




一、磐维数据库简介
中国移动磐维数据库(ChinaMobileDB),简称“磐维数据库”(PanWeiDB)。是中国移动信息技术中心首个基于中国本土开源数据库openGauss打造的面向ICT基础设施的自研数据库产品。具有高性能、高可靠、高安全、高兼容等特点。

磐维数据库 V1.0 于2022年12月29日发布。
磐维数据库 V2.0 于2023年11月30日发布。
磐维 2.0 目前提供两种部署方式:一种是集中式部署;另一种是分布式部署。
之前介绍了磐维 2.0 数据库集中式(一主两备)的安装,此篇文字是记录磐维 2.0 数据库分布式的部署和使用过程。
二、系统要求
1、硬件环境要求
配置项 | 配置要求 |
内存 | 功能调试建议 32GB 以上。 性能测试和商业部署时,单实例部署建议 128GB 以上。 复杂的查询对内存的需求量比较高,在高并发场景下,可能出现内存不足。此时建议使用大内存的机器,或使用负载管理限制系统的 并发。 |
CPU | 功能调试最小 1×8 核 2.0GHz。 性能测试和商业部署时,单实例部署建议 2×16 核 2.0GHz。 CPU 超线程和非超线程两种模式都支持。 虚拟机环境下,指令集应包含 rdtscp |
磁盘 | 用于安装 PanWeiDB 的硬盘需最少满足如下要求: • 至少 1GB 用于安装 PanWeiDB 的应用程序 • 每个主机需大约 300MB 用于元数据存储 • 预留 70%以上的磁盘剩余空间用于数据存储 建议系统盘配置为 Raid1,数据盘配置为 Raid5,且规划 4 组 Raid5 数据盘用于安装 PanWeiDB。 有关 Raid 的配置方法请参考硬件厂家的手册或互联网上的方法进行 配置,其中 Disk Cache Policy 一项需要设置为 Disabled,否则机器异常掉电后有数据丢失的风险。 PanWeiDB 支持使用 SSD 盘作为数据库的主存储设备,支持 SAS 接口和 NVME 协议的 SSD 盘,以 RAID 的方式部署使用 |
网络 | 300 兆以上以太网。 建议网卡设置为双网卡冗余 bond。 有关网卡冗余 bond 的配置方法请参考硬件厂商的手册或互联网上的方法进行配置。 |
