




Table of Contents
技术驱动创新和进步,我们学习一个技术,不能浮于表面,应该做到坚持和深入,要真正地掌握知识内容,届时必会才思敏捷,别具匠心。因此文章主旨在于讲解openGauss段页式特性,以学习者身份,由浅入深分析openGaus段页式,并加入自己对其的见解。依照基础概念、结构设计和源码设计的排版结构逐层讲解段页式,让大家由易到难的真正理解段页式原理,从而更深入地理解其作用和优势,以及欢迎大家一起学习openGauss。
1.段页式基本概念
1.1 段页式存储

如图1内核层级结构图中,可知段页式存储是在SMGR层之下,与页式存储同属一层。此设计是为了复用openGauss原本的页式存储设计架构,从SQL引擎到SMGR层可复用页式存储使用的逻辑地址,再通过不同的存储方式,如页式存储或段页式存储,实现各自的逻辑。
1.2 段空间(segment space)
一个database(在一个tableapace中)有且仅有一个段空间(segment space),实际物理存储可以是一个文件,也可以拆分成多个文件。该database中所有table都是从该段空间中分配数据。所以表的个数和物理文件个数无关。
(1) 段空间创建触发条件:create database test1;创建数据库同时会创建该数据库对应的段空间
(2) 段空间的文件(段页式文件):5个文件及其分片和fork文件,分别命名为1, 2, 3, 4, 5
1.3 段页式文件

图2 段页式文件
段页式文件如图2所示,5个文件及其分片和fork文件,文件分别命名为1, 2, 3, 4, 5。
(1) 文件创建触发条件:create database test1; 创建数据库同时会创建该数据库对应的段页式文件并存放至段空间中
文件1: 主要存储一些段页式相关的元数据
文件2-5:存储用户数据和一些段页式相关的元数据
(2) 扩容方面:段页式文件可以自动扩容,不需要用户手动指定,知道磁盘空间用满或者达到tablespace设置的limint限制。
(3) 缩容方面:段页式存储不会自动缩容。当某些数据表被删除后,其在段页式文件中占据的空间会被保留,即段页式文件中会存在空洞,磁盘空间没有释放。这些空洞会被后面新扩展或者创建出来的表重用(深入思考:如何重用)。用户如果确定不需要重用这些空洞,可以手动调用系统函数,来进行缩容,释放磁盘空间(疑问深入思考:释放之后会怎么样,是文件大小变小吗,缩容和回收有什么区别)。
1.4 段segment
以段页式存储的一个对象的全部数据称为段。一个段的全部数据,会以区(extent)为单位存储在段空间的5个文件中,且不连续。extent的概念在章节1.5中介绍,雪友们可先移步至章节1.5学习extent。
每个table有一个逻辑上的segment,该table所有的数据都存在该segment上。每个segment会挂载多个extent,每个extent是一块连续的物理页。extent的大小可以根据业务需求灵活调整,避免存储空间的浪费。简单来说:一个segment对应一个object,比如数据表、索引,一个object有一个逻辑上的segmengt。
(1) 如下图所示,一个segment(单表的extent分布结构图):
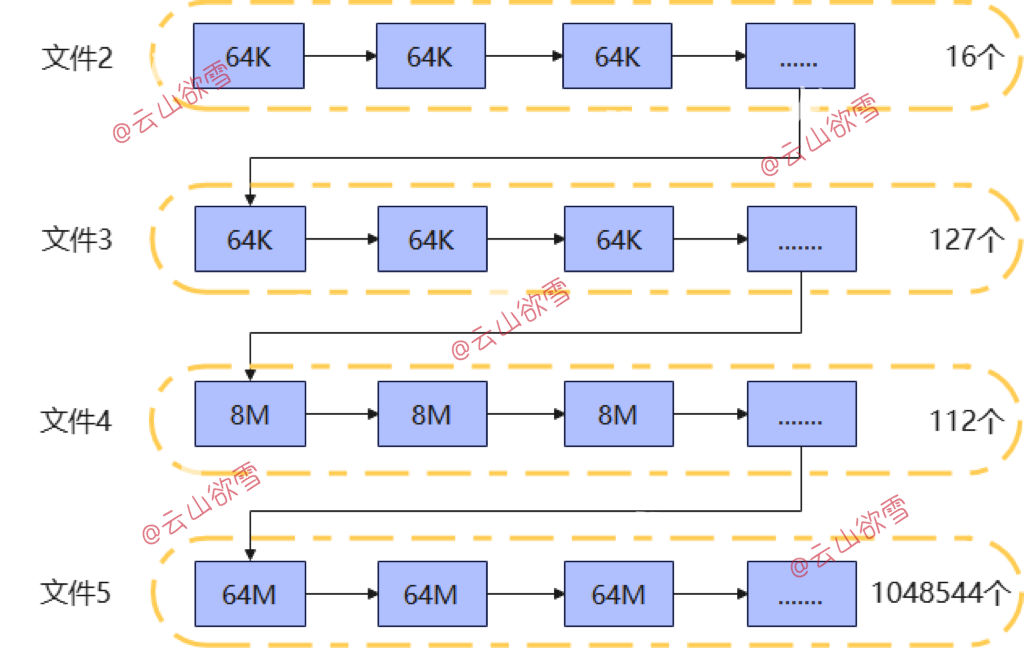
如图3可知一张段页式表的数据,是分散在这5个大文件中,且不连续。并不是像页式存储一样,一张表的数据在一个文件中。
(2) 段扩展(表扩展):segment会以extent为粒度自动扩展,加入新的extent,每一次扩展的extent的大小是固定。如表1中extent count range所示,一个段(表)扩展前16个extent大小为64K,第17到第143个extent大小为1M,依此类推。
(3) 段回收(表回收):不能直接回收某个extent,可通过对整个table做truncate方式,以segment为粒度回收存储空间。
1.5 区extent
目前支持四种大小extent,如表2所示,分别是64K/1M/8M/64M大小的extent。
表1 extent类型表
| group | exteng_size | extent page count | extent count range | Total page count | Total size |
|---|---|---|---|---|---|
| 1 | 64K | 8 | [1, 16] | 128 | 1M |
| 2 | 1M | 128 | [17,143] | 16K | 128M |
| 3 | 8M | 1024 | [144,255] | 128K | 1G |
| 4 | 64M | 8192 | [256, …] | … | … |
(2) extent扩展(区扩展):根据extent_type类型,找到对应的extend group,然后通过bit map page找到空闲extent分配进行扩展。名称上称为扩展,实际上称为extent 分配。详情请雪友们移至章节2.2一探究竟。
