Skywalker: https://www.zhihu.com/people/jiang-feng-73-84
我准备用两篇文章讲述 InnoDB lock manager:第一篇是 lock manager 的设计和实现,第二篇是在不同隔离级别下各种 SQL 语句的加锁方式。
在 InnoDB 中,lock 用来实现事务的 2PL(2 Phase Locking),实现可串行化(Serializability)隔离级别。注意,数据库中的 lock 与 latch 有着明显的区分,在 A Survey of B-Tree Locking Techniques 的 3.1 节已经详细分析:
- latch 用来保护临界区,是短暂的、物理的。其实现是 linux 的 pthread mutex
- lock 用来保证事务的隔离性,是持久的、逻辑的。其由数据库内核的 lock manager 实现
当然,在 InnoDB 中不仅仅只有针对数据行的锁(行锁),还有针对表的锁(表锁),统一使用 lock_t 表示
/** Lock struct; protected by lock_sys latches */
struct lock_t {
trx_t* trx; // 拥有该锁的事务
// 同一个事务所有的锁形成一个链表,表头在 trx->lock.trx_locks
UT_LIST_NODE_T(lock_t) trx_locks;
dict_index_t* index; // 数据行所在的索引(如果是行锁)
lock_t* hash; // 所有的锁形成一个哈希表,用于快速查找
// 这个结构体代表的是行锁或表锁,只能其一
union {
lock_table_t tab_lock;
lock_rec_t rec_lock;
};
// 对锁的详细描述,一共 32 个 bit,每个 bit 意义不同。分为:锁的模式、种类和范围
// 0-3 bit(LOCK_MODE_MASK): 模式;LOCK_IS/LOCK_IX/LOCK_S/LOCK_X...
// 4-7 bit(LOCK_TYPE_MASK): 种类;LOCK_TABLE(表锁)/LOCK_REC(行锁)
// 8-? bit(precise modes)详细的行锁信息 :
// LOCK_WAIT 256 表示正在等待锁
// 锁的范围:
// LOCK_ORDINARY 0 表示 next-key lock ,锁住记录本身和记录之前的 gap
// LOCK_GAP 512 表示锁住记录之前 gap(不锁记录本身)
// LOCK_REC_NOT_GAP 1024 表示锁住记录本身,不锁记录前面的 gap
// LOCK_INSERT_INTENTION 2048 插入意向锁
// LOCK_PREDICATE 8192
// LOCK_PRDT_PAGE 16384
uint32_t type_mode;
}
我们看到所有的锁都会形成一个哈希表,表头在 lock_sys_t 中
/** The lock system struct */
struct lock_sys_t {
/** The latches protecting queues of record and table locks */
locksys::Latches latches;
/** The hash table of the record (LOCK_REC) locks, except for predicate
(LOCK_PREDICATE) and predicate page (LOCK_PRDT_PAGE) locks */
hash_table_t *rec_hash;
...
}
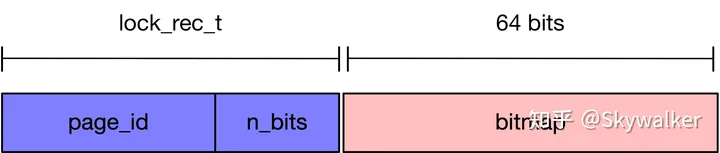
