




Apache Doris最初是百度为解决凤巢统计报表的专用系统而开发的。随着百度业务的快速发展,它逐渐承担起更多内部业务的统计报表和多维分析需求。由于其在大数据处理方面的卓越表现,Apache Doris最终贡献给了Apache软件基金会,成为开源社区的一员。
2020年2月,百度Doris团队的部分成员离职创业,他们基于Apache Doris开发了一款商业化闭源产品,命名为DorisDB。这就是StarRocks的前身,后面因为涉及到版权问题,最终改名为StarRocks。
StarRocks在继承了Apache Doris的优秀基因的基础上,进一步拓展了商业化功能,提供了更加完善的大数据处理和分析能力。在实际应用中,StarRocks以其高性能、低延迟和易扩展的特点,广泛应用于各种大数据场景,如实时数据分析、多维报表、数据仓库等。它可以帮助企业快速构建稳定、高效的大数据系统,提升数据处理和分析能力。
StarRocks功能改进
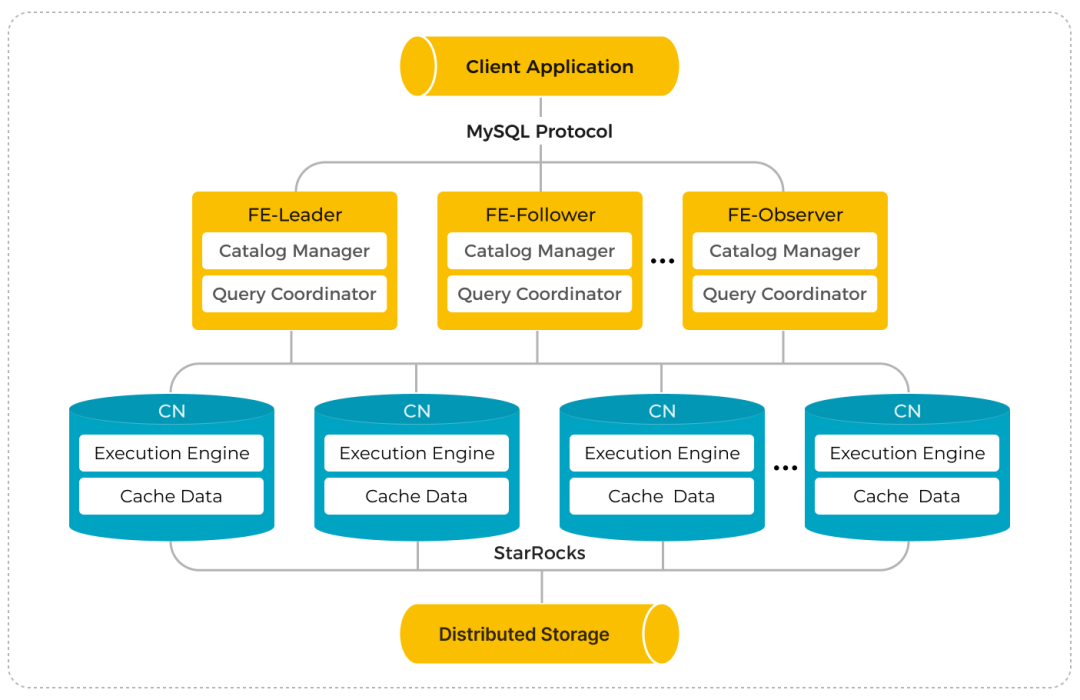
存算分离架构
从StarRocks 3.0开始支持以存算分离架构部署StarRocks集群,在存算分离的模式下,StarRocks将数据存储在对象存储(S3兼容)或HDFS中,本地盘进用作热数据缓存,用以加速查询。
在v3.1版本之后,存算分离集群由FE和CN节点组成,相比存算一体架构,StarRocks的存储计算分离架构提供以下优势:
廉价且可无缝扩展的存储。
弹性可扩展的计算能力。由于数据不存储在 CN 节点中,因此集群无需进行跨节点数据迁移或 Shuffle 即可完成扩缩容。
热数据的本地磁盘缓存,用以提高查询性能。
可选异步导入数据至对象存储,提高导入效率。
数据分布
StarRocks针对业务上的一些痛点,增加了一些好用的新分区类型,并对动态分区做了一些改进。
表达式分区
在v3.0版本后,StarRocks支持设置表达式来自动分区,针对常见的按照连续日期范围或枚举值来查询管理数据的场景,仅需在创建表时指定分区表达式,后续在数据导入时,StarRocks就会根据提前设定好的分区规则自动创建的分区,您无需再建表时预先手动/批量创建大量分区。
StarRocks支持下面两种分区表达式:
时间函数表达式:在建表时指定日期类型、分区列和分区粒度,StarRocks会根据导入的数据和分区表达式,自动创建分区并且设置分区的起止时间。
列表达式(v3.1后):在建表时指定分区列后,StarRocks会根据导入的数据分区列值来自动划分并创建分区。
时间表达式分区示例
假设我们需要建一张表存储工厂的用电信息,可以用下面的语句创建一个时间表达式分区表,每天自动新建一个分区,并自动删除180天前的数据:
CREATE TABLE e_usage_info (
id BIGINT,
factory_id BIGINT,
energy_used DECIMAL(32,2),
dt DATETIME NOT NULL
)
DUPLICATE KEY(id, factory_id)
PARTITION BY date_trunc('day', dt)
DISTRIBUTED BY HASH(factory_id)
PROPERTIES(
"partition_live_number" = "180"
);
列表达式分区示例
假设需要建一张表来按城市存储网站访问者的信息,用下面的语句创建一个列表达式的分区表,StarRocks会按照城市来自动创建分区,提高查询性能。
CREATE TABLE access_log (
id BIGINT,
city VARCHAR(30) NOT NULL,
ip VARCHAR(30) NOT NULL,
