




TPC-C 介绍
TPC(Transaction Processing Performance Council,事务处理性能委员会)是由数十家会员公司创建的非盈利组织,总部设在美国。TPC的成员主要是计算机软硬件厂家,而非计算机用户,其功能是制定商务应用基准程序的标准规范、性能和价格度量,并管理测试结果的发布。
TPC-C是专门针对联机交易处理系统(OLTP系统)的规范,一般情况下我们也把这类系统称为业务处理系统。
目前在GaussDB的POC测试项目中,可以采用TPC-C的标准来进行标准化的性能测试。这里在进行的POC测试中所采用的工具为benchmarkSQL,属于符合满足TPC-C标准的开源软件,二者并没有从属关系,当然不同的DB需要通过其代码编译文件的形式来进行benchmarkSQL的适配。
TPC-C 概念
TPC-C 的五种事务
- 新订单(New-Order)
【事务内容】对于任意一个客户端,从固定的仓库随机选取 5-15 件商品,创建新订单,其中 1%的订单要由假想的用户操作失败而回滚。
【主要特点】中量级、读写频繁、要求响应快。
- 支付操作(Payment)
【事务内容】对于任意一个客户端,从固定的仓库随机选取一个辖区及其内用户,采用随机的金额支付一笔订单,并作相应历史纪录。
【主要特点】轻量级,读写频繁,要求响应快。
- 订单状态查询(Order-Status)
【事务内容】对于任意一个客户端,从固定的仓库随机选取一个辖区及其内用户,读取其最后一条订单,显示订单内每件商品的状态。
【主要特点】中量级,只读频率低,要求响应快。
- 发货(Delivery)
【事务内容】对于任意一个客户端,随机选取一个发货包,更新被处理订单的用户余额,并把该订单从新订单中删除。
【主要特点】1-10 个批量,读写频率低,较宽松的响应时间。
- 库存状态查询(Stock-Level)
【事务内容】对于任意一个客户端,从固定的仓库和辖区随机选取最后 20 条订单,查看订单中所有的货物的库存,计算并显示所有库存,于随机生成域值的商品数量。
【主要特点】重量级,只读频率低,较宽松的响应时间。
TPC-C 的基准模型
TPC-C 是由事务处理委员会定义的OLTP基准。它由9张表组成并且与10 个外键关系进行连接。除Item表外,所有内容都按仓库数(W)按基数进行缩放, 在数据库的初始加载期间生成。其基准模型如下图所示:
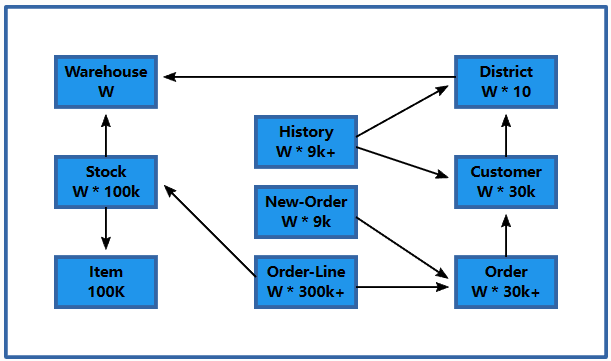
TPC-C 的九张表
上图中的基准模型架构由2.1中的五种不同的事务组成,这些事务共同产生了九张表,这九张表的可支持的读写模式如下:
- Item 为read only的表;
- Warehouse, District, Customer and Stock 为read/write的表;
- New-Order 为可insert、read、delete的表;
- Order,Order-Line 为可insert的表,但插入的数据会有延迟更新,并且之后会很少进行读取;
- History 为inset only的表;
这些表在进行创建后可通过数据库进行查询,如下图:

【备注】图中实际为十张表,bmsql_config为配置表,不参与实际业务。
BenchmarkSQL安装
测试环境
