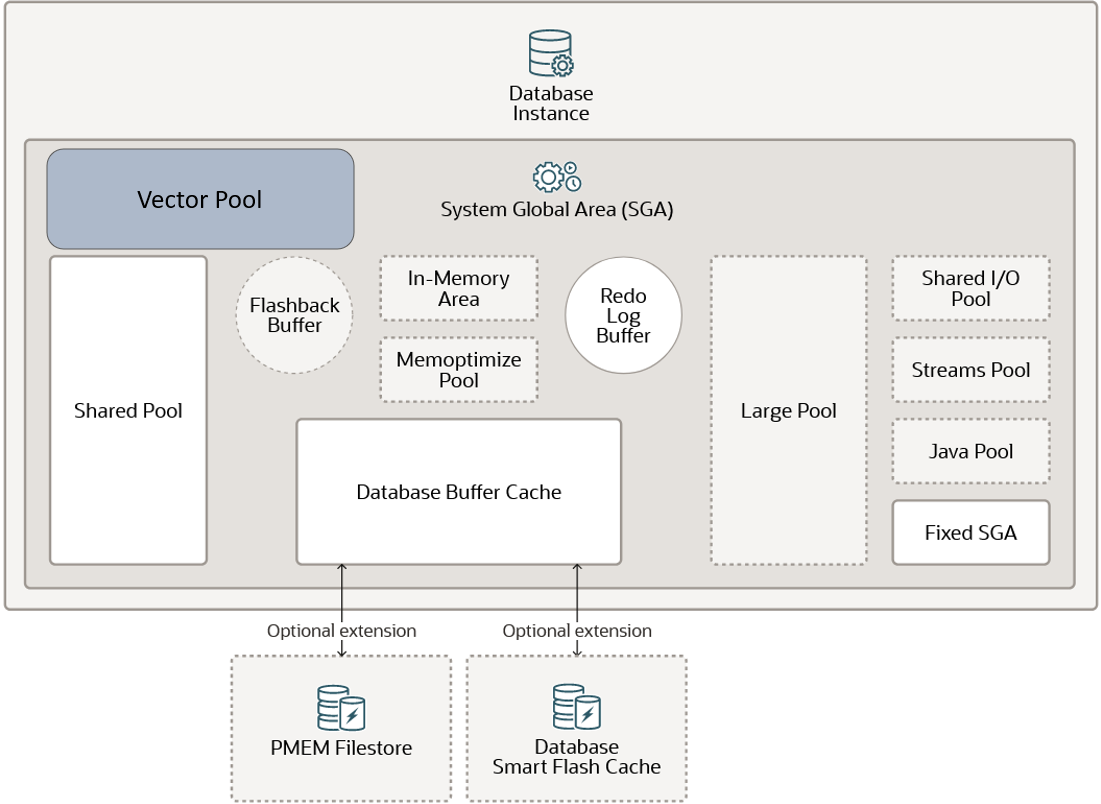
可以通过如下命令修改向量内存池的大小。
ALTER SYSTEM SET vector_memory_size=1G SCOPE=SPFILE;
show parameter vector_memory_size;
VECTOR_MEMORY_POOL 用于监视 向量内存池 的使用情况。
select CON_ID, POOL, ALLOC_BYTES/1024/1024 as ALLOC_BYTES_MB,
USED_BYTES/1024/1024 as USED_BYTES_MB
from V$VECTOR_MEMORY_POOL order by 1,2;

