Hi~朋友,关注置顶防止错过消息
MongoDB使用BSON进行数据的存储,BSON是JSON的二进制表现形式,支持比JSON更多的数据类型。
Document结构
Doccument的结构是键值对的形式,其中值可以是任意的BSON type,也可以是Document或者Document的数组。
Document Field
Field必须是字符串且有以下限制:
_id为保留属性,id的值必须是唯一且不可变的,并且类型不能为数组、 regex和undefined,如果id有sub fields,子属性的name不能以$开头
field的名称不能为null字符串
field name可以包含.和$
MongoDB在5.0以后优化了对.和$的支持,允许.和$当前缀,但在访问这些字段时需要借助MongoDB提供的一些方法如$getField
MongoDB的Dcocument不支持重复的Field。
MongoDB使用.来访问数组中的元素或者Document中的field。
Document限制
单条BSON Document最大值不能超过16MB,这是为了防止使用过的内存以及传输过程中消耗过多的带宽,如果要存储超过此大小的Document需要使用MongoDB提供的GridFs API。
Document中的Field是有序的,在进行Document比较时,Field的顺序是有含义的,顺序不同,Document不相等,为了提高查询的执行效率,$project、$addFields、$set和$unset这些操作会对字段重排序
对于写入操作,MongoDB会保留Document字段写入的顺序,但是_id字段总是会作为Document的第一个字段,对于字段的重命名也会导致Document字段的重新排序。
_id Field
MongoDB中,每一个Document必须要存储一个唯一的_id作为主键,如果代码中没有写入这个值,MongoDB会自动生成一个ObjectId进行写入。
MongoDB会在创建集合时对_id字段创建唯一索引。
对于_id字段通常会有以下建议:
使用ObjectId
如果可以,可以使用数据中唯一的字段来充当_id,这样可以节省存储空间和避免额外的索引
使用自增长的数字