(3) extent回收(区回收):当某些数据被删除后,其在段页式文件中占据的空间,会被保留,即段页式文件中会存在一些空洞,磁盘空间没有被释放,也不能直接回收某个extent,一般情况下是通过extent group层级中的bit map page页面管理extent的使用情况,这些extent则会被后面新扩展或者创建出来的表重用。也就说段页式不会自动缩容,用户如果确定不需要使用这些空洞,可以手动调用系统函数(如truncate),来进行缩容,释放磁盘空间。
2.段页式结构设计
2.1 extent group 对象
一组前缀相同的slice 文件就是一个extent group 对象,如图2中文件5、5.1、5.2就是一个extent group对象
表2 exten group与文件类型对应表
| extent group id | exteng_size | extent_type | 文件前缀 |
|---|---|---|---|
| 0 | EXT_SIZE_1 | EXTENT_1 | 1 |
| 1 | EXT_SIZE_8 | EXTENT_2 | 2 |
| 2 | EXT_SIZE_128 | EXTENT_3 | 3 |
| 3 | EXT_SIZE_1024 | EXTENT_4 | 4 |
| 4 | EXT_SIZE_8192 | EXTENT_5 | 5 |
每个exent group 独自管理各自的文件空间,对应一个独立的SegLogicFile(详情见章节2.1大文件对象)。一个exent group 不完全等于 一个SegLogicFile, exent group在逻辑结构上,是SegLogicFile的上一层。在所属关系上,exent group不仅包含SegLogicFile,并且exent group还通过exteng_size与extent_type的转换,来表明SegLogicFile是什么段页式类型文件(即extent_type的类别)。也就是说 extent_type(文件类型)和SegLogicFile(所有分片文件)共同表明了一组exent group。
2.2 大文件对象
2.2.1 大文件
openGauss将段页式的每一个文件及其分片作为一个整体视为一个大文件对象,其对应的结构体为SegLogicFile
typedef struct SegLogicFile {
SegPhysicalFile *segfiles;
RelFileNode relNode;
ForkNumber forknum;
int vector_capacity; // current segfile array capacity
int file_num;
BlockNumber total_blocks;
char filename[MAXPGPATH];
pthread_mutex_t filelock;
} SegLogicFile;
(1) 每个分片对应的结构体SegPhysicalFile,主要是分片文件句柄和文分片编号
typedef struct SegPhysicalFile {
int fd;
int sliceno;
} SegPhysicalFile;
(2) SegLogicFile:relNode 结构和普通表一致,对应的结构体为RelFileNode
(3) file_num 表示有多少个分片文件
(4) total_blocks
(5) filename 文件名称
大文件对象是一个逻辑概念,即一个extent_type类型的文件所有分片组合在一起就是一个大文件对象。
2.2.2 大文件存储结构
如图2所示,文件5、5.1和5.2组合在一起是一个大文件对象,举例说明章节2.2.1中的参数,分片文件5,SegPhysicalFile中的sliceno=0,relnode是(1633,16712,1,0,0),表示(表空间1633,数据库16712,relation是1,分片是0)的文件,即文件1。分片文件5.1,SegPhysicalFile中的sliceno=1,relnode是(1633,16712,1,0,0),表示(表空间1633,数据库16712,relation是1, 分片是1)的文件,即文件1.1。
SegLogicFile大文件对象 <----------------------> 多个SegPhysicalFile文件对象(同一个extent_type)
段页式逻辑文件 <----------------------> 多个段页式物理文件(同一个extent_type)
2.2.3 大文件页面结构
SegLogicFile也是按照8KB为粒度切成一个个block,文件内容组织格式如下图所示:

图4 大文件对象内容组织结构图
(1) FileHeader:空闲,未使用
(2) SpaceHeader:空闲,未使用
(3) MapHeader: 第三个页面是MapHeader页面,记录每一个Map Group的起始页,其中group_count表示map group有多少个,目前最多有33个map group。
typedef struct st_df_map_head {
uint16 bit_unit; // page count that managed by one bit
uint16 group_count; // count of bitmap group that already exists
