




相较于MR的工作流程,Flink作为实时处理计算框架会有哪些不同呢。这里结合一个简单的例子,来分析下它的源码。
比如,通过Flink将一个简单的文本进行拆分,这个实现起来很简单:
构造好环境后,将文本加入数据源,使用flatmap方法进行处理.
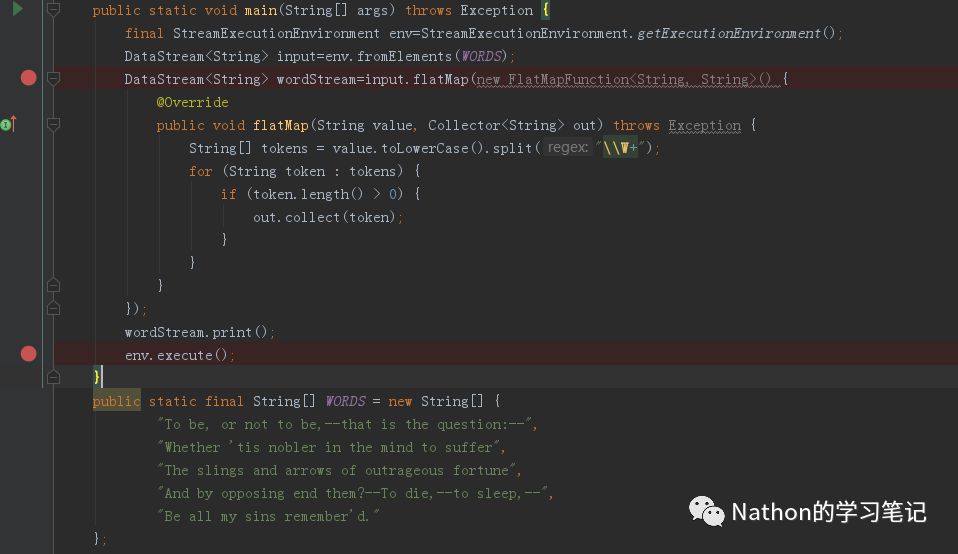
关键是这里我们可以跟踪下源码,看看底层是如何工作的:
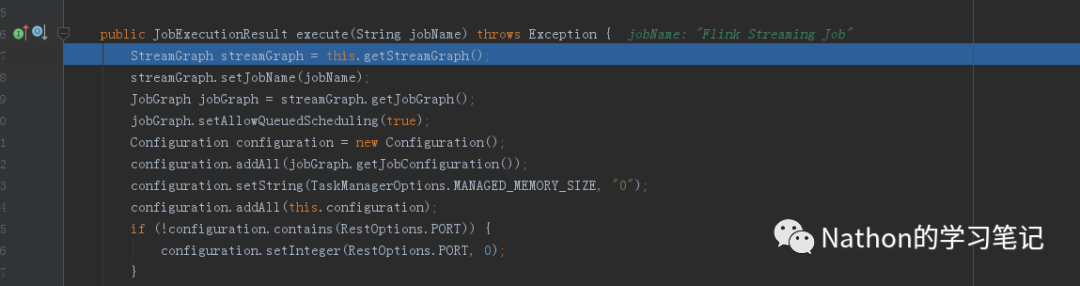
在调用execute方法后,Flink会去生成streamGraph,而这个streamGraph中会去计算当前应用对应的transformations有多少个.
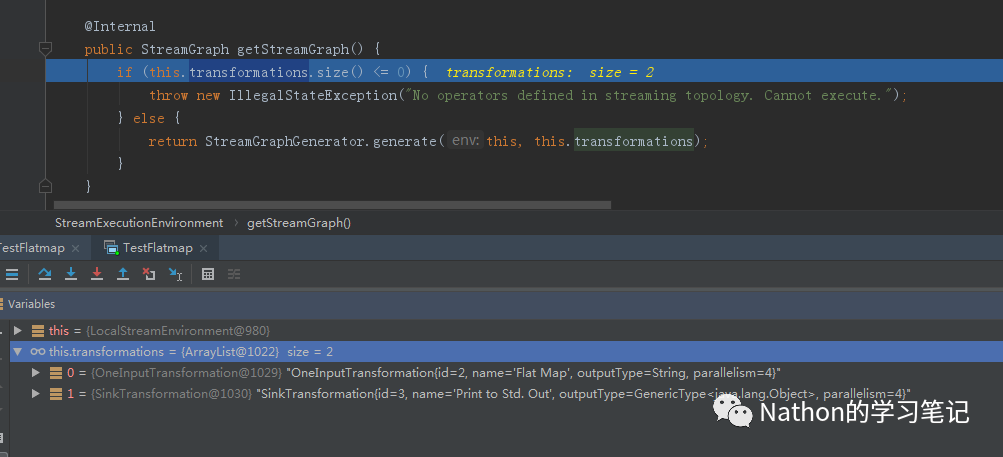
从追踪结果来看,Flink将这个应用分为了2个transformations,1个就是flatmap,对应的算子operator为StreamFlatMap,另外一个是结果的输出对应的operator为StreamSink,也就是打印.
同时,transformations在这里是一个数组Arraylist:
包含了transformation的id,name,outputType(输出格式),并行度.
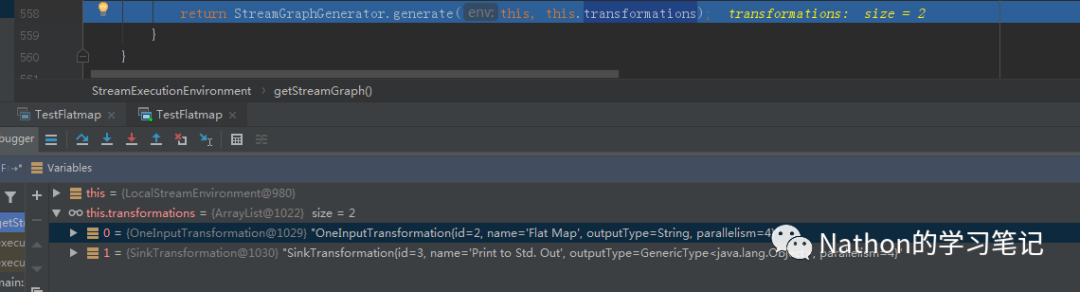
从这里分析可以看出,Flink是把每个算子都transform为一个对流的转换,最生成streamGraph,也就是说streamGraph代表程序的拓扑结构,是从用户代码直接生成的图,从source到各种map,flatmap等再到sink操作全部被映射成了StreamTransformation.比如,这里应用就被flink映射为OneInputTransformation和SinkTransformation.
从源码里面看,封装了如下的StreamTransformation:
接下来,有了streamGraph后,会继续生成jobGraph,这个图是要交给flink去生成task的图.
那么,flink的应用提交后,从开始的streamGraph->jobGraph->ExecutionGraph的差异在哪呢.
从追踪源码可以看出:
1.streamGraph是对用户应用程序逻辑的映射,映射为对应流的图;
2.jobGraph基于streamGraph进一步做了优化,比如把部分的操作串成chain提高效率;
3.ExecutionGraph已经可以用于调度任务.