如果使用UUID,可以将UUID转换为BinData进行存储,对于BinData类型的数据,如果BinData的子类型值在0-7或128-135并且字节数组的长度是0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24,或者32时存储更加高效
UUID尽可能使用驱动程序自带的BSON UUID。
过滤Document结构
在过滤Document时,通常表达式如下:
{
<field1>: <value1>,
<field2>: { <operator>: <value>},
...
}
更新Document结构
对于更新Document,更新值的表达式通常如下:
{
<operator1>: { <field1>: <value1>, ... },
<operator2>: { <field2>: <value2>, ... },
...
}
Document索引结构
对于Document的索引定义,表达式通常如下:
{ <field1>: <type1>, <field2>: <type2>, ... }
BSON Types
BSON是用于MongoDB进行数据存储和远程调用时的二进制序列化协议,每一种BSON类型都有其对应的数字和字符串表示,如下:
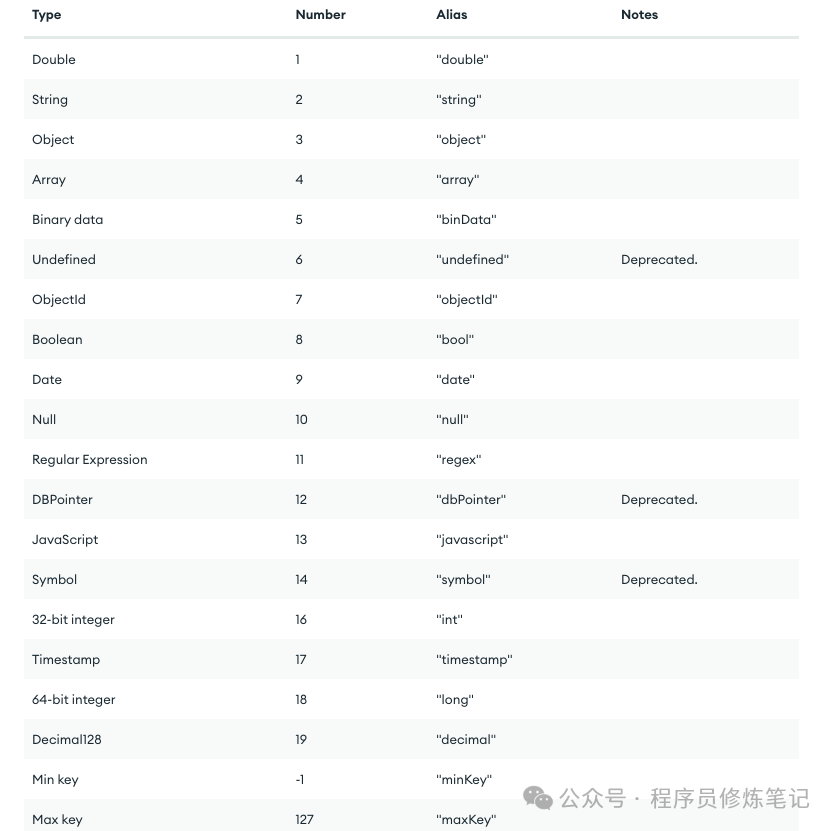
通过$type字段我们可以查出字段为某个类型的Document,如下:
db.products.find({_id: {$type: 7}})
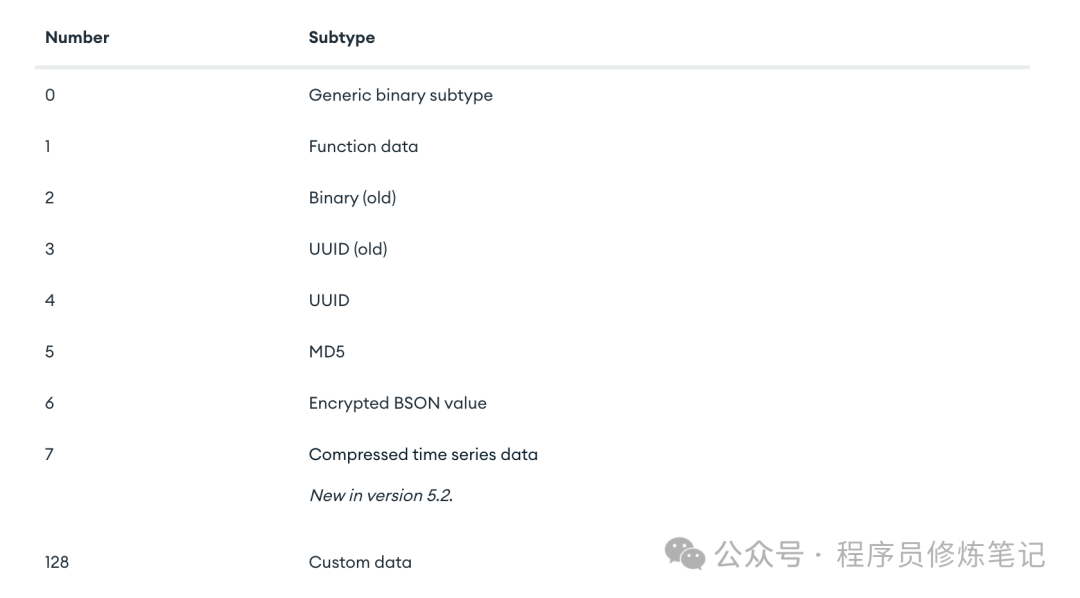
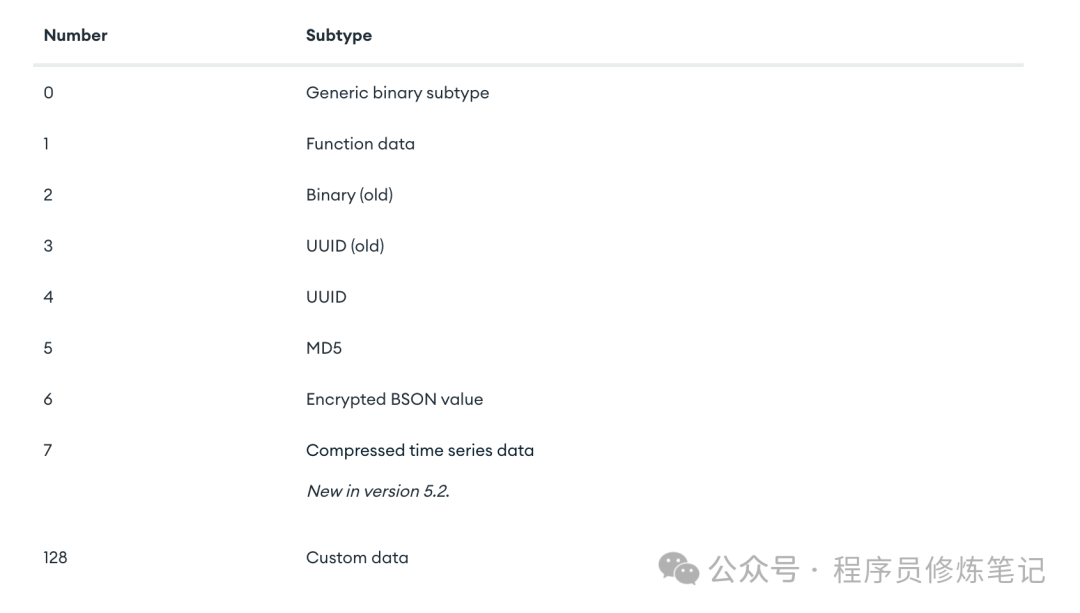
Binary Data
binData类型的数据都有一个subtype用来表示如何解释此二进制数据,如下图:
ObjectId
ObjectId具有小,尽可能的唯一,快速生成且有序的特点,长度为12个字节,主要由以下三部分组成:
4字节的timestamp,Unix秒时间戳,采用大端序存储,不同于BSON Value
5字节的由进程生成的随机值,同一台机器同一个进程该随机值是一样的
3字节的自增计数器,初始值也是随机的,采用大端序存储不同于BSON Value