本次测试依然通过腾讯云购买的单机PanWeiDB单实例上进行压测测试,并且设置了PanWeiDB的最佳参数优化配置,但在实际生产环境中,依然建议通过其它机器部署进行性能压测,单机配置为8C/32G/100G的物理配置,操作系统为CentOS 7.6。本文档重在讲解benchmark测试方案的部署配置等,不涉及如何调优,但在最后会通过华为官方材料进行一系列调优方式的说明。
本次测试所需要的YUM依赖或者软件包如下:
- Yum依赖包
- Benchmarksql安装包:benchmarksql-5.0.zip,下载地址:BenchmarkSQL download | SourceForge.net
- Ant安装包:apache-ant-1.10.12-bin.tar,Ant下载地址:Apache Ant - Welcome
- Htop安装包:htop-3.2.0.tar,下载地址:https://github.com/htop-dev/htop/releases
- JDK包:jdk-8u341-linux-x64.tar,JDK下载地址:Java Archive Downloads - Java SE 8u211 and later (oracle.com)
- R语言包:R-3.6.3.tar,下载地址:The Comprehensive R Archive Network (r-project.org)
将以上所有需安装的安装包统一上传到/soft/目录下。
安装前准备
安装benchmarkSQL且生成report报告,需要相关功能组件支持,如YUM源依赖包、htop、java、ant、R语言包等,将所需要的安装包均上传到 /soft 目录下,下面介绍相关的依赖组件等的下载及安装方法。
安装YUM源依赖包
确保系统安装包挂载后依次进行如下yum源的安装:
yum install gcc glibc-headers gcc-c++ gcc-gfortran readline-devel libXt-devel pcre-devel libcurl libcurl-devel -y
yum install ncurses ncurses-devel autoconf automake zlib zlib-devel bzip2 bzip2-devel xz-devel -y
yum install pango-devel pango libpng-devel cairo cairo-devel -y
安装htop
mkdir /soft
cd /soft
xz -dk htop-3.2.0.tar.xz
tar xvf htop-3.2.0.tar
cd htop-3.2.0
./autogen.sh && ./configure && make && make install
htop
安装java和ant
cd /usr
tar -xzvf /soft/jdk-8u341-linux-x64.tar.gz
tar -xzvf /soft/apache-ant-1.10.12-bin.tar.gz
cat >> ~/.bash_profile << EOF
export JAVA_HOME=/usr/jdk1.8.0_341
#https://benchmarksql.readthedocs.io/en/latest/
export ANT_HOME=/usr/apache-ant-1.10.12
export PATH=/usr/jdk1.8.0_341/bin:$PATH:/usr/apache-ant-1.10.12/bin
