




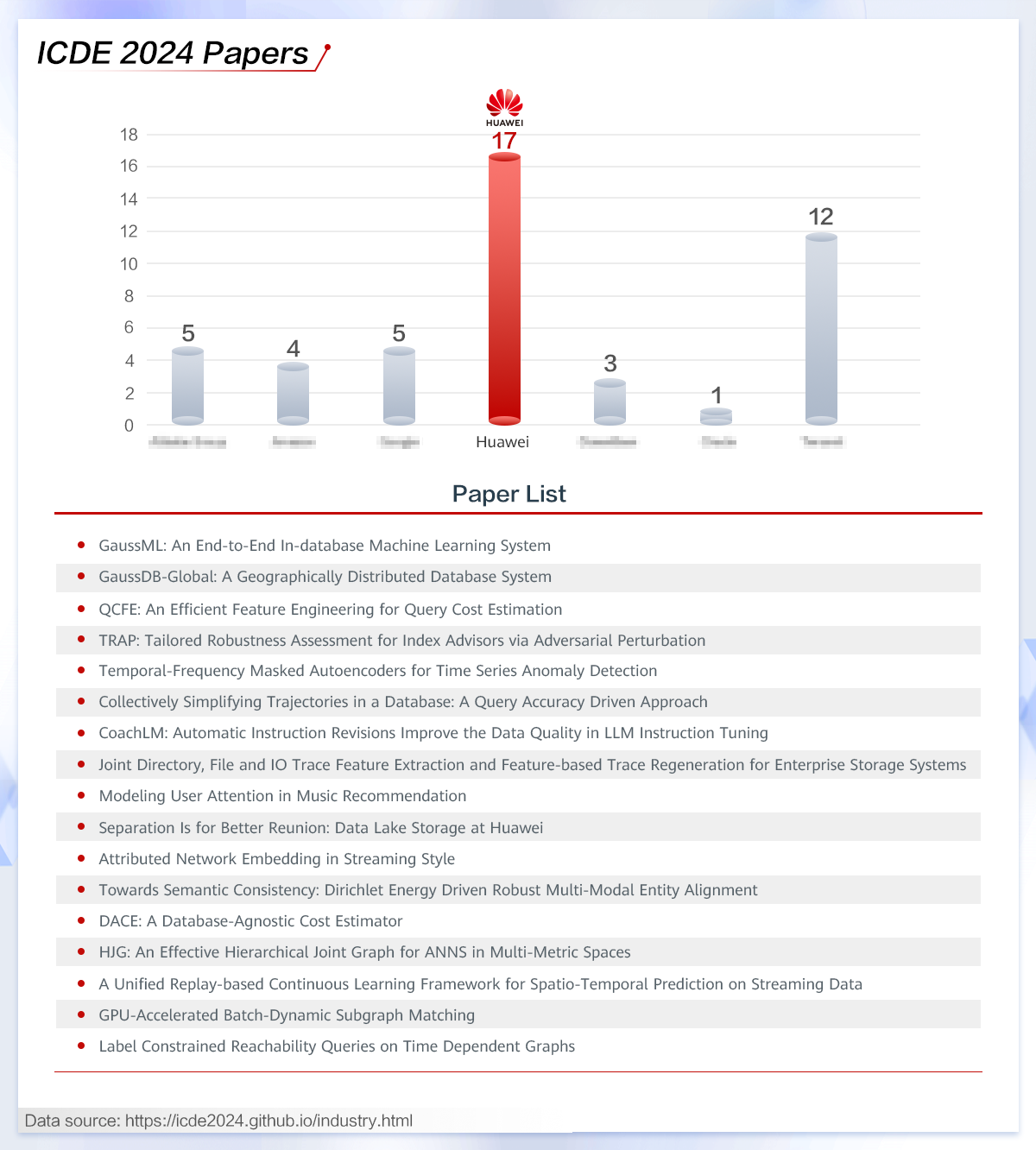
2024年5月13日到17日,国际顶级学术会议——第40届IEEE数据工程国际会议( ICDE 2024)在荷兰乌得勒支召开。此次活动,ICDE评选出了来自华为云GaussDB、GeminiDB、数据领域的17篇论文,数量超过其他厂商。华为爱丁堡研究中心数据库实验室主任Nikolaos Ntarmos发表了题为《华为云GaussDB,更好的数据库之路》的演讲。演讲向来自世界各地的学术机构和代表介绍了GaussDB的技术和各项业务成果。
IEEE国际数据工程会议(ICDE)、SIGMOD、VLDB并称为数据库领域三大国际顶级学术会议。 ICDE在全球具有重要的学术影响力。
ICDE汇集了各大研究机构和科技企业最前沿、顶级的数据库研究成果。第40届IEEE数据工程国际会议ICDE 2024入选华为17篇论文。所有这些成果都来自于华为科研团队和合作伙伴团队或组织的共同努力。所有论文都将在稍后进行详细审查,但这里有一些亮点。
GaussML:端到端数据库内机器学习系统
(GaussML: An End-to-End In-database Machine Learning System)
数据库内机器学习 (In-DB ML) 对存在安全和隐私问题的数据库用户很有吸引力,因为数据不会从数据库复制到单独的机器学习系统。
实现数据库内 ML 的一种常见方法是 ML-as-UDF 方法,它利用 SQL 中的用户定义函数 (UDF) 来实现 ML 训练和预测。然而,UDF 可能会通过易受攻击的代码引入安全风险,并且由于受到 SQL 查询运算符的数据访问和执行模式的限制,它们很容易出现性能问题。
为了解决这些限制,我们提出了一种新的数据库内机器学习系统,即GaussML,它通过本机SQL接口提供端到端机器学习功能。
为了支持 SQL 查询中的 ML 训练/推理,GaussML 直接将典型的 ML 运算符集成到查询引擎中,而无需 UDF。 GaussML 还引入了 ML 感知基数和成本估计器来优化 SQL+ML 查询计划。
此外,GaussML 利用单指令多数据 (SIMD) 和数据预取技术来加速 ML 算子的训练。
我们在openGauss数据库中的GaussML内部实现了一系列算法。与 Apache MADlib 等最先进的数据库内 ML 系统相比,我们的 GaussML 在大量实验中实现了 2-6 倍的速度。
GaussDB-Global:地理分布式数据库系统
(GaussDB-Global: A Geographically Distributed Database System)
地理分布式数据库系统使用远程复制来防止区域故障。这些系统对集中式事务管理、远程访问分片数据以及长距离日志传送造成的严重延迟损失很敏感。
为了解决这些问题,我们推出了 GaussDB-Global,这是一个用于 OLTP 应用程序的具有异步复制功能的分片地理分布式数据库系统。
为了解决事务管理瓶颈,我们采用使用同步时钟的去中心化方法。我们的系统可以在集中式和分散式交易管理之间无缝过渡,提供高效的容错能力并简化部署。
为了缓解远程读取和日志传送问题,我们支持对具有强一致性、可调新鲜度保证和动态负载平衡的异步副本进行读取。
我们在地理分布式集群上的实验结果表明,与我们的基准相比,我们的方法可提供高达 14 倍的读取吞吐量和 50% 的 TPC-C 吞吐量。
QCFE:一种用于查询成本估计的高效特征工程
(QCFE: An Efficient Feature Engineering for Query Cost Estimation)
查询成本估计是数据库管理的一项经典任务。最近,研究人员应用人工智能驱动的模型来实现更准确的成本估算,以实现高精度。然而,这种设计有两个缺陷导致成本估算精度较差——时间效率。
现有的工作仅对查询计划和数据统计进行编码,而忽略了其他一些重要变量,如存储结构、硬件、数据库旋钮等。这些变量对查询成本也有显着影响。另一个问题是,由于简单的编码设计,现有的工作在无效的输入维度上承受着沉重的表示学习负担。
为了解决这两个问题,我们首先提出了一种用于查询成本估计的高效特征工程方法,称为 QCFE。具体来说,我们设计了一个新颖的特征,称为“特征快照”,以有效地整合被忽略变量的影响。此外,我们提出了一种用于查询成本估计的差异传播特征缩减方法,以过滤掉无用的特征。实验结果表明我们的 QCFE 可以极大地提高广泛基准上的时间精度效率
TRAP:通过对抗性扰动为指数顾问量身定制稳健性评估
(TRAP: Tailored Robustness Assessment for Index Advisors via Adversarial Perturbation)
最近,许多索引顾问被提议自动构建索引以提高查询性能。但他们主要考虑的是静态场景下的性能提升。它们的鲁棒性,即它们在动态场景(例如,工作负载发生微小变化)中保持稳定性能的能力,尚未得到充分研究。
本文通过以下方式解决了评估指数顾问稳健性的挑战。
首先,我们引入了基于扰动的工作负载进行鲁棒性评估,并确定了实际场景中出现的三种典型扰动约束。