uint32 free_group; // first free group
uint32 reserved;
uint32 allocated_extents;
uint32 high_water_mark;
df_map_group_t groups[DF_MAX_MAP_GROUP_CNT];
} df_map_head_t;
(4) BitMapPages: 管理extent空闲的页面,使用一个bit 位记录一个extent是否空闲,则每一个BitMapPages总计可以管理65248个extent,其对应的结构体如下:
typedef struct st_df_map_page {
BlockNumber first_page; // first page managed by this bitmap
uint16 free_begin; // first free bit
uint16 dirty_last; // last dirty bit
uint16 free_bits; // free bits
uint16 reserved;
uint8 bitmap[0]; // following is the bitmap
} df_map_page_t;
Map Group:free_page::在一个编号为group number的Map Group中的第一个空闲的BitMapPages
BitMapPages:free_begin:在第一个空闲的BitMapPages中的第一个空闲的bit 位,是指该页中全局概念上的bit位(一个BitMapPages一共包含DF_MAP_BIT_CNT 个bit位,DF_MAP_BIT_CNT = DF_MAP_SIZE * 8)
BitMapPages:free_bits记录该bit map pages页上还有多少个空闲的bit位。
BitMapPages:first_page表示该位图页管理的第一个data page的blocknumber
每一个bit记录一个extent的使用情况,即每一位管理一个extent,在大文件扩展的时候,首先访问MapHeader页找到当前第一个空闲的group number(group count = 33个),每一个group满,MapHeader:free_group就会记录在下一个group number,找到空闲的group number后,再获取Map Group:free_page,即在编号为group number的Map Group中的第一个空闲的BitMapPages,然后再通过BitMapPages:free_begin找到第一个空闲位,即为pos。再根据下列公式能计算出来该bit位管理extent是否空闲:
#define DF_MAP_FREE(bitmap, pos) (!((bitmap)[(pos) >> 3] & (1 << ((pos)&0x07))))
@重点解说,不容错过@: bitmap是unit8类型,也就是一个byte,对应8个bit,每一个bit表示一个extent 是否free。pos>>3 就是舍弃最后8个字节,相当于 pos/8,计算出pos对应的bitmap所在的byte。((pos)&0x07)就是pos%8,计算出pos在对应的bitmap所在的byte的第几位。(1 << ((pos)&0x07))就是把1向左移动((pos)&0x07)个位置。((bitmap)[(pos) >> 3] & (1 << ((pos)&0x07)))就是检验当前df_map_page_t:bitmap里面的((pos)&0x07)个位置是否是1,是1说明extent在使用中,是0说明extent是空闲。
(5) Map Group: 是一组BitMapPages,总共包含64个 BitMapPages
typedef struct st_df_map_group {
BlockNumber first_map; // start page id of bitmap pages of this group
uint32 free_page; // first free page of this group
uint8 page_count; // count of bitmap pages of this group
uint8 reserved[DF_MAP_GROUP_RESERVED];
} df_map_group_t;
2.3 BMT(Block Map Tree)
2.3.1 逻辑地址
段页式设计为保证与页式存储上层逻辑保持一致,复用smgr上层逻辑,因此复用页式的物理地址<tablespace, database, relfilenode, blocknum>,作为段页式存储的逻辑地址,此设计可保证smgr上层逻辑不变,完全复用,从smgr层开始分叉,页式调用页式文件层,段页式调用段页式文件层,来个图这里需要图说明一下,更明确。
页式存储:逻辑地址<tablespace, database, relfilenode, blocknum>就是物理地址<tablespace, database, relfilenode, blocknum>
段页式存储:逻辑地址<tablespace, database, relfilenode, blocknum>通过BMT转化为物理地址
在页式存储中,我们可以使用一个数据页的逻辑地址<tablespace, database, relfilenode, blocknum>直接定位到一个页面的物理位置,因为逻辑地址<tablespace, database, relfilenode, blocknum>代表的意思是:一个表的数据全部存储在一个名字为relfilenode的表文件中,blocknum表示在这个文件中的第blocknum个页面。但是在段页式中,一个对象(如数据表)的页面是以extent为单位分散在5个文件中,也就是说,原本对应relfilenode文件的表的数据已经不在一个文件中,而是分散在5种extent类型的文件中(回顾extent概念见章节1.5),因此需要将逻辑地址<tablespace, database, relfilenode, blocknum>转换为段页式物理地址。
2.3.2 逻辑地址转换物理地址
-
1.@首先思考@:通过blocknum和extent的关系(回顾extent概念见章节1.3),可以计算出blocknum属于一个段中的哪一类extent类型、在第几extent中,以及在该extent中的第几个block
举例说明:
pageid = 185172567
根据表1 extent类型结构图,已知16个64K类型extent共可存储128个页面,累计到127个1M类型extent可存储16384个页面, 累积到112个8M类型extent共可存储131072页面。
哪一类extent类型(extent_type):pageid > 131072, 因此可知这个页面是在64M的extent之中,也就是在段页式文件5之中。
在一个段中的第几extent中(extent_id):(pageid - 131072) / 8192 = 22588 ... 599 ---> 总数 (16+127+112+22588)个extent
// 可知它在第22588个64M类型extent中,在一个段的第(16+127+112+22588= 22843)个extent
// 注意这里第一个式子是减掉了该类型前面所有page数量131072之后再做除法,
// 所以计算的是该类型中的第几个extent,而不是一个段上的extent编号
// 22588+(16+127+112)=22843才表示一个段(数据表)的第22843个extent
在该extent中的第几个页面(block):在第22588个64M类型extent中第599个页面。
// 注意这里减掉了该类型前面所有page数量131072之后再做除法,获取的余数599
// 因此599表示的是在第22588个64M类型extent中第599个页面,不是一个段上的页面编号
@敲黑板,划重点@:切记这里的第22588个64M类型extent中不是指文件5以64M为单位均分后,从头顺序计数到文件5的第22588个64M大小的extent,这里是一个逻辑概念,是一个段(即一个数据表)的第22588个64M类型的extent,总体计算也就是一个段(即一个数据表)的第(16+127+112+22588)个extent
至此我们可得到如下关系:
逻辑地址<tablespace, database, relfilenode, blocknum> =====》 段页式逻辑地址<tablespace, database, relfilenode, extent_type, extent_id, block>
段页式逻辑地址中参数含义如下:
extent_type:表示blocknum属于的段页式文件类型,如表2所示
extent_id:表示一个段的第几个extent
block_id(offset):表示在extent_type类型文件中,并且是在一个段的第extent_id个的extent中的第几个block
因此根据这一步的关系转换,我们获取到的段页式逻辑地址唯一可以确定一个页面。
-
2.@再次思考@:第一步获取到extent_id是指一个段(数据表)内的extent的排序,根据第1章节的介绍,一个段的extent是散落在2、3、4、5四个文件中的,因此我们获取到的extent_id是一个逻辑上的位置,是散落在extent_type类型文件上的一个逻辑编号位置,还是无法确定第extent_id的extent的起始位置在extent_type类型文件的物理地址
因此为了能够找到一个segment的某一个extent的物理位置,就需要存在一个映射来保存每个extent的逻辑地址和物理地址的对应关系,这个映射就是Block Map Tree (BMT)
-
3.转换关系:
第一步:根据页面的逻辑地址中的blocknum计算出所在的extent的extent_id编号和该页面在extent中的第block_id(offset)个页面
第二步:在BMT中获取第一步中extent_id对应的extent的物理地址extent_id_address
第三步:即将逻辑地址转换为物理地址<extent_type, extent_id_address, block_num>
-
4.BMT如何存储extent的物理地址?
存储一个段(数据表)的extent_id和其对应的物理地址的第一个page的地址即可
根据表1可知,可计算出逻辑地址中的blocknum所在的extent,属于哪个extent_type类型的段页式文件。在一个段中,extent_id是从0自增,因此我们可以使用数组来保存映射关系,数组的键:extent_id,数组的value: extent_id对应的extent的起始页的物理地址。这个映射关系我们将保存在SegmentHeader页面中,该映射关系在存储结构上是一个二维数组的结构,称为BMT。
2.3.3 BMT结构设计
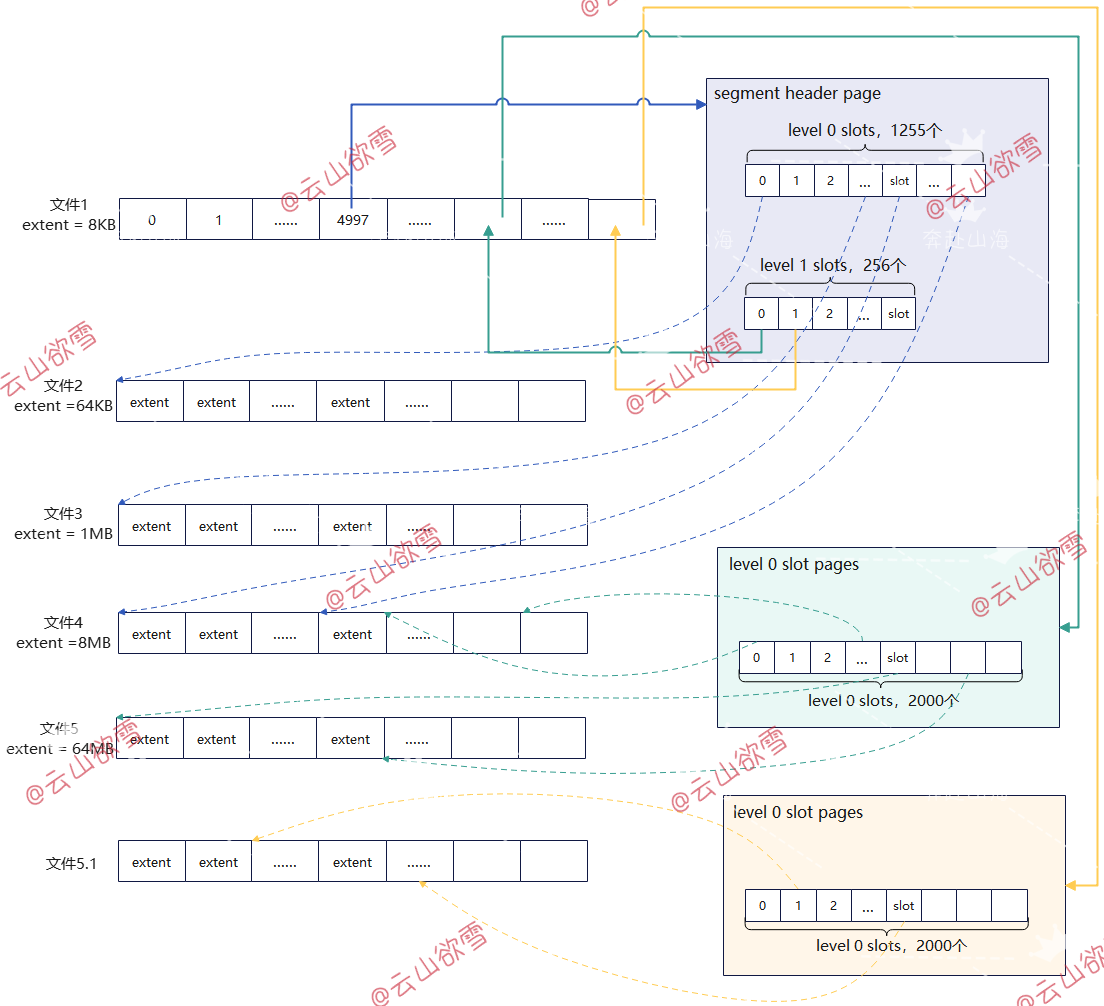
SegmentHeader页面中直接存储的只有前1255个extentPos,头页中的level0层有1255个槽位,level1中槽位对应的level0页面中有BMT_TOTAL_SLOTS=1255+512个槽位。
当表不超过1255大小时,只会用到level0层,即0-1254个slot对应1255个分区。
当超过1255大小时,就会有两层,分别是level0和level1层,level1层用来存level0层页面的位置,如图所示level1层有512个槽位,即对应512个页面,这512个页面的每个页面里面又有1255个slot,举例理解为:当一个段超过1255个extent之后,则会使用level1层的slot,该槽位记录一个页面位置(依然在段页式类型1的文件中,需要的时候会extent一个页面给这个段),这个页面中有1255个slot,每个slot又记录对应extent的起始地址,比如level1的level1_slot=0对应的页面中的level0_slot=0存的是这个段的第[BMT_TOTAL_SLOTS*(level1_slot+1)+level0_slot]=1256个extent,level1的槽位level1_slot=1对应的页面中的level0_slot=0存的是这个段的第[BMT_TOTAL_SLOTS*(level1_slot+1)+level0_slot]=1257个extent,再比如level1的槽位level1_slot=1对应的页面中的level0_slot=0存的是这个段的第[1255*(level1_slot+1)+level0_slot]=2510个extent。
欲知为何如此设计,请移步至博客:《BMT设计原理》
3.源码结构设计
3.1 段页式对象设计
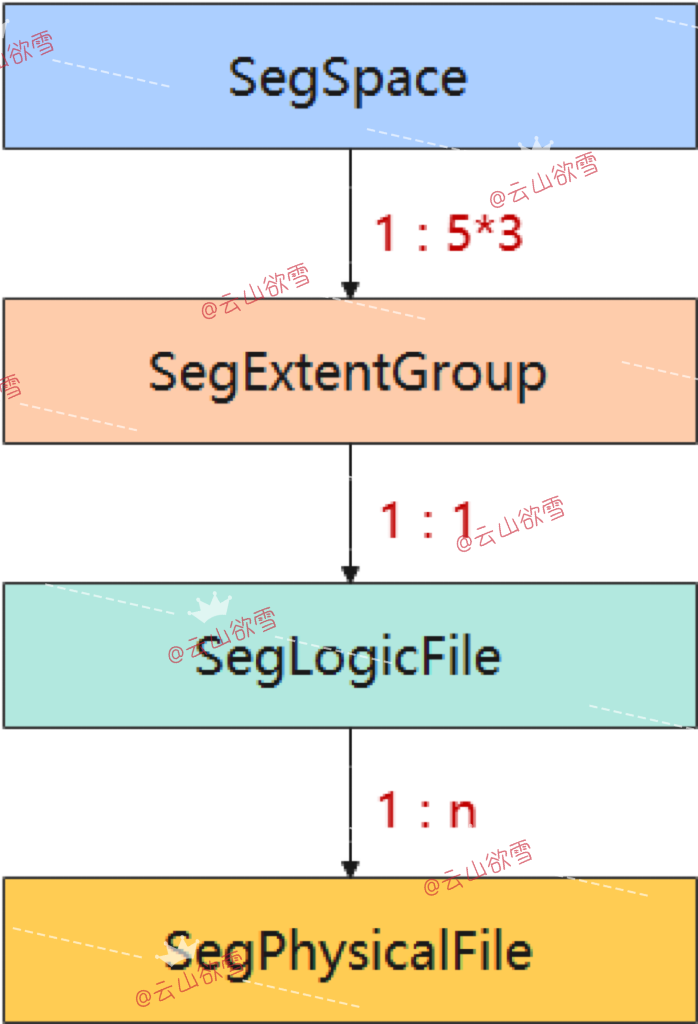
逻辑上,我们将一个表空间下一个database 下的全部段页式文件抽象为一个段页式空间(segment space),段页式逻辑上设计三个层级:space层、extent_group层、data_file层,如图6所示:
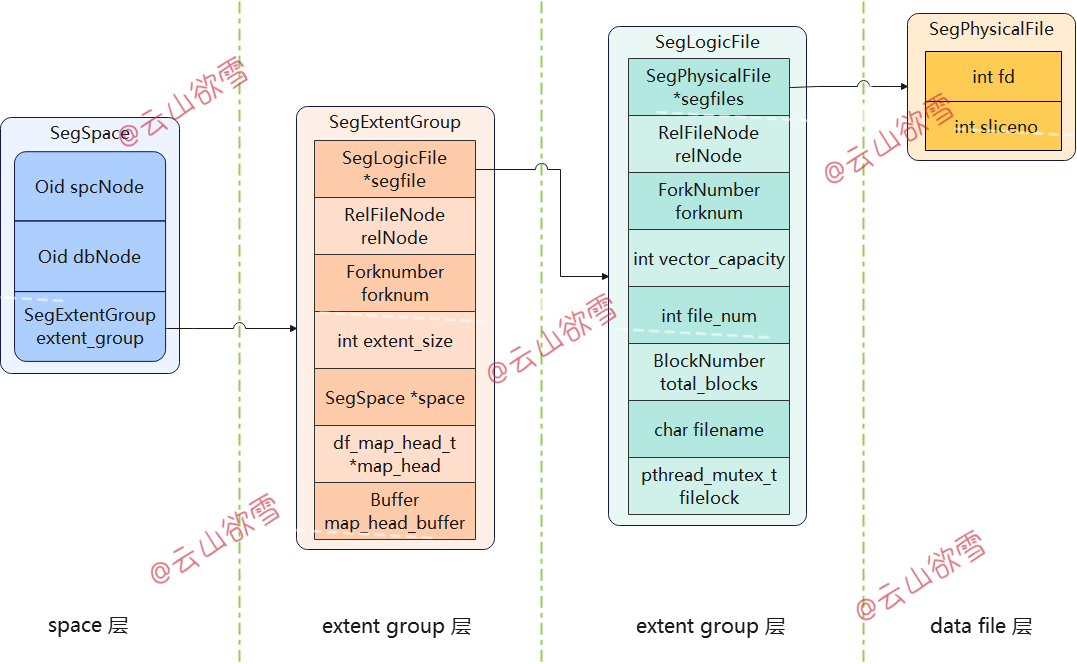
如图6所示,可知space层是段空间,段空间中保存了一个数据库的唯一标识(spcNode,dbNode),还保存了管理5种extent_type类型文件的extent_group数组(index从0到4),每一个extent_group通过大文件对象SegLogicFile和extent_size作为唯一标识来管理extent_size对应的extent_type类型(见表2)的段页式文件以及分片。大文件对象SegLogicFile又具体的管理了一组前缀相同的SegPhysicalFile物理文件(即图2中前缀相同的文件以及分片)。
3.2 地址转换函数
(1) 逻辑地址到段页式逻辑地址的转换函数 ------ SegLogicPageIdToExtentId
请雪友返回到章节2.3回忆一下段页式逻辑地址,SegLogicPageIdToExtentId函数入参()得到段页式逻辑地址(extent_type, extent_id, block分别对应源码中extent_size, extent_id, offset)
(2) 逻辑extent_id到物理地址的转换函数 ------ seg_extent_location
extent_id是通过SegLogicPageIdToExtentId函数得到逻辑页面blocknum计算出来的,表示该页面在一个段(数据表)的第extent_id个的extent中。
再通过 seg_extent_location函数中的BMT获取到一个段(数据表)的第extent_id个的extent中的第一个页面的物理页号(这个物理页号表示的extent_type类型文件的页号,不是一个段的页号)。
(3) 逻辑地址到段页式物理地址的转换 ------ seg_logic_to_physic_mapping
通过SegLogicPageIdToExtentId和seg_extent_location函数获取到extent_size、extent_id、offset和第extent_id个的extent中的第一个页面的物理页号。
再通过第extent_id个的extent中的第一个页面的物理页号加上 offset,即可计算出逻辑地址中的blocknum对应在extent_type类型文件中的页号。
(4) 段页式物理地址到BitMapPage转换函数 ------ eg_locate_map_by_pageid
3.3 相关常量和结构体
1.常量
/* Segment size related constants */
const int DF_ARRAY_EXTEND_STEP = 4;
const ssize_t DF_FILE_EXTEND_STEP_BLOCKS = RELSEG_SIZE / 8;
const ssize_t DF_FILE_EXTEND_STEP_SIZE = DF_FILE_EXTEND_STEP_BLOCKS * BLCKSZ; // 128MB
const ssize_t DF_FILE_SLICE_BLOCKS = RELSEG_SIZE;
const ssize_t DF_FILE_SLICE_SIZE = DF_FILE_SLICE_BLOCKS * BLCKSZ; // 1GB
const ssize_t DF_FILE_MIN_BLOCKS = DF_FILE_EXTEND_STEP_BLOCKS;
/* Map Group related constants */
const int DF_MAP_GROUP_RESERVED = 3;
const int DF_MAX_MAP_GROUP_CNT = 33;
/* Block Map Tree (BMT) related constants */
static const int BMT_HEADER_LEVEL0_SLOTS = 1255; // level0 slots must bigger or equal than EXT_SIZE_1024_BOUNDARY
static const int BMT_HEADER_LEVEL1_SLOTS = 256;
static const int BMT_HEADER_LEVEL0_TOTAL_PAGES =
EXT_SIZE_1024_TOTAL_PAGES + (BMT_HEADER_LEVEL0_SLOTS - EXT_SIZE_1024_BOUNDARY) * EXT_SIZE_8192;
static const int BMT_TOTAL_SLOTS = BMT_HEADER_LEVEL0_SLOTS + BMT_HEADER_LEVEL1_SLOTS;
static const uint32_t BMT_LEVEL0_SLOTS = 2000;
- BMTLevel0Page
typedef struct SegmentHead {
uint64 magic;
XLogRecPtr lsn;
uint32 nblocks; // block number reported to upper layer
uint32 nextents; // extent number allocated to this segment
uint32 nslots : 16; // not used yet
int bucketid : 16; // not used yet
uint32 total_blocks; // total blocks can be allocated to table (exclude metadata pages)
uint64 reserved;
BlockNumber level0_slots[BMT_HEADER_LEVEL0_SLOTS];
BlockNumber level1_slots[BMT_HEADER_LEVEL1_SLOTS];
BlockNumber fork_head[SEGMENT_MAX_FORKNUM + 1];
} SegmentHead;
typedef struct BMTLevel0Page {
uint64 magic;
BlockNumber slots[BMT_LEVEL0_SLOTS];
} BMTLevel0Page;
4.特性总结
4.1 优势
openGauss是基于PG开源,借鉴了PG的存储空间管理,即页式管理,数据在内存中以页面块的形式存在。这种存储管理模式存在以下问题:(1) 对文件系统依赖大,无法进行细粒度的控制来提升可维护性。(2)大数据量下文件句柄过多,目前只能依赖虚拟句柄来解决,影响性能。(3)小文件数量过多会导致全量build、全量备份等场景下的随机IO问题,影响性能。
从上述三个章节的对段页式讲解,可知表的个数和实际物理文件个数无关,每个表有一个逻辑上的段(segment),该表的所有数据都存在该segment上,每个segment包含多个extent,extent的大小可以根据业务需求灵活调整,避免存储空间的浪费。以一个简单的例子,感受一下段页式的魅力,如果一个数据库有上千个上万个数据表或者索引,并且都是小数据量的表,对于页式存储来说,每一个对象对应一个物理文件,那么访问不同对象时,就需要多次地打开关闭物理文件;但是对于段页式存储来说,因为一个物理文件可以存储多个表数据,可能只需要十几个或者几十个段页式文件就可以存储所有小数据量表。
4.2 注意点
技术点的细节注意点已在上面内容部分详细说明,下列说明一些使用注意点:
- (1) 使用openGauss段页式存储需要打开参数,数据表以段页式结构存储。
- (2) 目前不支持列存表、系统表、主备从部署方式。
- (3) 段页式存储容易出现空洞,可能某些活跃的extent在文件尾部,而中间部分属于未被使用状态,这会占用额外的存储空间
- (4) 段页式的文件句柄,没有走虚拟文件句柄,并会处于长期打开状态。所以需要系统的ulimit值大于所有段页式物理文件的个数。按照1GB一个文件算,4TB的数据量需要4000个句柄。这不包括无法用段页式存储的对象通过页式存储用到的句柄。
原创作者:丑丑的老太婆
Author:unique woman