此外,启动数据库实例时,也可以看到向量内存区域的大小。
SQL> startup; ORACLE instance started. ... Vector Memory Area 1073741824 bytes
向量索引
向量索引是一类专门的索引数据结构,旨在使用高维向量加速相似度搜索。使用诸如聚集、分区和邻居图之类的技术来对表示相似项的向量进行分组,这大大减少了搜索空间,从而使搜索过程非常高效。
Oracle AI 向量搜索支持以下几种基于近似最近邻(ANN)搜索的向量索引方法:
- 内存中的邻居图向量索引 (In-Memory Neighbor Graph Vector Index)
- 邻居分区矢量索引 (Neighbor Partition Vector Index)
两者语法也有所区别:
-- INMEMORY NEIGHBOR GRAPH
CREATE VECTOR INDEX vector_index_name
ON table_name ( vector_column )
[ GLOBAL ] ORGANIZATION INMEMORY NEIGHBOR GRAPH
[ WITH ] [ DISTANCE metric name ]
[ WITH TARGET ACCURACY percentage_value ]
[ PARAMETERS ( TYPE
{ HNSW , { NEIGHBORS max_closest_vectors_connected
| M max_closest_vectors_connected }
, EFCONSTRUCTION max_candidates_to_consider
|
IVF , { NEIGHBOR PARTITIONS number_of_partitions
| SAMPLE_PER_PARTITION number_of_samples
| MIN_VECTORS_PER_PARTITION min_number_of_vectors_per_partition }
}]
[ PARALLEL degree_of_parallelism ]
-- NEIGHBOR PARTITIONS
CREATE VECTOR INDEX <vector index name>
ON <table name> ( <vector column> )
[GLOBAL] ORGANIZATION NEIGHBOR PARTITIONS
[WITH] [DISTANCE <metric name>]
[WITH TARGET ACCURACY <percentage value>
[PARAMETERS ( TYPE IVF, { NEIGHBOR PARTITIONS <number of partitions> | SAMPLE_PER_PARTITION
<number of samples> | MIN_VECTORS_PER_PARTITION <minimum number of vectors per partition>
})]]
[PARALLEL <degree of parallelism>];
示例:
在 ORDER 表的向量字段上创建索引。
CREATE VECTOR INDEX VIDX_ORDERS_1
ON orders ( order_vector )
ORGANIZATION INMEMORY NEIGHBOR GRAPH;
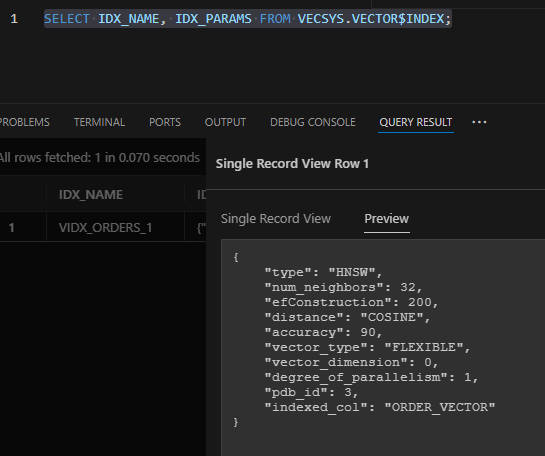
查看向量索引
Oracle Database 23ai 新增 Vector 系统视图,用于查看索引。
示例:
查看上面创建的索引 VIDX_ORDERS_1
SELECT IDX_NAME, IDX_PARAMS FROM VECSYS.VECTOR$INDEX;
关于向量的参数
23ai 中新增 3 个向量相关参数,分别是:
- vector_memory_size
初始化参数 VECTOR_MEMORY_SIZE 指定向量池的当前大小(在 CDB 级别)或 PDB 允许的最大向量池使用量(在 PDB 级别)。
- vector_index_neighbor_graph_reload
初始化参数 VECTOR_INDEX_NEIGHBOR_GRAPH_RELOAD 会在实例重启后通过后台任务自动逐一加载 HNSW 索引。
- vector_query_capture
初始化参数 VECTOR_QUERY_CAPTURE 用于启用和禁用查询向量的捕获。

总结
关于 23ai 中 AI Vector Search 的基础知识,先介绍到这里,希望对你有所帮助。
往期回顾
– END –

如果这篇文章为你带来了灵感或启发,就请帮忙点『赞』or『在看』or『转发』吧,感谢!(๑˃̵ᴗ˂̵)