EOF
source ~/.bash_profile
java -version
ant -version
安装R语言包
cd /soft/
tar -zxf R-3.6.3.tar.gz
cd R-3.6.3
./configure && make && make install
R
【备注】R语言编译验证是否成功,输入R操作后如下图所示,输入q() 即可退出R语言管理界面。
安装BenchmarkSQL
步骤1 解压benchmarksql压缩包并并将原jdbc进行备份;
cd /soft
unzip benchmarksql-5.0.zip
cd /soft/benchmarksql-5.0/lib/postgres
mv postgresql-9.3-1102.jdbc41.jar postgresql-9.3-1102.jdbc41.jar.bak
步骤2 将PanWeiDB数据库安装包上,依次对PanWeiDB_1.0.0_CentOS7_x86.tar和PanWeiDB-1.0.0-CENTOS-64bit-Jdbc.tar包进行解压,将解压后的postgresql.jar进行替换为postgresql.jar postgresql-9.3-1102.jdbc41.jar;
cp postgresql.jar postgresql-9.3-1102.jdbc41.jar
步骤3 ant编译
cd /soft/benchmarksql-5.0
ant
【备注】ant编译为压测后生成html报告的必要步骤。
BenchmarkSQL 压测
创建压测数据库及数据库账户
gsql -d postgres -p 17700 -r
create user tpcc with password 'PanWei@123' sysadmin;
create database tpccdb with owner tpcc;
gsql -d tpccdb -p 17700 -U tpcc -W PanWei@123 -r
【备注】性能压测工具如sysbench和benchmarksql等,必须要求压测的用户权限具备sys的权限。
配置props.pg
props.pg为benchmarksql的测试PanWeiDB数据库性能的配置文件,这里需要根据实际的测试需求进行相对应的配置。
cd /soft/benchmarksql-5.0/run
cp props.pg my.properties
vim my.properties
db=postgres driver=org.postgresql.Driver conn= jdbc:postgresql://172.21.32.7:17700/tpccdb # 根据实际的数据库节点情况修改IP、端口号和测试库名; user=tpcc # 测试账户 password=PanWei@123 # 测试账户对应的密码 warehouses=300 # 数据仓库数W,1W=76823KB,仓库数根据实际需要自定义设置; loadWorkers=6 # 数据仓库在加载数据时所启用的并发进程数,建议不超过CPU核数; terminals=100 # 压测时并发端数量; //To run specified transactions per terminal- runMins must equal zero runTxnsPerTerminal=0 # 每个terminal运行的事务数量,该参数不能与runMins同时设置; //To run for specified minutes- runTxnsPerTerminal must equal zero runMins=5 # 实际压测运行的时间,该参数不能与runTxnsPerTerminal同时设置; //Number of total transactions per minute limitTxnsPerMin=3000 # 每分钟测试的事务数量; //Set to true to run in 4.x compatible mode. Set to false to use the //entire configured database evenly. terminalWarehouseFixed=true # 每个terminal是否绑定固定的warehouse。设置为true可兼容benchmarksql 4.x模式运行,表示每个terminal将与固定的warehouse绑定进行压测,设置为false时表示可以均匀使用数据库整体配置进行压测。TPCC规定每个终端都必须有一个绑定的仓库,所以一般使用默认值true。 //The following five values must add up to 100 //The default percentages of 45, 43, 4, 4 & 4 match the TPC-C spec newOrderWeight=45 paymentWeight=43 orderStatusWeight=4 deliveryWeight=4 stockLevelWeight=4 【备注】下面五个值的总和必须等于100,默认值为:45, 43, 4, 4 & 4 ,与TPC-C测试定义的比例一致,实际操作过程中,可以调整比重来适应各种场景。 // Directory name to create for collecting detailed result data. // Comment this out to suppress. resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tS # 测试结果生成的目录,默认即可; osCollectorScript=./misc/os_collector_linux.py # 操作系统性能信息收集的脚本 osCollectorInterval=1 # 操作系统收集间隔时间,默认为1秒; //osCollectorSSHAddr=user@dbhost # 操作系统收集所对应的主机,如果对本机数据库进行测试,该参数保持注销即可,如果要对远程服务器进行测试,请填写用户名和主机名。 osCollectorDevices=net_eth0 blk_sda #操作系统中被收集服务器的网卡名称和磁盘名称; |
创建测试数据
cd /soft/benchmarksql-5.0/run
./runDatabaseBuild.sh my.properties
创建测试数据后生成对应的表及数据量情况如下图:

这里创建生成的数据量符合基准测试模型中设定的对应值,即基于warehouse=300仓的基础上,各个表按照模型比例进行创建数据量,模型如下图所示:

【备注】可通过逻辑备份恢复的方式(gs_dumpall/gs_restore)提前备份好创建的测试数据,若数据被破坏可先清理数据后再恢复所创建好的数据,避免再次创建测试数据所耗费的时间。在实际性能测试中warehouse常常设置为300/500/1000等值,基于实际情况设置。
性能压测及指标解读
cd /soft/benchmarksql-5.0/run
./runBenchmark.sh my.properties
性能压测结果如下图所示:

压测的相关结果说明如下:
- Running Average tpmTOTAL:每分钟平均执行事务数(所有事务);
- Current tpmTOTAL:当前测试总事务数;
- Memory Usage:客户端内存使用情况;
- Measured tpmC (NewOrders) :每分钟执行的NewOrders事务数量,这里的值是Measured tpmTOTAL的将近一半左右是因为配置参数中设置的newOrderWeight参数比重为45%,即所占总事务数量将的45%,该指标值越高代表性能越好;
- Measured tpmTOTAL:每分钟执行的五种类型总事务数量,该指标直接证明当前环境的总的事务处理能力,该指标值越高代表性能越好;
- Session Start:开始压测的时间:
- Session End:结束压测的时间;
- Transaction Count:单位时间内执行的事务总数量,这里的总数量主要取决于你设定的配置参数中的runMins以及压测的tpmTOTAL值;
所以,在这里需要重点关注tpmC和tpmTOTAL这两个值,值越高则代表性能越好。
测试报告
BenchmarkSQL通过安装的ant和R语言包等工具可支持生成格式为csv、png和html的压力测试报告,命令操作如下所示:
./generateReport.sh my_result_2023-11-09_111239
其中,csv文件在 data/ 目录中,包括blk_sda.csv net_ens33.csv result.csv runInfo.csv sys_info.csv tx_summary.csv 共六个表格文件,png文件在my_result开头的目录内,包括blk_sda_iops.png cpu_utilization.png dirty_buffers.png net_ens33_iops.png tpm_nopm.png blk_sda_kbps.png latency.png net_ens33_kbps.png 共八个图片文件。
这里需要重点查看的是 report.html 文件,将其以及所有png文件一并下载到本地即可通过浏览器打开html文件进行查询,测试报告的report.zip文件可自行下载到本地进行样例查阅,如下图所示:
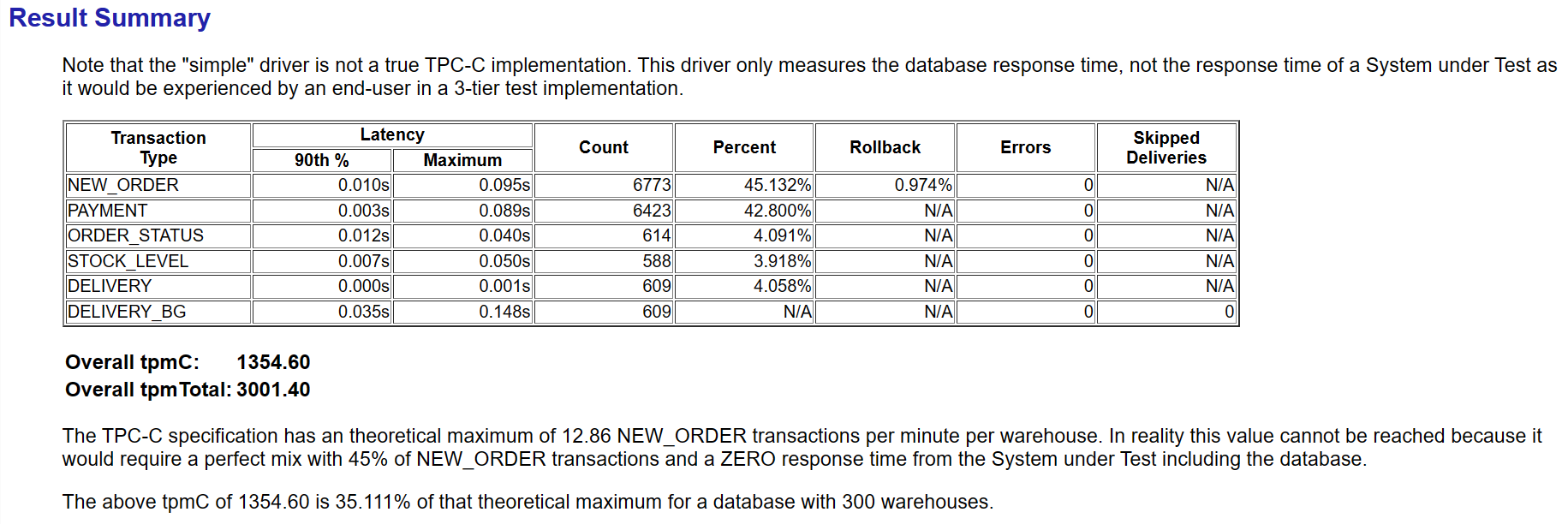


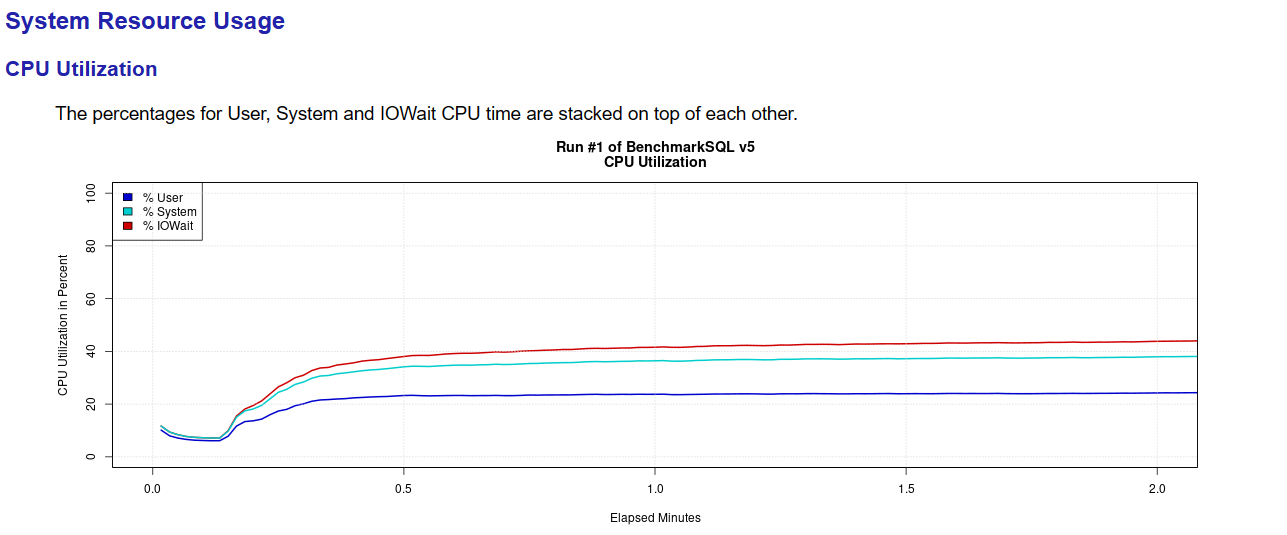
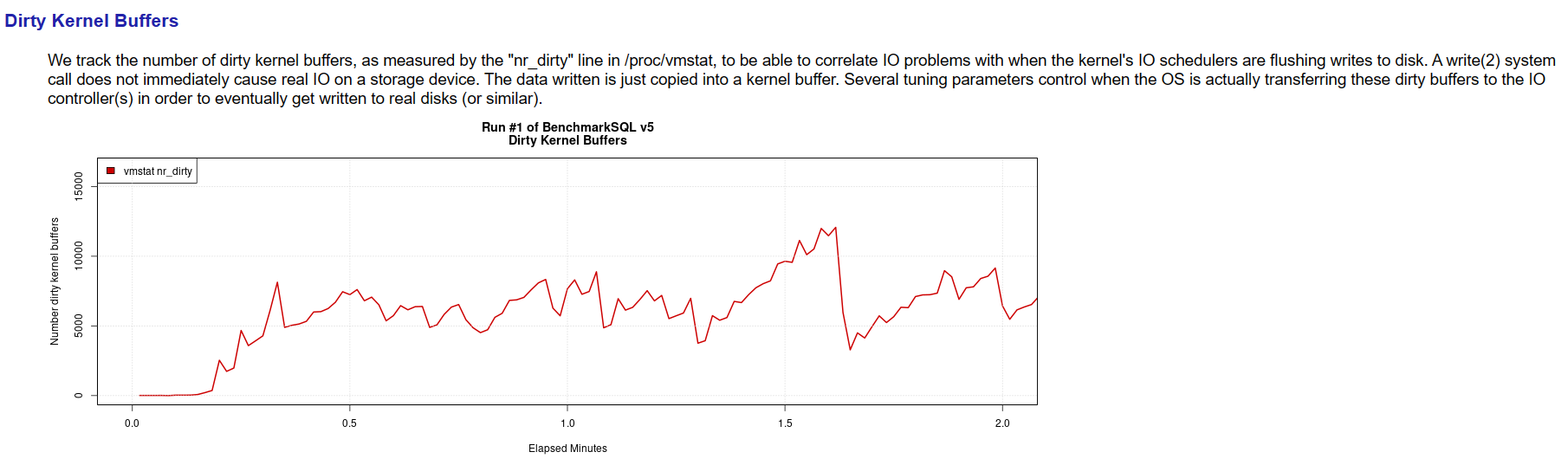

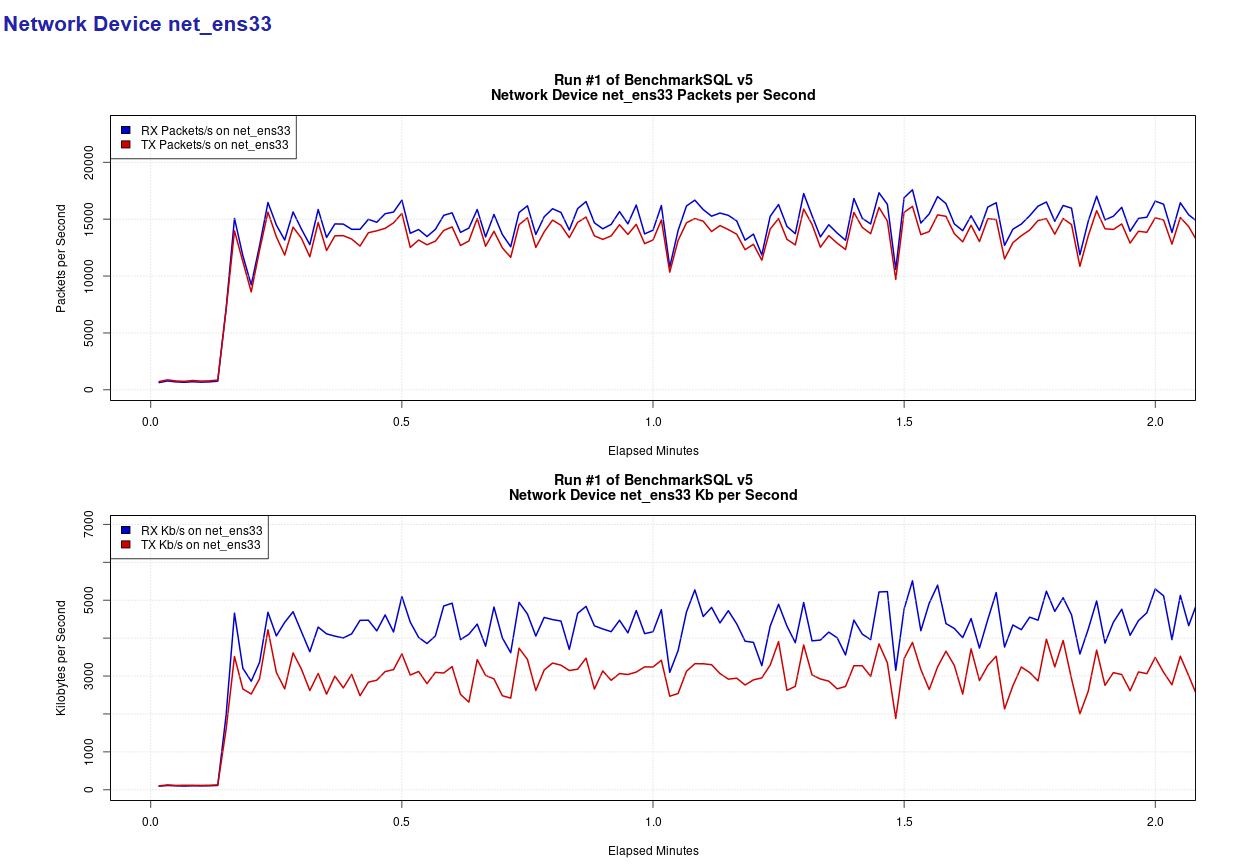
通过report.html文件不仅可查看测试相关的性能指标,同时可查看与整体性能指标相关的瓶颈类的指标,如:
- 每分钟事务数量和延迟情况
- 系统的CPU压力情况
- 内核缓冲区的情况
- s磁盘的io情况
- 网卡的延迟情况
以此,可根据report的报告情况分析影响整体性能指标的瓶颈出现在哪里,便于有针对性的进行策略调优。
关于sql.common
在benchmarksql文件中的sql.common目录下,会看到一些关于创建、删除的SQL文件,其中tableCreates.sql文件较为重要,在创建测试数据中,工具将优先调用该SQL文件进行10张业务表的创建,原文件如下所示:
[root@node sql.common]# cat tableCreates.sql create table bmsql_config ( cfg_name varchar(30) primary key, cfg_value varchar(50) ); create table bmsql_warehouse ( w_id integer not null, w_ytd decimal(12,2), w_tax decimal(4,4), w_name varchar(10), w_street_1 varchar(20), w_street_2 varchar(20), w_city varchar(20), w_state char(2), w_zip char(9) ); create table bmsql_district ( d_w_id integer not null, d_id integer not null, d_ytd decimal(12,2), d_tax decimal(4,4), d_next_o_id integer, d_name varchar(10), d_street_1 varchar(20), d_street_2 varchar(20), d_city varchar(20), d_state char(2), d_zip char(9) ); create table bmsql_customer ( c_w_id integer not null, c_d_id integer not null, c_id integer not null, c_discount decimal(4,4), c_credit char(2), c_last varchar(16), c_first varchar(16), c_credit_lim decimal(12,2), c_balance decimal(12,2), c_ytd_payment decimal(12,2), c_payment_cnt integer, c_delivery_cnt integer, c_street_1 varchar(20), c_street_2 varchar(20), c_city varchar(20), c_state char(2), c_zip char(9), c_phone char(16), c_since timestamp, c_middle char(2), c_data varchar(500) ); create sequence bmsql_hist_id_seq; create table bmsql_history ( hist_id integer, h_c_id integer, h_c_d_id integer, h_c_w_id integer, h_d_id integer, h_w_id integer, h_date timestamp, h_amount decimal(6,2), h_data varchar(24) ); create table bmsql_new_order ( no_w_id integer not null, no_d_id integer not null, no_o_id integer not null ); create table bmsql_oorder ( o_w_id integer not null, o_d_id integer not null, o_id integer not null, o_c_id integer, o_carrier_id integer, o_ol_cnt integer, o_all_local integer, o_entry_d timestamp ); create table bmsql_order_line ( ol_w_id integer not null, ol_d_id integer not null, ol_o_id integer not null, ol_number integer not null, ol_i_id integer not null, ol_delivery_d timestamp, ol_amount decimal(6,2), ol_supply_w_id integer, ol_quantity integer, ol_dist_info char(24) ); create table bmsql_item ( i_id integer not null, i_name varchar(24), i_price decimal(5,2), i_data varchar(50), i_im_id integer ); create table bmsql_stock ( s_w_id integer not null, s_i_id integer not null, s_quantity integer, s_ytd integer, s_order_cnt integer, s_remote_cnt integer, s_data varchar(50), s_dist_01 char(24), s_dist_02 char(24), s_dist_03 char(24), s_dist_04 char(24), s_dist_05 char(24), s_dist_06 char(24), s_dist_07 char(24), s_dist_08 char(24), s_dist_09 char(24), s_dist_10 char(24) ); |
面对不同的数据库模式如集中式和分布式等,可通过修改以上的构表语句来构建不同的测试表,这里可支持自定义创建测试的表结构,按需设置即可。
关于TPC-C的性能调优策略
因PanWeiDB是基于OpenGauss的基础上进行研发,所以若需要对PanWeiDB进行性能测试调优,建议可参考官方网址连接:性能调优 - TPCC性能调优测试指导 - 《华为 openGauss (GaussDB) v2.1 使用手册》 - 书栈网 · BookStack ,在里面有关于一些OS层面上的调优策略,如IO瓶颈问题,网络瓶颈问题、绑核操作、BIOS设置、前置软件安装等的具体指导,这里就不在一一赘述,供学习使用!