然后,如果 lock_t 是行锁,怎么知道 lock_t 锁住的是哪行?主要靠其成员 lock_rec_t rec_lock。lock_rec_t 表示的是一个事务对一个数据页上所有记录的行锁占有情况
/** Record lock for a page */
struct lock_rec_t {
// 每个 lock_rec_t 都针对一个数据页,代表某个
// 事务对该页中数据行(尽可能多)的行锁占有情况
page_id_t page_id;
// 该 lock_rec_t 能表示这个页多少行的行锁
uint32_t n_bits;
}
在 lock_rec_t 结构体的内存之后,紧邻着的就是表示行锁的 bitmap,最初是只有 64 个 bit(能表示 64 个数据行)
事务占有一个数据行的行锁的行为就是把其相应的 lock_rec_t 中的 bitmap 中次序为 heap no 的 bit 置为 1
我们先回顾一下 heap no 的产生(索引页中每个数据行都有一个 heap no,且唯一)。在数据页中新加入数据行时会为该行分配空间,流程是(page_cur_insert_rec_low):
- 如果 PAGE_FREE 指向的第一个已回收数据行空间足够,则直接覆盖使用,并复用其 heap no 作为新数据行的 heap no
- 否则在 PAGE_HEAP_TOP(空闲空间起始位置)开始分配空间,heap no 是 PAGE_N_HEAP 中保存的值 + 1(目前最大的 heap no + 1)
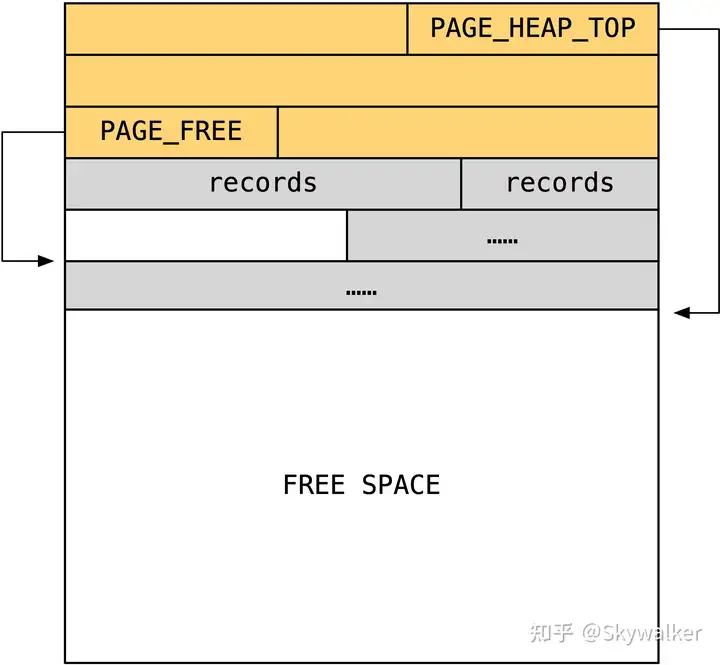
因此,数据页中的每一行都有唯一的 heap no(只是作为一个数据行的 id 而已,与其在页内的偏移无关),可以使用 heap no 作为 lock_rec_t bitmap 的 index。
InnoDB 粗略的分为 record lock(行锁)和 table lock(表锁)。首先我们看一下 lock_t 的组织:
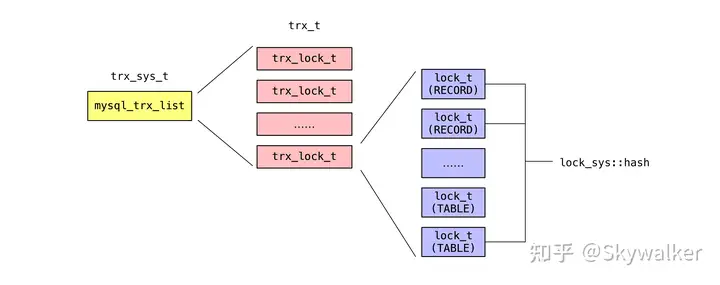
- mysql_trx_list:保存所有活跃事务
- trx_t:对应于一个活跃的事务,成员变量 trx::lock::trx_locks 保存着该事务申请过的所有行锁 / 表锁
- lock_sys_t::hash:所有的 lock_t 创建完之后都会放到哈希表 lock_sys_t::hash 中,方便快速检索
- dict_table_t::locks:保存隶属于这张表的所有表锁(未在图中体现)
Record Lock 的申请
在准备修改一个数据行之前都会尝试去拿到数据行的 record lock,由函数 lock_rec_lock 实现,这个步骤往往在写 undo log 之前(lock_clust_rec_modify_check_and_lock / lock_sec_rec_modify_check_and_lock)。最后在事务提交时才释放(trx_release_impl_and_expl_locks),这就是 2PL(2 Phase Locking)
lock_rec_lock 首先尝试快速、乐观的方式(lock_rec_lock_fast),再尝试悲观、缓慢的方式(lock_rec_lock_slow)。首先看 lock_rec_lock_fast
lock_rec_lock_fast
{
lock_t *lock = lock_rec_get_first_on_page(lock_sys->rec_hash, block);
if (lock == nullptr) {
// 如果 lock_sys->rec_hash 中没有找到这个数据页的行锁,则直接创建一个(第一个)
RecLock rec_lock(index, block, heap_no, mode);
rec_lock.create(trx)
......
