




在大规模数据复杂分析或海量数据即席查询的场景中,列式存储是一项关键能力。与行式存储相比,列式存储通过不同的数据文件组织方式,将表中的数据按列进行物理排列。这种存储方式使得在分析场景中,查询计算只需扫描所需的列数据,避免了整行扫描,从而减少了 IO 和内存等资源的使用,提升了计算速度。此外,列式存储天然具备更好的数据压缩条件,能够实现较高的压缩比,减少了存储空间和网络传输带宽的需求。
常见的列存存储引擎在实现上通常假设不会有大量随机更新,并尽量保持列存数据的静态性。然而,当面对大量数据随机更新时,系统性能问题是不可避免的。OceanBase 的 LSM-Tree 架构通过分别处理基线数据和增量数据,解决了这一问题。因此,OceanBase 4.3 版本在现有架构基础上进行了扩展,推出了列存引擎,实现了列存和行存数据存储的一体化,兼顾事务处理(TP)和分析处理(AP)查询的性能。
为了让有分析需求的用户顺畅使用新版本,围绕列存引擎,从优化器到执行器,从 DDL 到事务处理等多个模块都进行了适配和优化。包括基于列存的新的代价模型和向量化引擎,查询下压功能的扩展和增强,跳跃索引(Skip Index),新的列式编码算法,自适应压缩(Compaction)等。本文将深入剖析 OceanBase 4.3 版本带来的列存能力、应用场景以及用户关注的未来发展规划。
一、列存整体架构
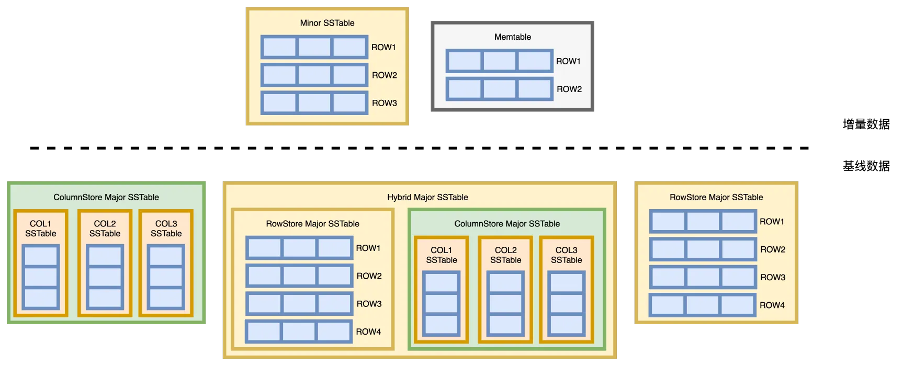
基线数据:相较于业内常见的 LSM-Tree 实现逻辑,OceanBase 提出了"每日合并"的概念。用户可定期或根据操作选择一个全局版本号,所有副本的租户数据将在这个版本上进行一轮 Major Compaction,生成这个版本的基线数据。所有副本在同一版本下的基线数据完全一致,物理上保持一致。 增量数据:相对于基线数据,增量数据是指在最新版本的基线数据之后写入的数据。增量数据可以是刚写入Memtable的内存数据,也可以是已经转储为SSTable 的磁盘数据。增量数据在每个副本中独立维护,不保证一致性,并且包含了所有多版本的数据。
二、OceanBase实现列存有哪些天然优势
(一)成熟的 LSM-Tree 引擎
(二)完善的执行引擎
(三)灵活的原生分布式
基线列存 +增量行存:基线数据采用列存方式存储,增量数据采用行存方式存储。
灵活的行存/列存索引:可以对行存表建立列存索引,也可以对列存表建立行存索引,还可以对两者进行任意组合。由于所有列存表和索引的底层存储结构是统一的,因此 OceanBase 可以自动支持列存和行存的索引。
列存副本:OceanBase 正在研发的列存副本功能。得益于原生分布式能力,只需对模式或表做部分修改,即可以通过 Compaction 将新增的只读副本转换为列存存储模式。
三、列存使用方法
(一)默认创建列存表
alter system set default_table_store_format = "column";复制
OceanBase(root@test)>create table t1 (c1 int primary key, c2 int ,c3 int);Query OK,0 rows affected (0.301 sec)OceanBase(root@test)>show create table t1;CREATE TABLE `t1` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0WITH COLUMN GROUP(each column)1 row in set (0.101 sec)复制
(二)指定创建列存表
OceanBase(root@test)>create table tt_column_store (c1 int primary key, c2 int ,c3 int) with column group (each column);Query OK,0 rows affected (0.308 sec)OceanBase(root@test)>show create table tt_column_store;CREATE TABLE `tt_column_store` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 WITH COLUMN GROUP(each column)1 row in set (0.108 sec)复制
(三)指定创建列存行存冗余表
create table tt_column_row (c1 int primary key, c2 int , c3 int) with column group (all columns, each column);Query OK, 0 rows affected (0.252 sec)OceanBase(root@test)>show create table tt_column_row;CREATE TABLE `tt_column_row` (`c1` int(11) NOT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,PRIMARY KEY (`c1`)) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 WITH COLUMN GROUP(all columns, each column)1 row in set (0.075 sec)复制
(四)列存扫描
OceanBase(root@test)>explain select * from tt_column_store;+--------------------------------------------------------------------------------------------------------+| Query Plan |+--------------------------------------------------------------------------------------------------------+| ================================================================= || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || ----------------------------------------------------------------- || |0 |COLUMN TABLE FULL SCAN|tt_column_store|1 |7 | || ================================================================= || Outputs & filters: || ------------------------------------- || 0 - output([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), filter(nil), rowset=16 || access([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), partitions(p0) || is_index_back=false, is_glOceanBaseal_index=false, || range_key([tt_column_store.c1]), range(MIN ; MAX)always true |+--------------------------------------------------------------------------------------------------------+
OceanBase(root@test)>explain select * from tt_column_store where c1 = 1;+--------------------------------------------------------------------------------------------------------+| Query Plan |+--------------------------------------------------------------------------------------------------------+| =========================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || ----------------------------------------------------------- || |0 |COLUMN TABLE GET|tt_column_store|1 |14 | || =========================================================== || Outputs & filters: || ------------------------------------- || 0 - output([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), filter(nil), rowset=16 || access([tt_column_store.c1], [tt_column_store.c2], [tt_column_store.c3]), partitions(p0) || is_index_back=false, is_global_index=false, || range_key([tt_column_store.c1]), range[1 ; 1], || range_cond([tt_column_store.c1 = 1]) |+--------------------------------------------------------------------------------------------------------+12 rows in set (0.051 sec)