如果ObjectId在写入时指定了Integer的值,该值将会被用来替换timestamp,ObjectId有可能不是单调递增,原因是ObjectId在同一秒内无法保证递增,并且生成ObjectId的系统时钟也有可能不同。
String
BSON中String的编码格式是UTF8,这可以使得MongoDB能够存储绝大多数国际字符。
Timstamp
在MongoDB内部,BSON的timestamp与常规的Date类型有所不同,它由64bit表示:
最高的32bit是Unix的时间戳time_t,单位为秒
最低的32bits是一个自增的序列号ordinal
在比较Timestamp时,虽然存储使用的是小端序存储,但是所有的平台总是先比较time_t,然后再比较ordinal,这样可以保证不受大小端序的影响。
Date
BSON中的Date存储采用64bit的整数来表示,存储的值为Unix时间戳,单位为毫秒。
MongDB中的比较排序
在不同的BSON types的比较时,从小到大依次为:
MinKey (internal type)
Null
Numbers (ints, longs, doubles, decimals)
Symbol, String
Object
Array
BinData
ObjectId
Boolean
Date
Timestamp
Regular Expression
MaxKey (internal type)
String比较
MongoDB通常使用简单二进制进行比较,在创建Collection时,我们可以通过指定collation option来定义指定语言的比较规则,如字母大小写和重音符号的比较规则,如下:
{
locale: <string>,
caseLevel: <boolean>,
caseFirst: <string>,
strength: <int>,
numericOrdering: <boolean>,
alternate: <string>,
maxVariable: <string>,
backwards: <boolean>
}
locale:指定语言环境,比如en代表英语,默认为simple,表示简单二进制表示
caseLevel:表示是否启用区分大小写的比较,受strength值的影响,当该值为true,strength为1时只比较基本字符串和大小写,strength为2时比较基本字符重音(以及其他可能的次要差异)和大小写