} else {
// 如果 lock_sys->rec_hash 中找到了这个数据页的行锁
// 看是不是可以直接使用(需同时满足):
// 1. 该页面只存在一个结构体 lock_t,且这个 lock_t 代表的是行锁
// 2. lock_t 隶属于当前事务
// 3. lock_t.lock_rec_t 中预分配的 bitmap 大小能够满足当前的 heap no
// 直接把 heap no 在 bitmap 对应的 bit 设置为 1,表示加锁完成。否则
// lock_rec_lock_fast 失败,则调用 lock_rec_lock_slow
}
}
这里插入一下 InnoDB 中哈希表的实现(hash0hash.h):
- 有一些固定数目的 hash_cell_t 作为 hash bucket
- 使用链地址法(separate chaining)来解决冲突问题,如右侧当不同的页映射到一个 hash bucket 中时都连接到一个单链表中,表头就是 hash_cell_t::node
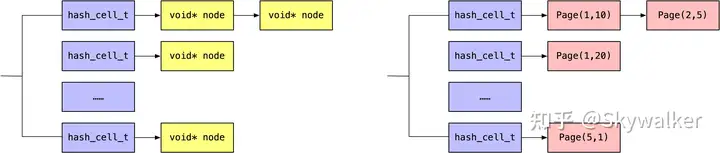
在 InnoDB 中可能会看到这样的代码。HASH_GET_FIRST 就是拿到一个 hash_cell_t 的表头,HASH_GET_NEXT 就是顺着这个单链表拿到下一个元素
for (lock_t* lock = static_cast<lock_t*>(HASH_GET_FIRST(lock_hash, hash));
lock != NULL;
lock = static_cast<lock_t*>(HASH_GET_NEXT(hash, lock))) {
......
}
再看看 lock_rec_lock_slow。函数的行为很清楚:
- 当前事务是否已拥有更高级别的锁?
- 是否和其他事务已持有的行锁冲突?
lock_rec_lock_slow
{
// 1. 当前事务是否已经获得更强级别的行锁?
// 针对特定的数据行(由 block 和 heap no 唯一确定),在 lock_sys::rec_hash 中查找当前事务是否
// 已持有这个数据行的更强的行锁?(例如已持有 X,请求 S)。如果有,则直接返回(无需再申请)
const auto *held_lock = lock_rec_has_expl(checked_mode, block, heap_no, trx);
if (held_lock != nullptr) {
if (checked_mode == mode) {
/* The trx already has a strong enough lock on rec: do nothing */
return (DB_SUCCESS);
}
}
// 2. 在 lock_sys::rec_hash 是否其他事务已持有的该数据行的行锁和和当前申请的行锁冲突?
// (lock_rec_has_to_wait),主要是通过兼容矩阵判断(lock_compatibility_matrix)
// 如果不兼容,则认为有冲突。除非是一些特殊情况此处不详细暂开(比如请求的是 LOCK_GAP,已持
// 有的是 LOCK_REC_NOT_GAP。
// 如果有冲突,则创建一个
const lock_t *wait_for =
lock_rec_other_has_conflicting(mode, block, heap_no, trx);
if (wait_for != nullptr) {
RecLock rec_lock(thr, index, block, heap_no, mode);
// 1. 在 add_to_waitq 里首先标记这个 rec_lock 是 LOCK_WAIT (m_mode |= LOCK_WAIT)
// 2. 把 rec_lock 加入到 lock_sys::rec_hash 中,注意,LOCK_WAIT 模式下需要把 rec_lock
// 放到 hash_cell_t 链表的尾部(否则是头部)
// 3. 在 wait-for graph 中创建一条边(当前事务指向持有行锁事务),供死锁检测算法使用
// 4. 返回 DB_LOCK_WAIT
dberr_t err = rec_lock.add_to_waitq(wait_for);
}
// 当上层函数接收到 DB_LOCK_WAIT 错误时通常会调用 lock_wait_suspend_thread 等待行锁被授予
// 在 lock_sys_t::waiting_threads 中选择一个 slot,等待 slot->event(当然,也可能最后该
// 线程被选定为 deadlock victim)
}
Record Lock 的唤醒
根据 2 Phase Locking,在事务提交时会释放其持有的行锁(lock_rec_dequeue_from_page),把 lock_t 从 trx->lock.trx_locks(链表)和 lock_sys->rec_hash 中删除。并需要唤醒可能等待该行锁的线程(以下代码基于 5.7.18)
void
lock_rec_dequeue_from_page(
/*=======================*/
lock_t* in_lock) /*!< in: record lock object: all
record locks which are contained in
this lock object are removed;
transactions waiting behind will
get their lock requests granted,
if they are now qualified to it */
{
......
