




产品功能
AntDB-MTK的功能架构图如下:
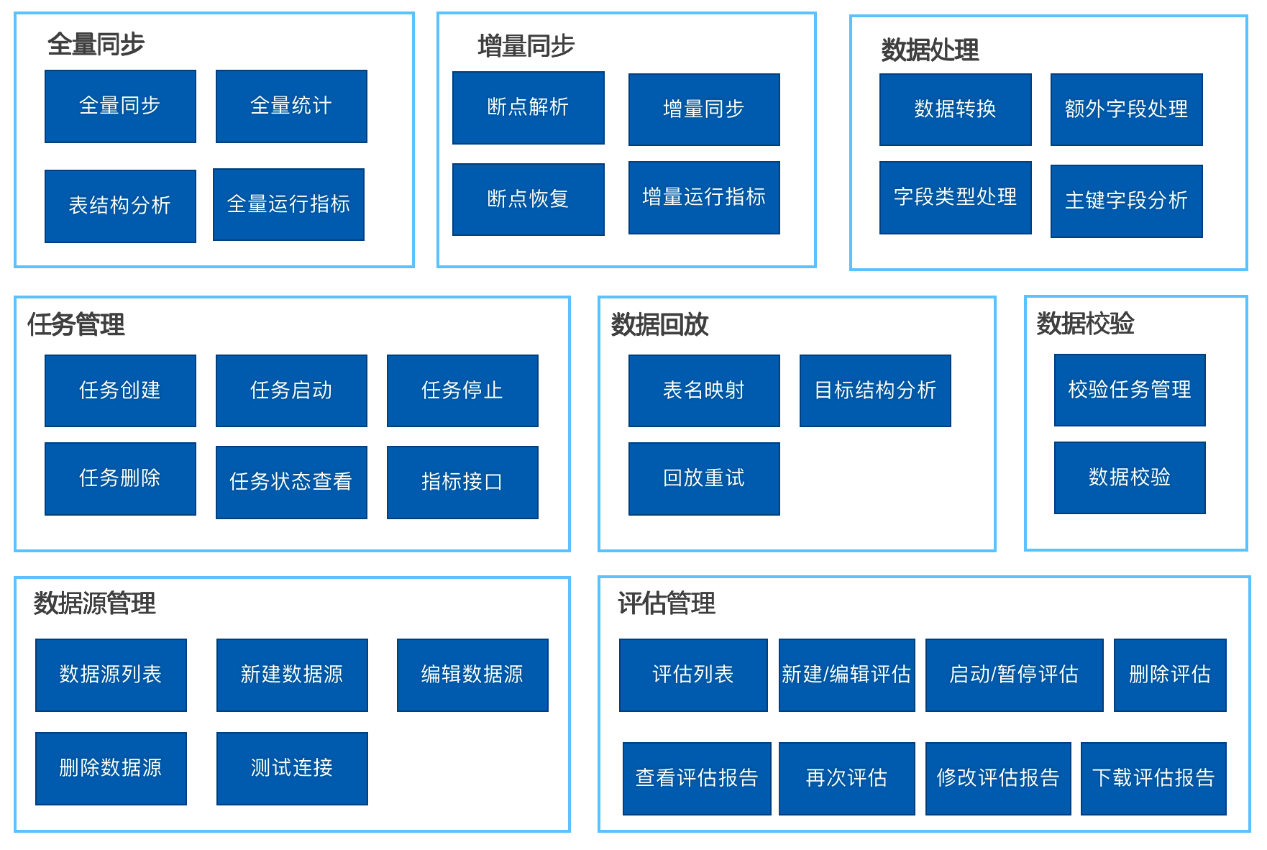
AntDB-MTK各个模块的功能描述如下:
Ÿ 全量同步:支持按指定的表进行全量同步,支持按指定的database或者schema进行数据同步。
Ÿ 增量同步:支持按时间点或者偏移量进行增量数据同步。
Ÿ 数据处理:对从源端获取到的数据进行处理变换,比如添加字段、修改字段值、删除字段等,并且提供脚本方式配置处理规则。数据处理的动作可以发生在持久化到Kafka之前,也可以发生在目标端从Kafka中获取之后。
Ÿ 数据回放:目标端主要接收从Kafka来的数据消息,通过数据的唯一标识符,对数据在目标库上进行重放。重放用的SQL语句根据不同目标数据库类型的不同而不同。
Ÿ 任务管理:提供方便的操作界面,通过界面化的配置来配置任务处理。任务划分为同步任务和具体工作器。 一个任务可以启动多个工作器,达到并行处理,提高吞吐量的目标。源端和回放端重放都作为一个任务存在,通常来讲为了保持源端捕捉的一致,源端的任务只有一个工作器,目标端为了提高并发,会启动多个工作器。任务管理主要管理各个同步任务的生命周期。
Ÿ 数据源管理:数据源管理提供新增/修改/删除/查询/测试连接数据库信息功能。
Ÿ 评估管理:通过JDBC连接到用户配置的源数据库,根据配置中指定的迁移目标对象,扫描并获取相关的SQL和对象语句信息。结合已有的规则对SQL和对象语句进行匹配,会自动生成相关的兼容性评估报告,便于用户了解迁移的可行性和风险性。
Ÿ 数据校验:选择需要比较的源端和目标端的表,通过JDBC连接,根据配置的抽样规则和校验规则,对两侧的表数据进行比较,并生成校验报告。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。