dt VARCHAR(30) NOT NULL
)
DUPLICATE KEY(city, ip)
PARTITION BY (dt, city)
DISTRIBUTED BY HASH(`city`);
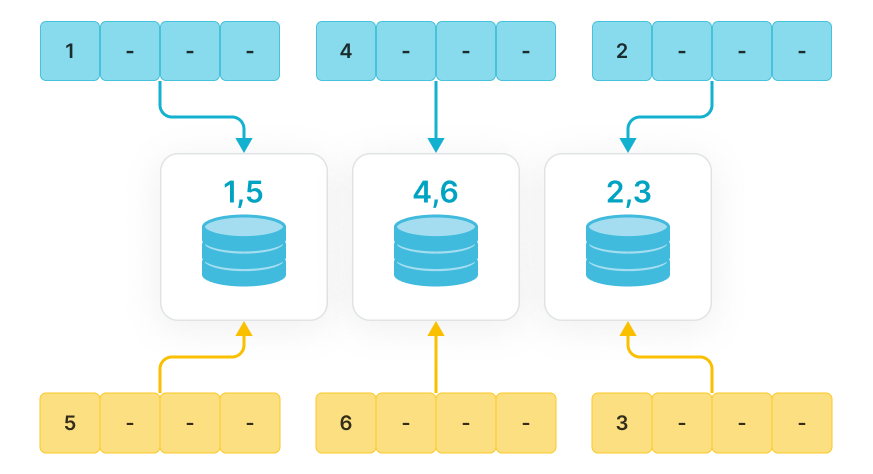
List分区
当需要显式列出每个List分区所包含的枚举值列表,并且值不需要连续,当新数据导入表中时,StarRocks会根据数据的分区列值与分区的映射关系将数据分配到相应的分区中。
List分区和列表达式分区最大的区别是,List分区可以在一个分区内包含多个枚举值,而列表达式分区每个分区仅有一个枚举值。
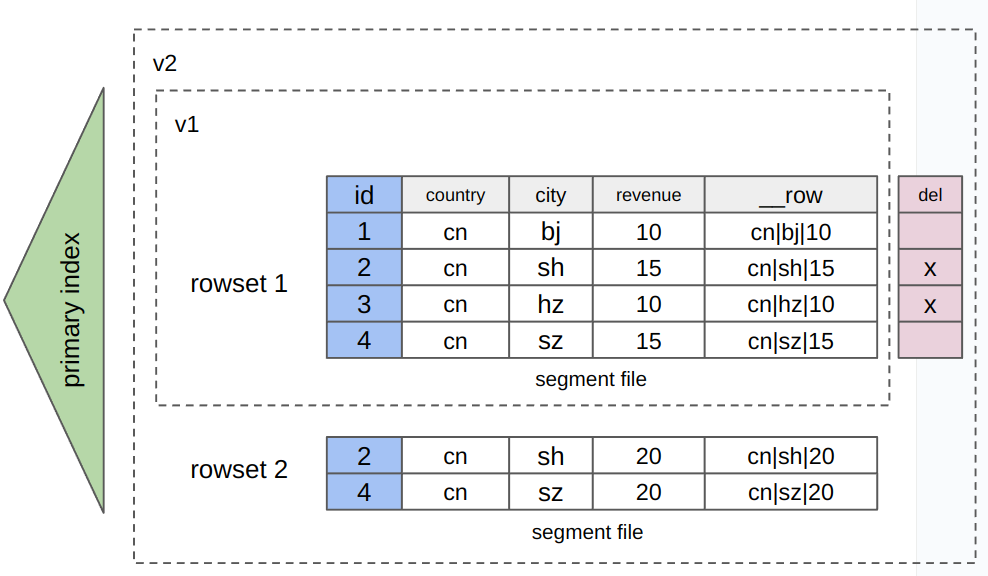
行列混存表
StarRocks默认按照列存的方式存储数据,相比与按行存储的方式,可以大大提高复杂查询的性能。在v3.2.3之后,StarRocks支持了行列混存的表存储格式,会自动创建一个额外的__row列存储二进制的行数据,额外占用部分存储空间。在保留原有列存的高效分析能力的同时,还可以支撑基于主键的高并发,低延时点查,以及数据部分列更新等场景。
创建一个行列混存表:
CREATE TABLE users (
id BIGINT NOT NULL,
country STRING,
city STRING,
revenue BIGINT
)
PRIMARY KEY (id)
DISTRIBUTED BY HASH(id)
PROPERTIES ("storage_type" = "column_with_row");
数据压缩
StarRocks支持对表和索引数据进行压缩,数据压缩可以节省存储空间,还可以提高I/O密集型任务的性能。(压缩和解压缩需要额外的CPU资源)
StarRocks 支持四种数据压缩算法:LZ4、Zstandard(或 zstd)、zlib 和 Snappy。
可以在创建表时为其设置数据压缩算法(后续无法修改):
CREATE TABLE `data_compression` (
`id` INT(11) NOT NULL,
`name` CHAR(200) NULL
)
ENGINE=OLAP
UNIQUE KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`)
PROPERTIES (
"compression" = "ZSTD"
);
使用下面命令查看指定表采用的压缩算法:
mysql> SHOW CREATE TABLE data_compression\G
*************************** 1. row ***************************
Table: data_compression
Create Table: CREATE TABLE `data_compression` (
`id` int(11) NOT NULL COMMENT "",
`name` char(200) NULL COMMENT ""
) ENGINE=OLAP
UNIQUE KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`)
PROPERTIES (
"compression" = "ZSTD",
"fast_schema_evolution" = "true",
"replicated_storage" = "true",
"replication_num" = "3"
);
1 row in set (0.00 sec)