推荐配置:
资源 | 物理机环境 | 虚拟机环境 |
CPU | 2*10(cores)及以上 | 2*10(cores)及以上 |
内存 | 128G 及以上 | 单个节点 8G 及以上 注意:若一台虚拟机上部署 N 个节点,要求内存预留8N |
磁盘 | SSD 500GB 及以上 | SSD/SAS/SATA 100GB 及以上 |
网络 | 10GB 及以上 | 1000MB 或 10G |
2、软件环境要求
软件类型 | 配置描述 |
Linux 操作系统 | ARM: CentOS 7.4-7.9 Debian 10.3、10.10 Kylin V10 openEuler 22.09 UOS V20 Uniontech 20 |
X86: BCLinux 21.10 CentOS 7.4-7.9 Debian 8.9、9.0、10.3 Kylin V10、V3.5、V3.3 Kylinsecos 3.5 nfs 4.0 openEuler 20.03 LTS Rhel 8.6、8.7 ubuntu 18.04 UOS V20 Uniontech 20 | |
Linux 文件系统 | 剩余 inode 个数 > 15 亿(推荐) |
指令集 | rdtscp(仅虚拟机环境需要) |
3、软件依赖要求
所需软件 | 建议版本 |
bison | 2.7-4 |
flex | 2.5.31 以上 |
libaio | 0.3.109-13 |
patch | 2.7.1-10 |
bzip2 | 1.0.6 |
三、安装前准备
1、主机准备及规划
(1)创建用于部署数据库的虚拟机
由于是仅用于测试,而且本机资源相当有限,因此准备在三台vmware虚机上部署磐维分布式数据库集群。
三台vmware虚机配置如下:
| 主机名 | 主机IP | CPU | 内存 | SWAP |
|---|---|---|---|---|
| panwei-d01 | 192.168.20.41 | 2核 | 4GB | 4GB |
| panwei-d02 | 192.168.20.42 | 2核 | 4GB | 4GB |
| panwei-d03 | 192.168.20.43 | 2核 | 4GB | 4GB |
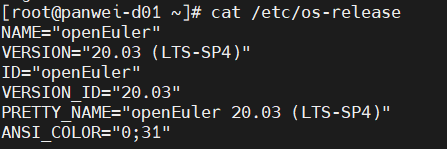
(2)最小化安装openEuler
下载openEuler-20.03操作系统文件,并最小化安装到以上创建的虚拟机上
openEuler-20.03-LTS-SP4-x86_64 操作系统ISO文件下载地址如下:
https://www.openeuler.org/en/download/archive/
安装后的操作系统信息如下:
(3)规划主机角色及端口
三台主机在分布式数据库集群中的角色及端口规划如下:
| 主机名 | panwei-d01 | panwei-d02 | panwei-d03 | |||
| 主机IP | 192.168.20.41 | 192.168.20.42 | 192.168.20.43 | |||
| ha角色端口 | ha:20001 | |||||
| dcs角色端口 | dcs:2379 | dcs:2379 | dcs:2379 | |||
| gtm角色端口及agent端口 | gtm:6666 | 8001 | gtm:6666 | 8002 | ||
| cn角色端口及agent端口 | cn:5432 | 8003 | cn:5432 | 8004 | cn:5432 | 8005 |
| dn1角色端口及agent端口 | dn1_3(S):15432 | 8008 | dn1_1(P):15432 | 8006 | dn1_2(S):15432 | 8007 |
| dn2角色端口及agent端口 | dn2_2(S):20010 | 8010 | dn2_3(S):20010 | 8011 | dn2_1(P):20010 | 8009 |
2、安装系统依赖包
启动三台虚拟机,挂载好openEuler的ISO文件,并设置好本地yum源,然后执行如下:
rpm -q bison flex libaio patch bzip2 tar
对于缺失的系统依赖包,要安装上:
yum install -y bison flex patch tar
3、检查是否支持 rdtscp
cat /proc/cpuinfo | grep rdtscp
4、关闭防火墙和SeLinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
5、创建用户组和用户
groupadd dbgrp
useradd -m -d /home/omm omm -g dbgrp
passwd omm
注:对于设置的omm的密码,要牢记。
6、添加omm用户至sudoer列表
visudo
添加如下内容:
omm ALL=(ALL) NOPASSWD:ALL
7、配置内核参数
vi /etc/sysctl.conf
添加
kernel.sem = 40960 2048000 40960 20480
执行sysctl -p 使之生效。
8、采用 NTP 服务方式来保证各节点间的时间同步
由于是本地虚机测试环境,并不是生产环境,因此保证三台虚机时间相同即可,此步略过。
9、配置互信
在所有节点创建 omm 用户免密登录。需在所有节点使用 omm 用户进行如下操作:
mkdir ~/.ssh
chmod 700 ~/.ssh
ssh-keygen -t rsa
将公钥文件上传至同集群所有节点(包括本节点),即可实现免密登录(此操作需输入omm密码)
ssh-copy-id omm@各节点主机IP
10、创建安装目录
mkdir -p /home/omm/omm_package
11、上传数据库安装文件并解压
将数据库安装文件上传到第一个虚机的安装目录,并解压,过程如下:
cd /home/omm/omm_package
tar xvf PanWeiDB_V2.0_dist_S2.0.1_B02_x86_64.tar.gz
tar xvf PanWeiDB_V2.0_dist_S2.0.1_B02_x86_64_om.tar.gz
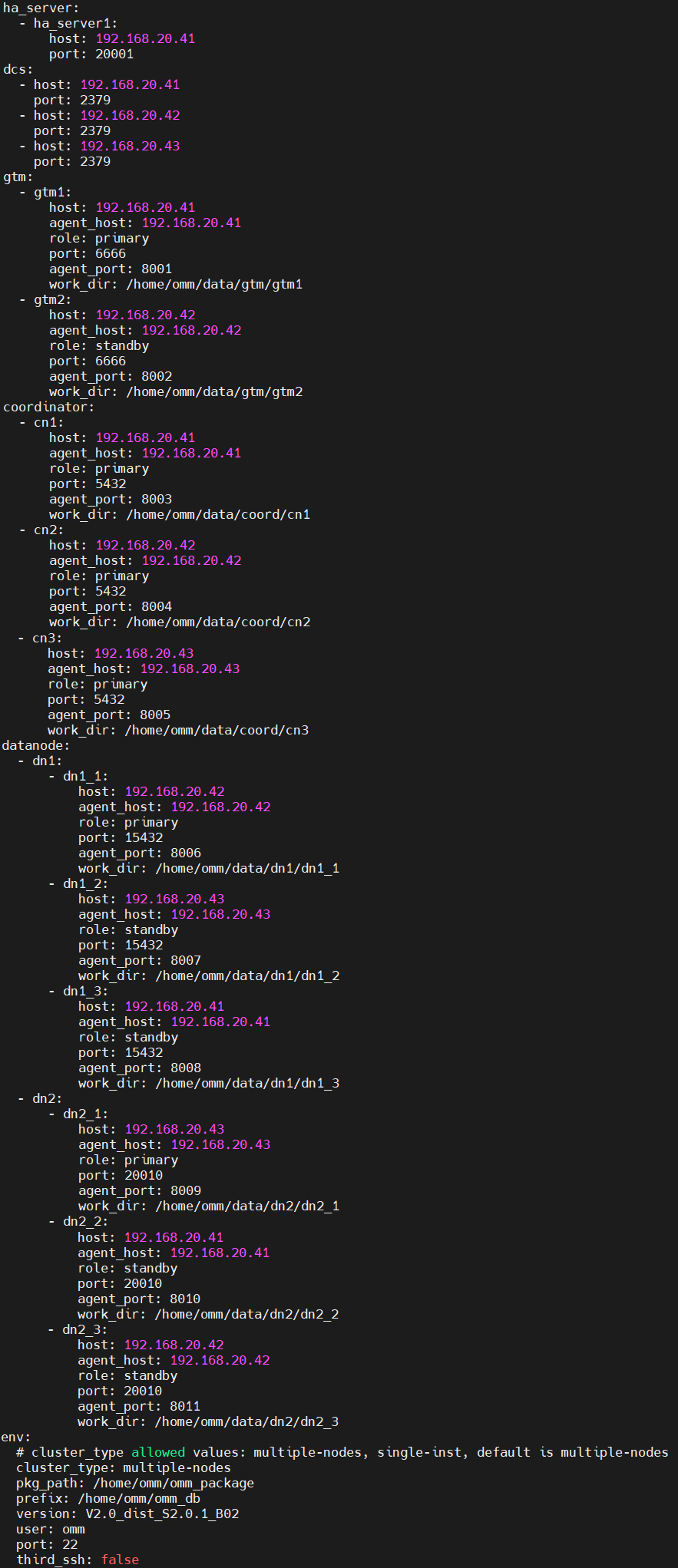
12、编辑分布式安装配置的yml文件
经过以上操作,在安装目录下,有一个文件panwei.yml,这是分布式安装的配置文件,可以按要求,对其进行编辑。
示例内容如下:
四、安装分布式数据库集群
以omm登录第一台虚机,执行安装,安装过程大约10分钟左右,如果成功,则显示Success,操作过程截图如下:

安装过程的详细信息(包括报错信息),可以查看安装日志文件,如下所示:

成功安装后,可以看到用于集群DCS的etcd状态如下:

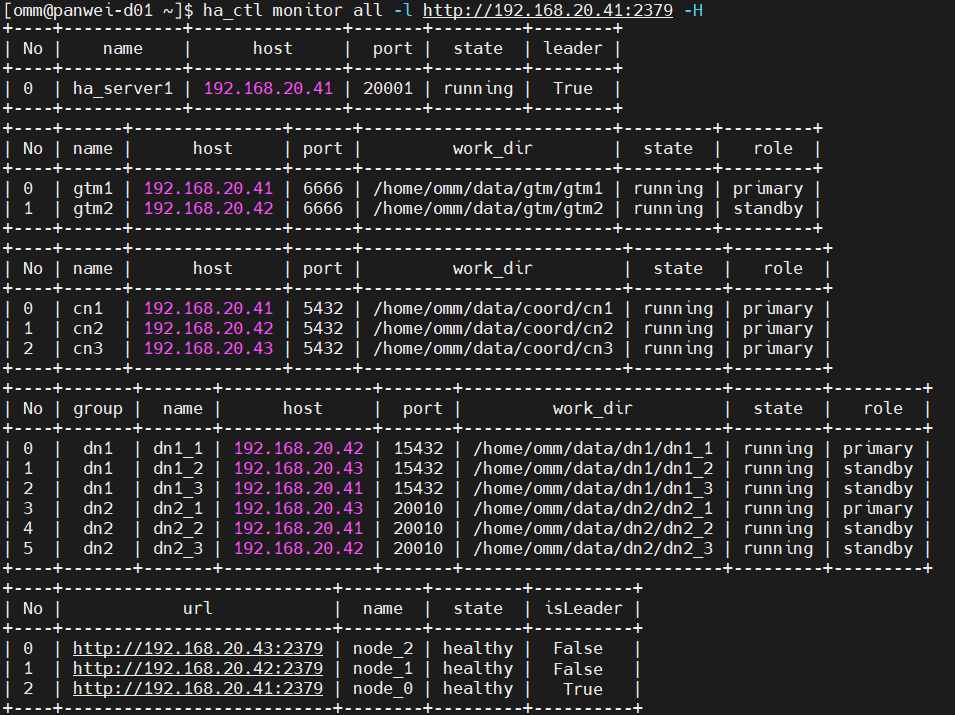
五、检查分布式数据库集群各节点组件的状态
六、访问数据库
是通过CN节点,访问分布式磐维数据库的。在本次部署的分布式数据库集群中,CN节点的访问端口均为5432
1、通过系统自带的命令行客户端gsql访问数据库
关于gsql的使用,可以参看“gsql --help”的帮助信息。以下是通过CN节点的5432端口登录数据库的操作截图:
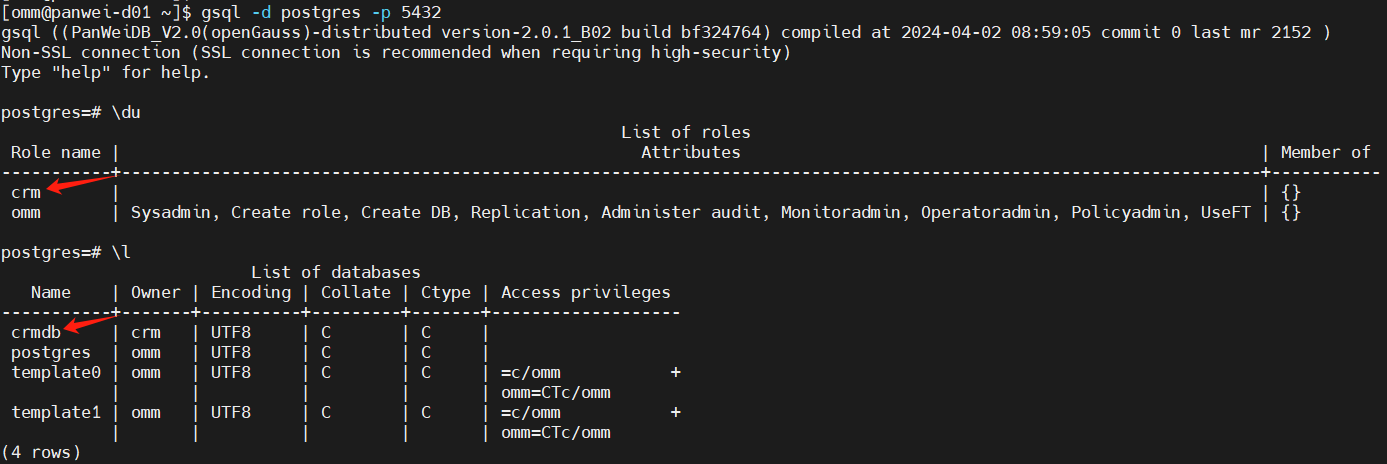
注:上图中的数据库用户crm,以及数据库crmdb,是后创建的,用于测试。
2、通过DBeaver图形客户端访问数据库
(1)客户端白名单设置
将客户端的IP或IP网段,设置为可访问数据库的白名单,操作示例如下:

(2)启动DBeaver客户端程序

(3)新建立数据库连接
在设置好数据库连接的相关信息后,点击左下侧的“测试连接”,如成功连接,则显示如下:

成功登录数据库后,显示如下:
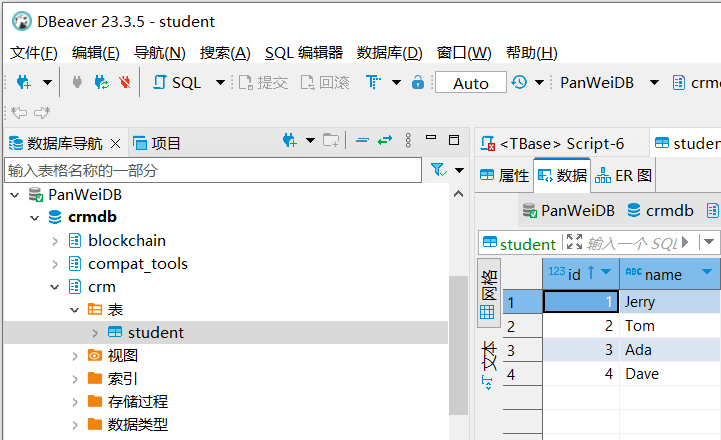
七、在磐维分布式数据库中对表数据分布的测试
1、默认创建的表
(1)以默认的方式创建一个测试表
CREATE TABLE student (
id int,
name varchar(20)
);
对于以默认方式创建的表,默认是哈希分片的方式,将表数据分布到各DN数据组中,如下:
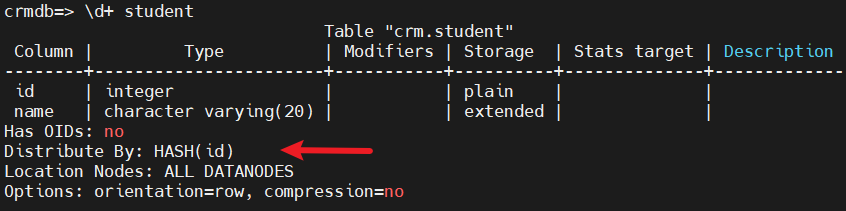
(2)向表中插入数据
向表中批量插入100条测试数据
(3)查看表数据的分布情况
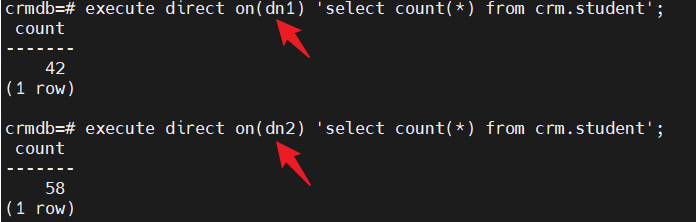
可以看到以上表中的数据,默认是以第一个列做为哈希散列,将数据比较均衡的分布到各个DN节点上。
而对于实际的业务数据表,为了提高整体的访问性能,一般应选用经常JOIN的列或GROUP的列,做为哈希分布的列。
(4)哈希分布表的查询计划
对于全表的查询,是需要遍历所有DN节点。如下所示:
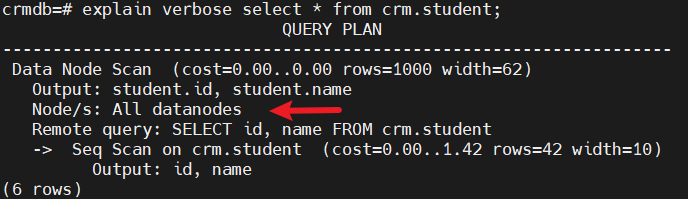
而对于在某个DN节点的上数据,则仅需查询这个DN节点,如下所示:
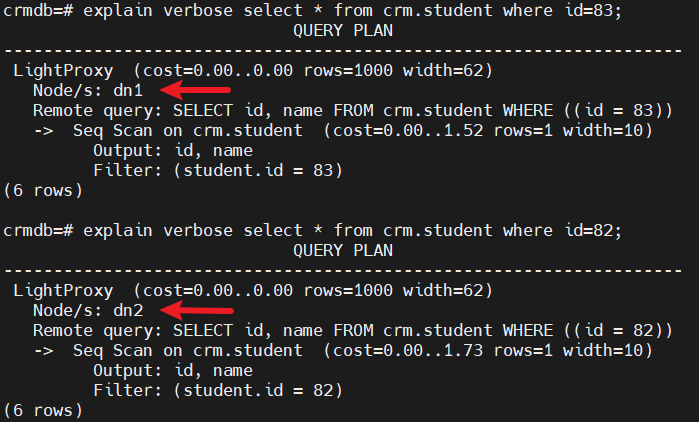
2、复制表
对于数据量比较小,数据变更不大,而且会被频繁访问的表,比如一些业务系统的参数表,则可创建为复制表。
这是在每个DN上都有一份全量的表数据。这样可避免join的重分布操作,减少网络开销,提升性能。
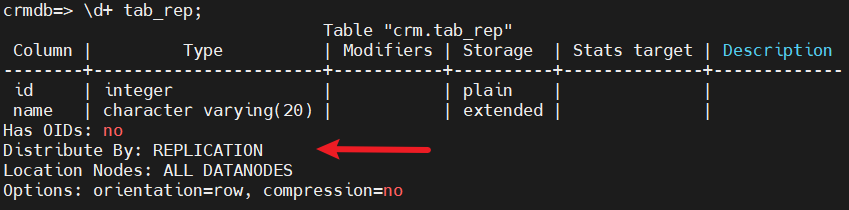
(1)创建复制表
CREATE TABLE tab_rep (
id int,
name varchar(20)
) distribute by replication;
(2)向复制表中插入数据
向复制表中插入10条测试数据。
(3)查看复制表数据的分布情况
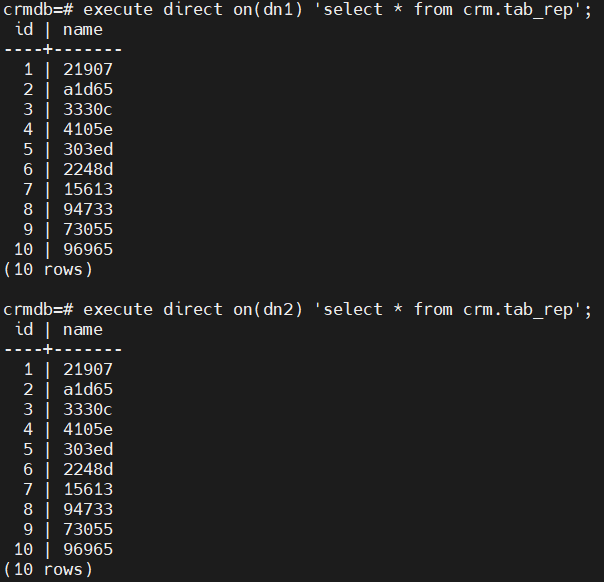
可以看到,复制表,在每个DN上,都有一份完整的数据。
(4)复制表的查询计划
由于复制表是在每个DN节点上都有一份完整的数制,因此对于复制表的查询,仅查询CN当前连接的DN节点上的表数据,如下:
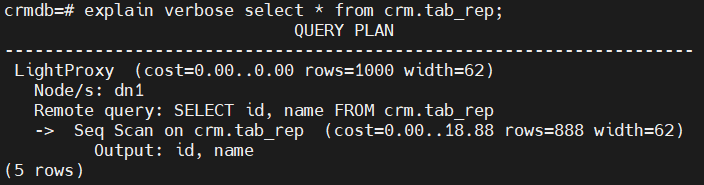
对于表数据的分布,除了上述的哈希表、复制表,还有range 和 list 等方式,后续再进行测试。
八、高可用测试
通过手工停掉磐维数据库集群各节点上的数据库服务进程(gtm、cn、dn),来测试整个集群的高可用性。
在手工停掉以上服务进程后,系统会很快监测到这个情况,并自动重启和恢复了相应服务进程。
这个监护保障机制,是通过ha_agent机制来实现的。
感兴趣的小伙伴,可以尝试,你会发现磐维数据库的抗干扰和自愈能力确实很强!
九、启停数据库集群
1、停止集群

2、启动集群

注:由于我本机的资源有限,三台虚拟都是建在外挂U盘上的,因此数据库集群启动时间稍长,大约7~8分钟。