其次,在扰动约束下,我们将扰动查询的生成表述为序列到序列问题,并提出通过对抗性扰动(TRAP)进行定制鲁棒性评估,以查明索引顾问的性能漏洞。
第三,为了推广到各种指数顾问,我们将 TRAP 置于黑盒环境中(即,对指数顾问的内部设计知之甚少),并且我们提出了一个两阶段训练范例,无需精心注释的数据即可有效训练 TRAP 。
第四,我们对十个现有指数顾问的标准基准和实际工作负载进行了全面的稳健性评估。我们的研究结果表明,这些指数顾问很容易受到 TRAP 生成的工作负载的影响。
最后,评估揭示了我们如何增强不同指数顾问的稳健性的各种见解。例如,基于学习的索引顾问可以受益于细粒度的状态表示和候选修剪策略。
用于时间序列异常检测的时频屏蔽自动编码器
(Temporal-Frequency Masked Autoencoders for Time Series Anomaly Detection)
在当今的可观测性时代,必须收集大量时间序列数据来监控目标系统的状态,其中异常检测用于识别与其余观测值显着不同的观测值。从此类数据中提取价值的能力至关重要。虽然现有的基于重建的方法在没有标记数据的情况下表现出了良好的检测能力,但它们仍然容易导致对时间序列内的异常时间和分布变化的训练偏差。
为了解决这些问题,我们提出了一种简单而有效的时频屏蔽自动编码器(TFMAE),通过对比标准检测时间序列数据中的异常。具体来说,TFMAE 使用两个基于 Transformer 的自动编码器,分别结合基于窗口的时间掩蔽策略和基于幅度的频率掩蔽策略来学习没有异常偏差的知识,并根据提取的正常信息重建异常。
此外,双自动编码器使用对比目标函数进行训练,最大限度地减少时频屏蔽自动编码器的表示差异以突出异常,因为它有助于减轻分布变化的负面影响。
最后,为了防止过度拟合,TFMAE 在训练阶段使用对抗性训练。对七个数据集进行的广泛实验证明,我们的模型能够在异常检测准确性方面超越最先进的模型。
ICDE 2024入选的华为数据库论文涵盖了广泛的技术,包括AI4DB、时序数据库、查询优化以及数据库的机器学习模型训练和推理。华为多年来致力于前沿数据库技术的研究,并与全球领先的学术机构合作,解决国际数据库挑战。华为基于产学研用合作,不断将创新的研究成果融入产品技术中,努力构建强大的生态系统,为客户提供创新、有竞争力的产品和服务。
华为致力于数据库领域的创新和探索,展示对行业发展的影响力。
ICDE 2024 接收论文:
https://icde2024.github.io/papers.html




