




Qwen1.5 介绍
https://qwenlm.github.io/zh/blog/qwen1.5/
Qwen1.5开源了包括0.5B、1.8B、4B、7B、14B和72B共计6个不同规模的Base和Chat模型,以及一个MoE模型,并同步放出了各尺寸模型对应的量化模型。
模型基础能力
在不同模型尺寸下,Qwen1.5 都在评估基准中表现出强劲的性能。特别是,Qwen1.5-72B 在所有基准测试中都远远超越了Llama2-70B,展示了其在语言理解、推理和数学方面的卓越能力。

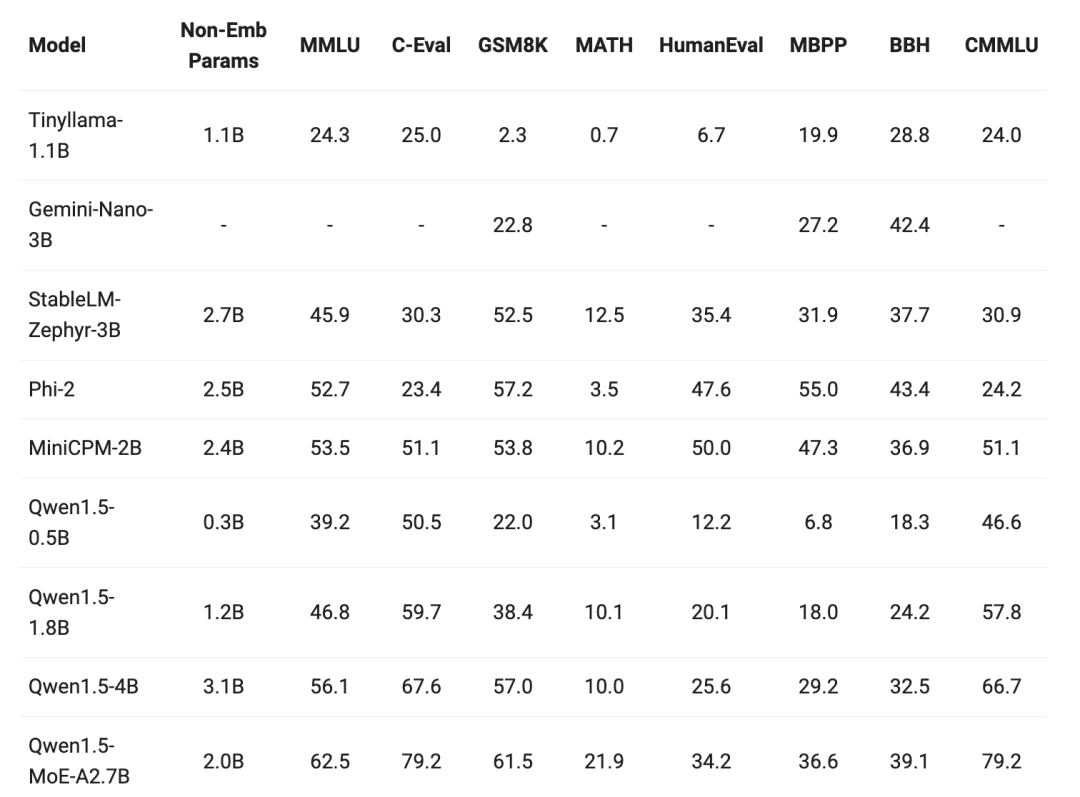
最近小型模型的构建也成为了热点之一,将模型参数小于 70 亿的 Qwen1.5 模型与社区中最杰出的小型模型进行了比较。结果如下:
Qwen1.5 使用
Qwen1.5 最大的不同之处,在于 Qwen1.5 与 HuggingFace transformers 代码库的集成。从 4.37.0 版本开始,您可以直接使用 transformers 库原生代码,而不加载任何自定义代码(指定trust_remote_code选项)来使用 Qwen1.5,像下面这样加载模型:
Qwen1.5-Chat加载与预测
加载模型
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-0.5B-Chat",
torch_dtype="auto",
device_map="cuda:0"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat")复制
对话输入与输出
prompt = "我今天很开心"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
response复制
Qwen1.5-Chat Lora微调
加载数据集
from datasets import Dataset
import pandas as pd
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer, GenerationConfig
# 将JSON文件转换为CSV文件
# https://github.com/datawhalechina/self-llm/blob/master/dataset/huanhuan.json
df = pd.read_json('./huanhuan.json')
ds = Dataset.from_pandas(df)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat")
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(f"<|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n<|im_start|>assistant\n", add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)复制
加载模型
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-0.5B-Chat",
torch_dtype="auto",
device_map="cuda:0"
)复制
Lora配置
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1# Dropout 比例
)
model = get_peft_model(model, config)复制
模型训练
args = TrainingArguments(
output_dir="./output/Qwen1.5",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=3,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()复制
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