caseFirst:大小写的比较顺序,upper:大写字符排在前面;lower:小写字符排在前面;off:默认值等同于lower
strength:比较的强度级别,1:比较基本字符忽略大小写等其他差异,2:比较基本字符和次要差异(如重音),3:默认级别,比较基本字符、重音及大小写差异,4:比较标点符号,5:比较所有的差异
numericOrdering:是否将数字字符串当做数字进行比较
alternate:是否将空格和标点符号作为基本字符进行比较,non-ignorable:默认值,视为基本字符进行比较,shifted:空格和标点符合strength大于3时才能进行比较
maxVariable:当alternate为shifted时,定义哪些字符可以不被视为基本字符,punct:空格和标点都不是基本字符,space:空格不是基本字符
backwards:确定是否从字符串的末尾开始比较重音符号,false:默认值,从字符串的开头开始比较,true:从字符串的末尾开始比较
Array比较
升序排序时会依据BSON类型进行排序,首先比较最小的元素,如果相同继续比较下一个
降序排序与升序排序相反
当单元素数组和非数组字段比较时,比较的是数组中的元素和非数组字段的值
空数组小于null或者字段缺失的值
Object比较
按按照键值对递归进行比较,首先比较字段类型,如果字段类型相同比较字段名称,如果字段名称相同再比较字段值。
不存在的属性会被视为空的BSON Object,因此{}和{a: null}是同等大小。
BinData
首先比较数据的长度
其次再比较其subtype
最后才是逐字节比较数据
BinData的sub type主要有以下类型:
MongoDB Extended JSON
JSON是BSON的一个子集,为了保留BSON中的数据类型,MOngoDB提供MongoDB Extended JSON来进行支持,MongoDB中的扩展JSON有两种模式:
严格模式:会保留数据类型信息,可读性和交互性变低
宽松模式:不会保留类型信息,可读性和交互性高
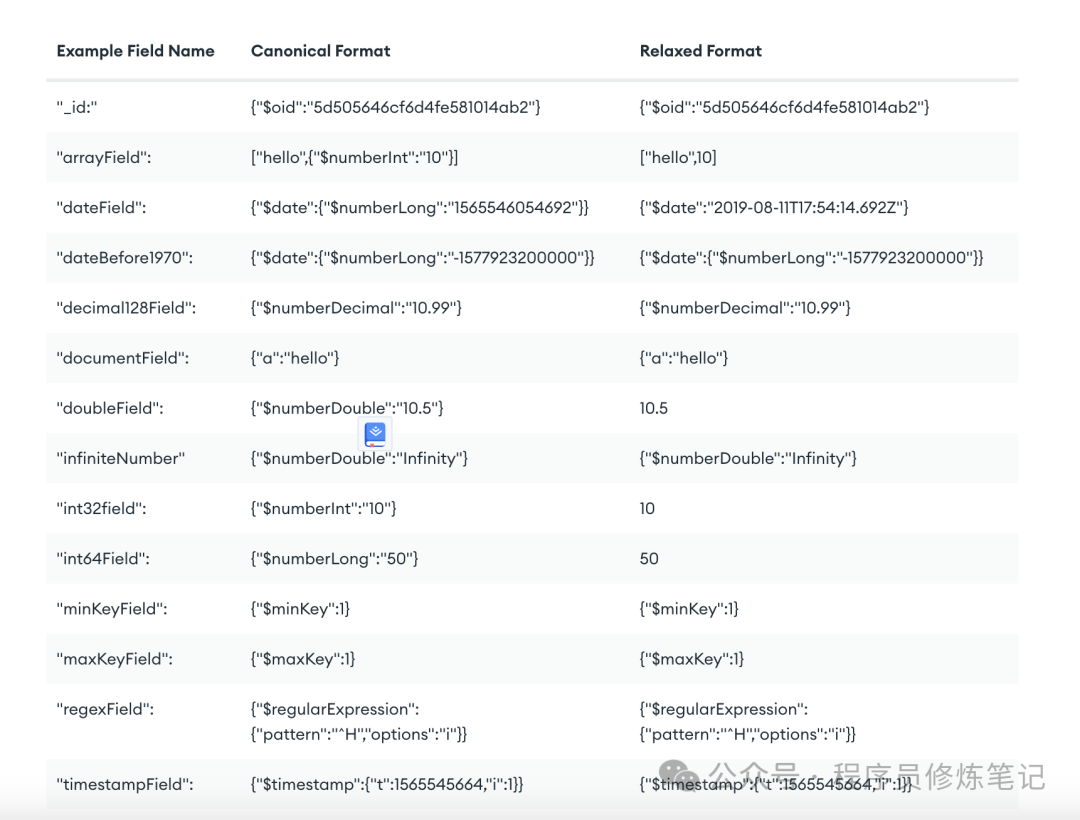
BSON中对应的扩展JSON的严格模式和宽松模式的主要表现形式如下图: