




说到大数据仓库技术,不得不提ETL,ETL一词较常用在数据仓库,但其对象并不限于数据仓库。可以说是非常重要的一个环节,简单介绍一下ETL数据抽取比对的方法。
什么是ETL
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
全量抽取
全量抽取就是完整复制,比较简单,没有什么需要说的,大部分情况是增量同步。
增量抽取
增量抽取是指基于上次抽取以后,捕捉数据库中的新增、修改、删除的数据变化。在增量抽取时一般不允许影响业务系统的稳定性,所以不能进行锁表或大规模的数据查询。
触发器方案
在业务系统中建立插入、修改、删除三个触发器,每当数据变化时向临时表中添加数据,这样直接可以取到相应的变化量数据,但缺点是会对数据源系统造成侵入,影响数据源系统的性能。
时间戳方案
基于递增数据比较的增量数据捕获方式,在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值,进行数据抽取时,通过比较系统时间与时间戳字段的值来决定抽取哪些数据。这个方案无法对比出被删除的数据,同时也对源系统有入侵性,因为要增加时间戳字段,并且要求数据修改的时候更新时间戳字段。
哈希(Hash)对比方案
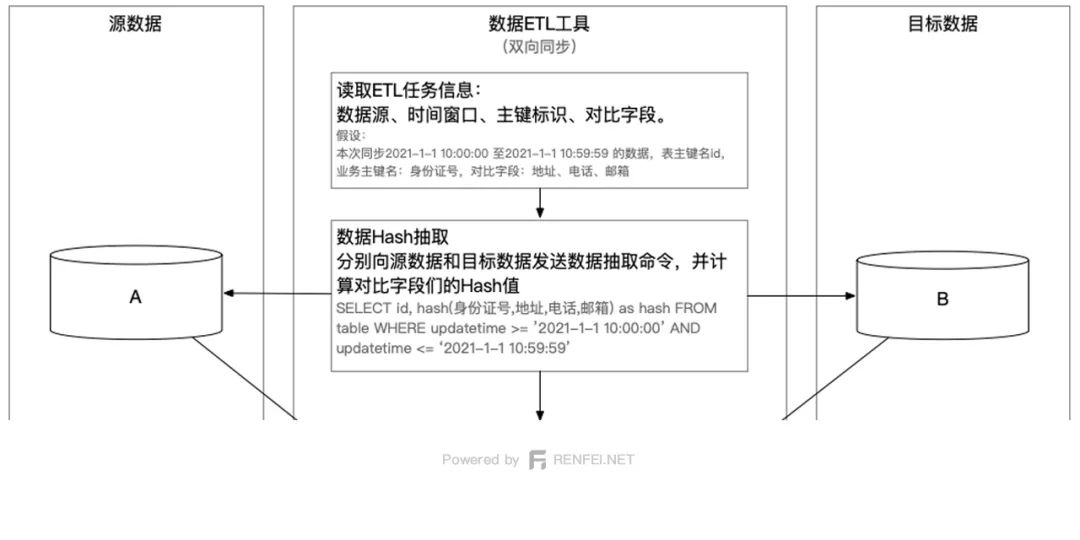
这个方案是我接下来要重点说的,先看我画的一张图,然后慢慢解释各个节点都是怎么做的:
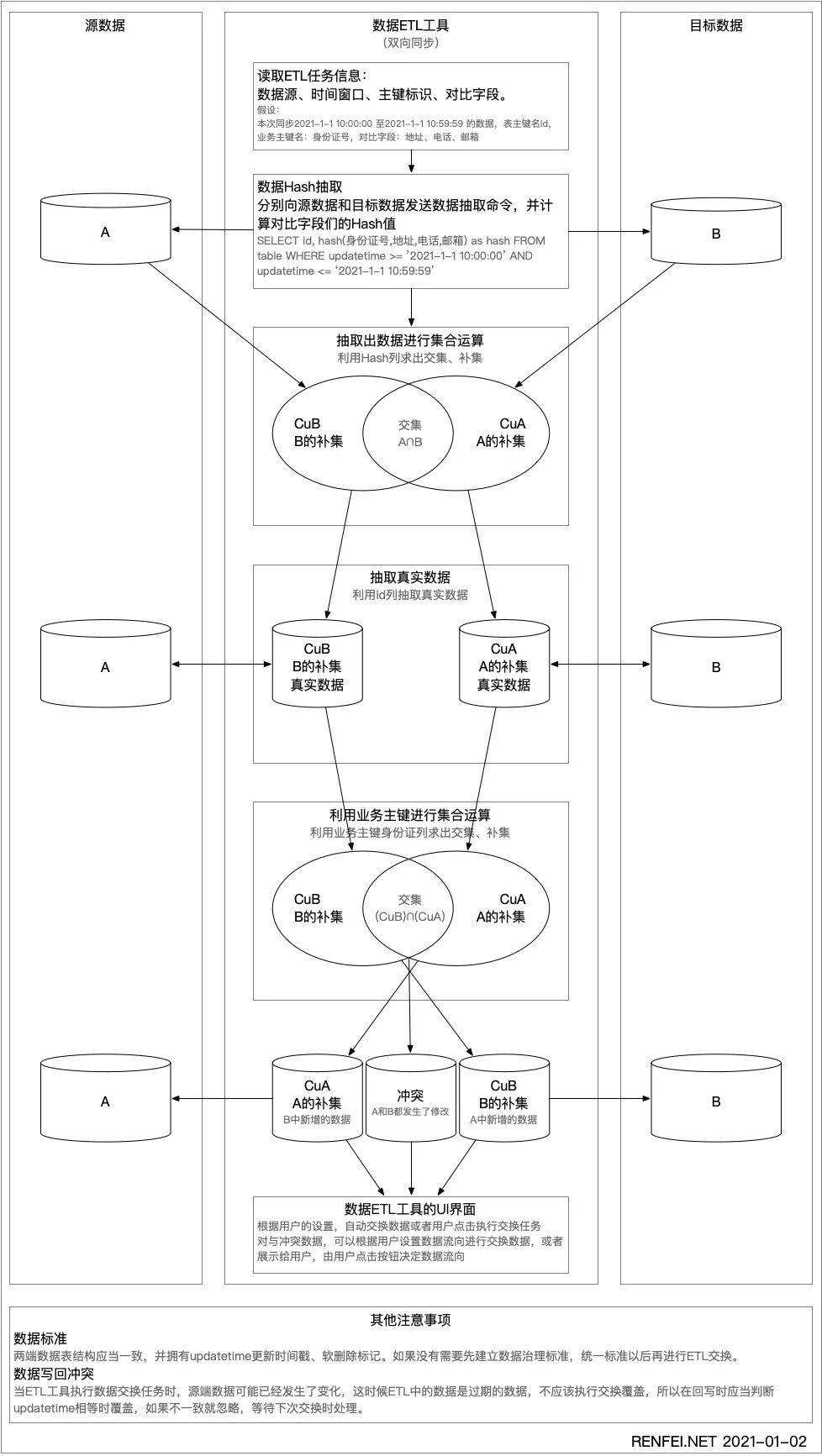
首先获取要对比的时间窗口、对比的字段,注意一定要在同一的一个数据窗口范围内对比,否则是没有意义的,比较常见的是在时间维度上做统一的对比窗口,比如对比一天之内的数据。
然后分别向源数据端和目标端数据库发送一个SQL,取出主键(例如id)和对比字段们的Hash值,我们就可以得到在一个统一数据窗口内的双方主键和对比列的Hash伪列。