space = in_lock->un_member.rec_lock.space;
page_no = in_lock->un_member.rec_lock.page_no;
// 遍历这个数据页的每一个 lock_t
for (lock = lock_rec_get_first_on_page_addr(lock_hash, space, page_no);
lock != NULL;
lock = lock_rec_get_next_on_page(lock)) {
// 如果 lock->type_mode 是 LOCK_WAIT
// 判断这个行锁(记为 lock1)请求是否可以被授予?(lock_rec_has_to_wait_in_queue)
// 再次遍历 lock_sys->rec_hash,对于这个数据页的每一个 lock_t(记为 lock2),判断是否
// 和 lock1 冲突?如果满足以下三点说明冲突:
// 1. lock1 的 heap_no 小于 lock2 的 lock bitmap 大小
// 2. lock2 把对应的 heap_no 锁住了,表明和 lock1 可能有冲突
// 3. 查看兼容性矩阵中 lock1 和 lock2 的请求模式冲突(lock_has_to_wait)
//
// 如果没找到这样的 lock2,则 lock1 的请求被授予,即去掉 lock->type_mode 的 LOCK_WAIT
// 标记,唤醒等待的线程(lock_reset_lock_and_trx_wait)
if (lock_get_wait(lock)
&& !lock_rec_has_to_wait_in_queue(lock)) {
/* Grant the lock */
ut_ad(lock->trx != in_lock->trx);
lock_grant(lock);
}
}
}
下一篇会着重介绍不同 SQL 对应的加锁方式
承接 Skywalker:InnoDB:lock manager (1),这一篇我们研究不同 SQL 对应的加锁方式
MySQL 的默认隔离级别是 Reaptable Read(可重复读),一般来讲 Reaptable Read 的定义是不需要阻止幻读的,但 MySQL 的实现上消除了幻读
幻读(Phantom)
A phantom read occurs when, in the course of a transaction, new rows are added or removed by another transaction to the records being read.
从概念上来讲,只要事务发现一个之前(事务开启后)未见过的数据行,就称作幻读。这里的 "发现" 很有意味,如果事务的执行结果被该数据行所影响,就称之为发现了该数据行
例如:两个事务 T1 / T2,串行执行时 T1 的执行结果,和并行执行时 T1 的执行结果并不相同;而且是由于幻读导致(T1 读到 T2 新插入的数据行)
a write in one transaction changes the result of a search query in another transaction, is called a phantom
从行为上来看,事务发现一个之前未见过的数据行,就是因为事务的 "search query" 的结果被另一个事务改变,则该事务就(可能)会出现幻读。注意,这里的 search query 很广泛,不单指 select 语句,比如 update ... where ...,where 子句也可以叫做 search query(因为也是要查询出来再做修改)。我们看一个存在幻读现象的例子(改变部门 A 的员工工资):
create table t (id int, salary int, department varchar(32), primary key(id), key(deptment));
insert into t values (1,50,'A'),(2,10,'A'),(3,20,'B')
| T1 | T2 |
|---|---|
| update t set salary=salary+20 where department='A' | |
| insert into t values (4,5,'A') | |
| update t set salary=salary-10 where department='A' |
事务 T1 首先把部门 A 员工工资都 +20,随后又都 -10。如果无法阻挡 T2 的 insert,那么 T1 的第二次 update 最终会导致 id=4 的员工工资为负数(-5)。究其原因是因为 T1 的第二次 update 读到了 T2 新产生的 id=4 的数据行(幻读)
注:在 Reaptable Read 隔离级别下,MySQL 采用 MVCC 的方式来处理只读语句(e.g. select ... from ...),无论该语句执行多少次均会看到相同的结果,因此不会出现幻读的现象
消除幻读
想要消除上面的例子中的幻读,一个朴素的想法就是锁住 department 的全部成员,延伸一下就是锁住 where 子句(或叫做 "谓词") 。
不同于 record lock,这种叫 predicate lock(谓词锁),试图锁住一个范围。当然,在申请 predicate lock 时需要检查是否和已有的 predicate lock 冲突,但不幸的是,这是一个 NP-complete 难题。
我们可以简化这个问题,即放大 lock 的范围。比如看这个 SQL:查找 1 班成绩在 80 和 90 分之间的学生
SELECT name FROM students WHERE class = 1 AND score > 80 AND score < 90 FOR UPDATE;我们可以放大范围:锁住 1 班的全体学生,或者 80-90 分的所有班级的学生,根据 students 表的不同索引情况有不同的实现
- students 有一个索引是 class,那么该查询会在 class 的索引上查找值为 1 的 record,找到后直接锁住该 record 即可
- students 有一个索引是 score,那么该查询会锁住 score 这个索引上 80-90 的范围的所有 record(即使该范围没有 record)
在 InnoDB 实现的就是这种锁的策略,更正式的名字叫 next-key locking。具体的行为就是:
- InnoDB 在索引的 B-Tree 叶子节点正/逆序遍历时,一般的对于访问到的 record 要申请 next-key lock。这个 next-key lock 锁住的范围是
下一节我们看看为什么这样的行为会使得事务锁住谓词条件的一个超集,从而保证 next-key locking 是正确的
三种不同范围的 Lock
InnoDB 在 next-key lock (LOCK_ORDINARY)的基础上又增加两种模式:LOCK_GAP / LOCK_REC_NOT_GAP。我们通常讲,对一个记录(例如下图的 B)申请某种类型的 lock 指的是:
- LOCK_ORDINARY:锁住 B 和 A、B 之间的开区间
,最终是 - LOCK_GAP:只锁住 A、B 之间的开区间
- LOCK_REC_NOT_GAP:只锁住 B
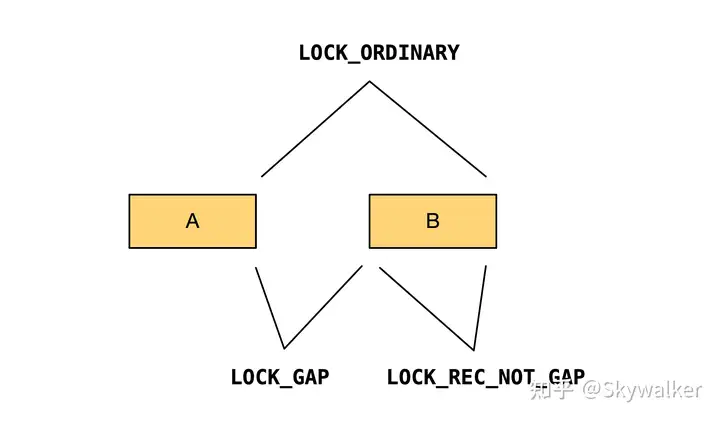
从效果上讲,LOCK_ORDINARY = LOCK_GAP + LOCK_REC_NOT_GAP
三种不同范围 Lock 的兼容性
LOCK_GAP 只锁住一个区间、表示不希望其他任何事务在这个区间插入新的记录。因此如果两个 lock 都是 LOCK_GAP 类型,一般是不冲突的(即你不希望区间内插入新纪录,我也不希望区间内插入新纪录)
同时,LOCK_GAP 和 LOCK_REC_NOT_GAP 也是不冲突的,因此 LOCK_GAP 和 LOCK_ORDINARY 依然不冲突
那么 LOCK_GAP 和什么冲突呢?只和插入的操作冲突
lock_rec_insert_check_and_lock {
// insert 操作依然需要申请 LOCK_GAP,我们举个例子
// create table t (id int, primary key(id));
// insert into t values (2)(4)(6)(8);
// 那么对于 insert into t values (5); 会把 cursor 定位于第一个小于 5
// 的记录上(记录 6)。申请区间(4,6)的 LOCK_GAP,同时这个 lock 的 type_mode
// 具有 LOCK_INSERT_INTENTION 标识。这样如果(4,6)区间存在其他的 LOCK_GAP
// 或 LOCK_ORDINARY,则因为 LOCK_INSERT_INTENTION 标识而会产生冲突
const ulint type_mode = LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION;
const lock_t* wait_for = lock_rec_other_has_conflicting(
type_mode, block, heap_no, trx);
}
LOCK_ORDINARY 和 LOCK_REC_NOT_GAP 则没什么特殊之处。实现可见函数 lock_rec_has_to_wait
// 判断事务1正在申请的 lock 与一个已知的 lock2 是否冲突
lock_rec_has_to_wait(
ulint type_mode, // 事务1申请的锁模式
lock_t* lock2) // 事务2持有的 lock
{
if (trx != lock2->trx
&& !lock_mode_compatible(static_cast<lock_mode>
LOCK_MODE_MASK & type_mode),
lock_get_mode(lock2))) {
// 兼容性矩阵返回"冲突"
// 1. 如果事务1申请是 LOCK_GAP 而且不是在执行插入操作,则与其余 lock 不会冲突
if ((lock_is_on_supremum || (type_mode & LOCK_GAP))
&& !(type_mode & LOCK_INSERT_INTENTION)) {
return(FALSE);
}
// 2. 如果事务1不是在执行插入操作,而且 lock2 是 LOCK_GAP 则表示不冲突
if (!(type_mode & LOCK_INSERT_INTENTION)
&& lock_rec_get_gap(lock2)) {
return(FALSE);
}
// 3. 如果事务1申请的是 LOCK_GAP,lock2 是 LOCK_REC_NOT_GAP 则表示不冲突
if ((type_mode & LOCK_GAP)
&& lock_rec_get_rec_not_gap(lock2)) {
return(FALSE);
}
// 3. 如果事务2是插入操作,则不会与事务1冲突(事务2在先)
if (lock_rec_get_insert_intention(lock2)) {
return(FALSE);
}
// 其余情况表示冲突:比如事务1是插入操作,而且 lock2 是 LOCK_GAP
return(TRUE);
}
// 与持有 lock2 的事务是同一个事务,或者兼容性矩阵返回"兼容"
return(FALSE);
}
正确性论证
下文会通过一些例子来看到不同场景(不同的 SQL、不同的执行计划)下不同的加锁方式。但核心原则就是保证:
- 一个事务检索(search query)的结果不会被另一个事务改变
根据上面的原则,一个简单的实现就是对于一次范围检索,扫描到的每个 record (比如从 A 开始、至 M 结束)都申请 LOCK_ORDINARY。这样封锁住的区间范围是
假设检索的范围是
可以看到这种方法封锁住的区间范围是充分大的。对于
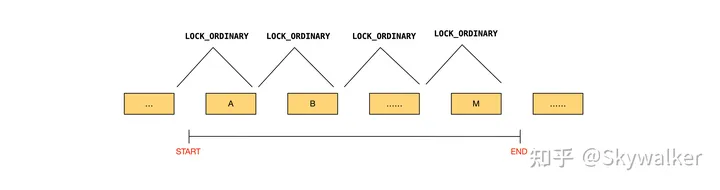
InnoDB 的实现有一些优化,有的场景只需要 LOCK_REC_NOT_GAP / LOCK_GAP 就足够了,这样的话可以减小封锁的范围:
- 规则 1:如果一次检索时至多能有一个 record 被选中,使用 LOCK_REC_NOT_GAP
- 规则 2:等值查询时,当遍历到不满足条件的 record,使用 LOCK_GAP
除此之外的场景全部使用 LOCK_ORDINARY。规则 1 的话,如果至多能有一个 record 被选中时,则当锁住这个 record 后(LOCK_REC_NOT_GAP)其他任何事务都不会导致幻读的发生
规则 2 的话是说对于不符合要求的 record 则无需锁住记录本身。比如这个例子:
create table t (c1 int, c2 varchar(16), c3 int, primary key(c1), index(c2));
insert into t values (1,'A',1),(2,'A',2),(4,'C',3),(5,'D',4),(......)
update t set c3=10 where c2='A'; 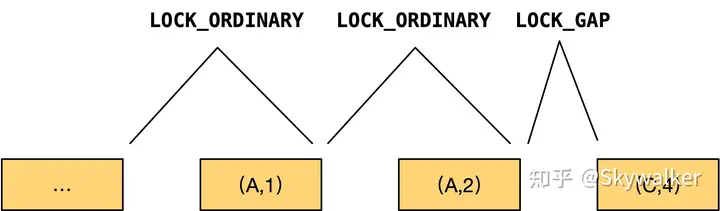
update 语句会选择辅助索引 c2 扫描,(A,1)(A,2) 直至 (C,3) 停止。对于 (C,3) 则只需要申请 LOCK_GAP 而不锁住该记录本身
不锁住 (C,3) 的话,如果另一个事务把 (C,3) 更新为 (A,3) 是否会导致 where c2='A' 检索出的记录发生变化(多出一行)而导致幻读?无需担心,因为辅助索引的 update 是由 delete mark 和 insert 实现,insert (A,3) 会被上图中的 LOCK_GAP 阻塞
更多的例子
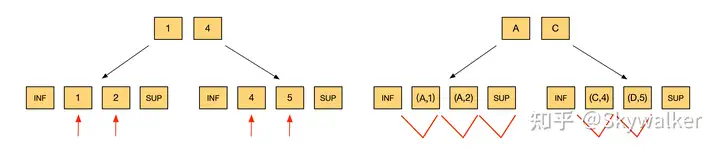
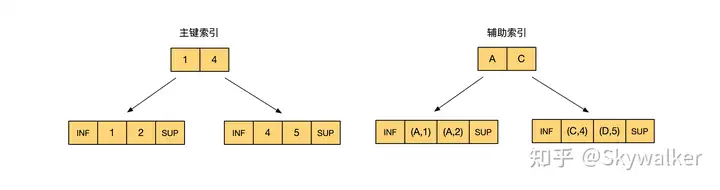
再次借用上面的语句,构建出一个这样的 B-Tree(注:只画出部分 B-Tree)。随后的例子都是在 Reaptable Read 隔离级别下讨论
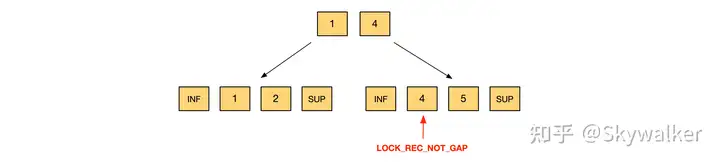
1. 主键索引、等值
update t set c3=10 where c1=4; - 主键索引:等值查询,锁的模式为 LOCK_X | LOCK_REC_NOT_GAP
2. 主键索引、范围
update t set c3=10 where c1<4; 我们看到四个 lock 均是 LOCK_ORDINARY
- 记录 1:锁住的范围是
- 记录 2:锁住的范围是
- 记录 supreme:锁住的范围是
- 记录 4:锁住的范围是
综上,该 SQL 锁住的范围就是
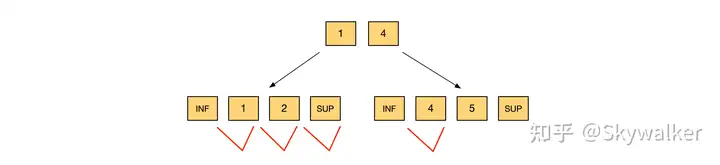
这里的行为就是先把 cursor 置于 B-Tree 的最左叶子节点,然后正向遍历,直至 c1<4 不成立为止。并且对于每个遍历到的 record 申请的 lock 类型均为 LOCK_ORDINARY
对于记录 4 锁住的范围是
3. 辅助索引、等值
update t set c3=10 where c2='C'; 目前申请的是一个 LOCK_ORDINARY 和一个 LOCK_GAP:
- 记录(C,4):锁住的范围是
- 记录(D,5):锁住的范围是
因此锁住的范围就是
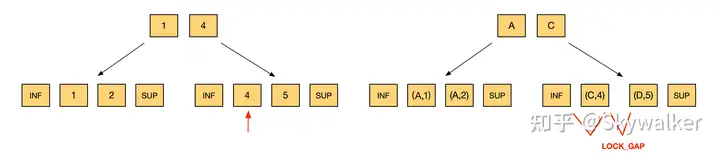
4. 辅助索引、范围
update t set c3=10 where c2<'D'; 对于辅助索引的记录都申请 LOCK_ORDINARY,对于主键索引的记录都申请 LOCK_REC_NOT_GAP