使用tpch来生成测试数据,分别插入使用四种压缩参数的lineitem表,查看各自的空间占用情况:
启用LZ4的压缩
mysql> show data from lineitem;
+-----------+-----------+----------+--------------+----------+
| TableName | IndexName | Size | ReplicaCount | RowCount |
+-----------+-----------+----------+--------------+----------+
| lineitem | lineitem | 1.789 GB | 96 | 59986052 |
| | Total | 1.789 GB | 96 | |
+-----------+-----------+----------+--------------+----------+
2 rows in set (0.00 sec)
启用zlib的压缩
mysql> show data from tpch.lineitem;
+-----------+-----------+----------+--------------+----------+
| TableName | IndexName | Size | ReplicaCount | RowCount |
+-----------+-----------+----------+--------------+----------+
| lineitem | lineitem | 1.397 GB | 96 | 59986052 |
| | Total | 1.397 GB | 96 | |
+-----------+-----------+----------+--------------+----------+
2 rows in set (0.00 sec)
启用zstd的压缩
mysql> show data from tpch.lineitem;
+-----------+-----------+----------+--------------+----------+
| TableName | IndexName | Size | ReplicaCount | RowCount |
+-----------+-----------+----------+--------------+----------+
| lineitem | lineitem | 1.490 GB | 96 | 59986052 |
| | Total | 1.490 GB | 96 | |
+-----------+-----------+----------+--------------+----------+
2 rows in set (0.01 sec)
启用Snappy的压缩
mysql> show data from tpch.lineitem;
+-----------+-----------+----------+--------------+----------+
| TableName | IndexName | Size | ReplicaCount | RowCount |
+-----------+-----------+----------+--------------+----------+
| lineitem | lineitem | 1.731 GB | 96 | 59986052 |
| | Total | 1.731 GB | 96 | |
+-----------+-----------+----------+--------------+----------+
对于7.4G的裸数据,各自压缩的大小如下所示,可以看到,在这个数据集中四个压缩算法的压缩率排名为:zlib > zstd > Snappy > LZ4
| 压缩算法 | 压缩后表大小 |
|---|---|
| LZ4 | 1.789 GB |
| zlib | 1.397 GB |
| zstd | 1.490 GB |
| Snappy | 1.731 GB |
性能测试
测试环境如下:
| 系统环境 | 数据库 | 节点 | 硬件环境 |
|---|---|---|---|
| Rocky Linux 8.6 | Doris 2.1.3-rc09 | doris-01 | 8核8G内存20GB存储,x86_64 |
| Rocky Linux 8.6 | Doris 2.1.3-rc09 | doris-02 | 8核8G内存20GB存储,x86_64 |
| Rocky Linux 8.6 | Doris 2.1.3-rc09 | doris-03 | 8核8G内存20GB存储,x86_64 |
| Rocky Linux 8.6 | StarRocks 3.3.0-rc01 | starrocks-01 | 8核8G内存20GB存储,x86_64 |
| Rocky Linux 8.6 | StarRocks 3.3.0-rc01 | starrocks-02 | 8核8G内存20GB存储,x86_64 |
| Rocky Linux 8.6 | StarRocks 3.3.0-rc01 | starrocks-03 | 8核8G内存20GB存储,x86_64 |
TPCH性能测试
下载测试脚本并生成数据
wget https://starrocks-public.oss-cn-zhangjiakou.aliyuncs.com/tpch-poc-1.0.zip
unzip tpch-poc-1.0
cd tpch-poc-1.0
sh bin/gen_data/gen-tpch.sh 10 data_10
修改conf/starrocks.conf里的mysql地址和端口号。
创建测试表并导入数据
sh bin/create_db_table.sh ddl_100
# 导入数据
sh bin/stream_load.sh data_10
跑benchmark测试
sh bin/benchmark.sh
测试结果
| SQL | Doris执行时间(ms) | StarRocks执行时间(ms) |
|---|---|---|
| Q1 | 650 | 430 |
| Q2 | 80 | 93 |
| Q3 | 136 | 156 |
| Q4 | 86 | 140 |
| Q5 | 240 | 303 |
| Q6 | 50 | 43 |
| Q7 | 173 | 433 |
| Q8 | 200 | 280 |
| Q9 | 383 | 510 |
| Q10 | 436 | 256 |
| Q11 | 193 | 240 |
| Q12 | 76 | 76 |
| Q13 | 353 | 333 |
| Q14 | 60 | 63 |
| Q15 | 80 | 86 |
| Q16 | 166 | 116 |
| Q17 | 76 | 143 |
| Q18 | 493 | 446 |
| Q19 | 106 | 106 |
| Q20 | 140 | 90 |
| Q21 | 293 | 390 |
| Q22 | 123 | 103 |
| Total | 4593 | 4836 |
欢迎大家关注我们的技术分享公众号,会经常分享最新的前沿数据库技术(点击下方公众号链接即可),谢谢大家