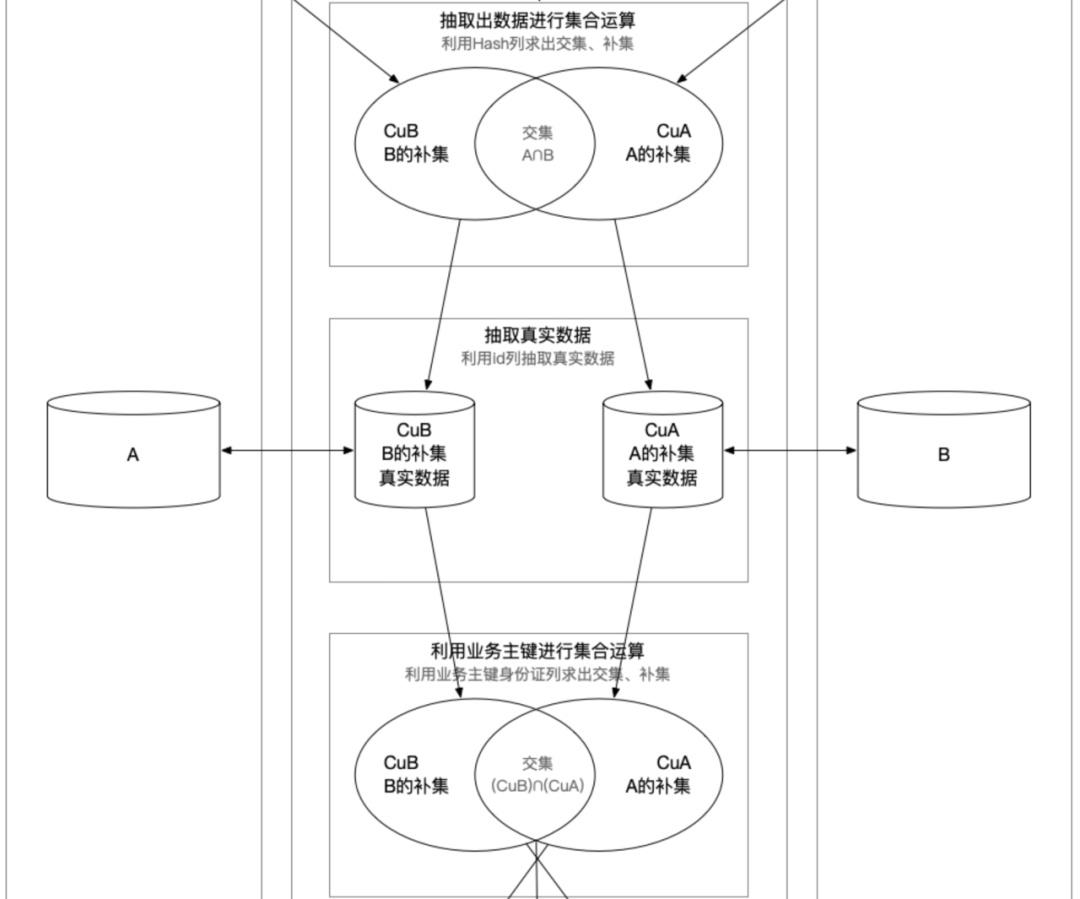
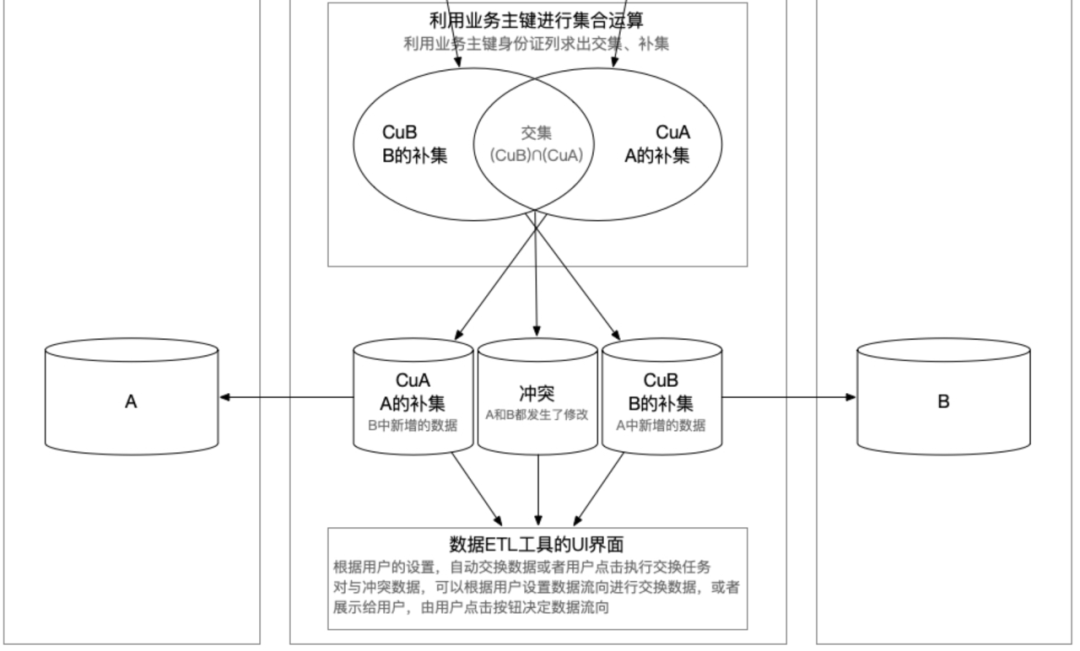
那删除的数据怎么识别出来呢,其实在部署ETL工具之前,就需要先建立数据标准规范,也就是数据治理,里面就规定必须要有删除标记,更新标记。
日志方案
没有数据治理的情况
在上面的三个方案中,我们都会要求数据源做相应的修改,比如增加触发器、增加时间戳、增加删除字段,但往往在现实中,很多数据源不允许我们修改他们的数据结构,或者不能配合我们做适配。
这种情况下,我们想要识别出数据的增删改,就需要在我们ETL工具内部建立一个镜像机制,也就是给数据源一个快照,然后对比上一次的快照,找出增删改的数据,这种方式虽然入侵性几乎为零,但带来的牺牲就是执行效率上的下降,毕竟需要大量数据的迁移,会影响原有系统的稳定性,而且也需要保存和管理镜像快照。实在没有办法的情况下只能牺牲效率使用这种方案。

点个“在看”
鼓励鼓励
↓↓↓