OceanBase(root@test)>explain select * from tt_column_row;+--------------------------------------------------------------------------------------------------+| Query Plan |+--------------------------------------------------------------------------------------------------+| ======================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || -------------------------------------------------------- || |0 |TABLE FULL SCAN|tt_column_row|1 |3 | || ======================================================== || Outputs & filters: || ------------------------------------- || 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 || access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) || is_index_back=false, is_global_index=false, || range_key([tt_column_row.c1]), range(MIN ; MAX)always true |+--------------------------------------------------------------------------------------------------+
OceanBase(root@test)>explain select /*+ USE_COLUMN_TABLE(tt_column_row) */ * from tt_column_row;+--------------------------------------------------------------------------------------------------+| Query Plan |+--------------------------------------------------------------------------------------------------+| =============================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || --------------------------------------------------------------- || |0 |COLUMN TABLE FULL SCAN|tt_column_row|1 |7 | || =============================================================== || Outputs & filters: || ------------------------------------- || 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 || access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) || is_index_back=false, is_global_index=false, || range_key([tt_column_row.c1]), range(MIN ; MAX)always true |+--------------------------------------------------------------------------------------------------+
OceanBase(root@test)>explain select /*+ NO_USE_COLUMN_TABLE(tt_column_row) */ c2 from tt_column_row;+------------------------------------------------------------------+| Query Plan |+------------------------------------------------------------------+| ======================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || -------------------------------------------------------- || |0 |TABLE FULL SCAN|tt_column_row|1 |3 | || ======================================================== || Outputs & filters: || ------------------------------------- || 0 - output([tt_column_row.c2]), filter(nil), rowset=16 || access([tt_column_row.c2]), partitions(p0) || is_index_back=false, is_global_index=false, || range_key([tt_column_row.c1]), range(MIN ; MAX)always true |+------------------------------------------------------------------+11 rows in set (0.053 sec)复制
四、未来展望
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
文章被以下合辑收录
评论
胡飞

11月前
评论
 0
0深入剖析OceanBase 4.3的列存技术
11月前
点赞 评论
相关阅读
2025年4月国产数据库大事记:4个千万级中标项目诞生!2024年达梦净利3.6亿、金仓净利8006.6万……
墨天轮编辑部
2090次阅读
2025-04-30 17:39:54
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
731次阅读
2025-04-30 15:24:06
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
600次阅读
2025-04-14 09:40:20
给准备学习国产数据库的朋友几点建议
白鳝的洞穴
306次阅读
2025-05-07 10:06:14
919万!南航信息中心采购OceanBase数据库软件许可及服务
通讯员
284次阅读
2025-04-29 16:13:34
AI关键场景得到全面支持!OceanBase入选Forrester报告三大领域代表厂商
OceanBase数据库
261次阅读
2025-04-19 22:27:54
1364万!2024年中国联通软研院OceanBase扩容单一来源采购公示
通讯员
181次阅读
2025-04-21 15:55:59
Oceanbase单机版上手示例
潇湘秦
167次阅读
2025-04-18 13:40:24
分布式数据库真的是伪需求吗
白鳝的洞穴
145次阅读
2025-04-21 10:35:09
CloudDM v2.3.0.0 全新发布,支持 OceanBase For Oracle 和 Oracle
ClouGence
133次阅读
2025-04-27 11:04:16



