





在文档处理和自动化领域,将文档分类并组织到预定义的类别中是很常见的用例。例如,一个组织可能有一个流程,该流程先获取文档,然后将这些文档分为“发票”、“合同”、“报告”等不同的类别。Azure AI 文档智能自定义分类模型可满足这些需求,并提供一种强大的方法来使文档管理井然有序。
文档智能( Document Intelligence )是一种基于云的 Azure AI 服务,它使用机器学习模型在应用程序和工作流中实现文档处理自动化。新用户和不熟悉文档智能( Document Intelligence )功能的用户如果有兴趣可以使用文档智能工作室开启探索,这是一种在线工具,无需编写任何代码即可直观地探索、理解、训练和实现文档智能服务的功能。然而,更高级的用例和集成可能需要以编程方式与文档智能服务进行交互,这可以使用文档智能 REST API 或适用于 .NET、Java、JavaScript 和 Python 的 SDK 来实现。在本文中,我们将重点介绍如何使用 Python(数据科学和机器学习开发人员中最流行的语言之一)构建自定义分类模型。
想要以编程方式创建自定义分类模型的用户可以利用 azure-sdk-for-python 存储库中现有的sample_classify_document.py 示例代码。但是,要使此示例脚本正常运行,分类器训练数据集必须已经包含每个文档的ocr.json文件。光学字符识别(OCR)是将扫描文档转换为可编辑和可搜索数据的关键步骤,虽然 Azure AI 文档智能工作室在使用可视化界面构建自定义分类模型时会在后台自动生成 OCR 文件,但使用 Python SDK 的用户可能会由于缺乏此内置功能而感到十分困惑。

文档智能 Python SDK 为从表单和文档中提取信息提供了一套强大的工具。然而,它缺乏从布局分析结果生成ocr.json文件的方法,这是一个在文档智能工作室中完全集成并自动处理的功能。
如此处的文档说明所述,可以通过使用文档智能的预构建Layout模型分析每个训练文档并将结果保存在适当的 API 响应格式中来创建所需的 ocr.json 文件。现有一个示例 Python 脚本sample_analyze_layout.py ,但由于 SDK 的布局结果对象的结构与 API 的布局结果对象不同,因此没有特定的方法通过使用 Python SDK 生成所需的 ocr.json 文件。这篇文章深入探讨了我们开发的手动编码此过程的自定义解决方案,有效解决了微软社区中讨论的常见问题。


为了弥合这一差距并以正确的格式通过编程创建 ocr.json 文件,我们使用文档智能 Python SDK 中提供的鲜为人知的回调方法通过自定义代码来访问 API 布局结果对象。我们开发了一个自定义分类器代码,用于模拟文档智能工作室执行的 OCR 文件创建过程。该代码利用 Python SDK 从文档中提取文本和结构数据,然后将此信息格式化为 OCR 文件所需的 JSON 结构。

自定义分类器代码包含几个关键步骤:
1. 准备文档:
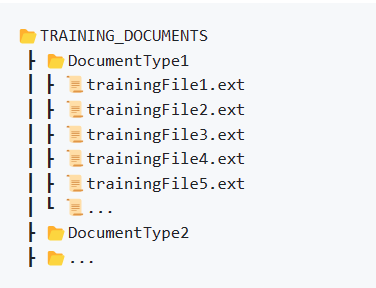
首先收集您要分析的文档。可以是各种格式,例如 PDF、Word 文档或图像。您可以参考此处的文档说明,全面地了解支持的文档类型。另外,要确保它们位于单独的“训练文件夹”中,代码将引用该文件夹结构:
🔗 https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/how-to-guides/build-a-custom-model?view=doc-intel-3.0.0#custom-model-input-requirements
2. 使用 Azure AI 文档智能 Layout 模型进行文档分析:
利用 Azure 文档智能 Layout 模型分析文档。这是通过运行 analyze_layout.py 来完成的,它会遍历访问指定目录(TRAINING_DOCUMENTS ) 中的文档,并使用 Azure AI 文档智能分析每个文档。它将结果与原始文档一起保存在 .ocr.json 文件中。这种格式镜像文档智能工作室的 OCR 输出,保持一致性和兼容性。
# Use begin_analyze_document to start the analysis process, and use a callback in order to recieve the raw responsewith open(document_file_path, "rb") as f:poller = document_intelligence_client.begin_analyze_document("prebuilt-layout", analyze_request=f, content_type="application/octet-stream", cls=lambda raw_response, _, headers: create_ocr_json(ocr_json_file_path, raw_response))// ... other code ...# Callback function to save the API raw response as .ocr.json filedef create_ocr_json(ocr_json_file_path, raw_response):with open(ocr_json_file_path, "w") as f:f.write(raw_response.http_response.body().decode("utf-8"))print(f"\tOutput saved to {ocr_json_file_path}")
3. 将包含标记数据的文档上传到 Azure Blob 存储容器:
这需要通过运行 upload_documents.py 来完成,它将上传所有训练文档,同时上传被用来构建分类器以引用每个文档的 .ocr.json 文件和 .jsonl 文件。.jsonl 文件使我们能够批量处理多个文档,提高训练的效率。
4. 构建分类器:
build_classifier.py 脚本通过使用 .jsonl 文件中的文档类型和标记数据构建自定义文档分类器。它利用 DocumentIntelligenceAdministrationClient 和 BlobServiceClient 类与文档智能和 Azure Blob 存储服务交互,以检索和处理在上一步中上传的训练数据。完成后,它会打印结果,包括分类器 ID、API 版本、描述和用于训练的文档类别。
5. 对文档进行分类:
classify_document.py 利用 DocumentIntelligenceClient 类使用经过训练的文档分类器对文档进行分类。它一次分析一个文档,并返回文档类型以及置信度分数。

虽然 Python SDK 没有为 OCR 文件生成提供即开即用的解决方案,但我们的自定义分类器代码提供了一种可行的解决方法。为了突破 SDK 的局限,我们创建了这一工具,它不仅可以解决眼前的问题,还可以增强我们的整体文档处理能力。

