




页级压缩
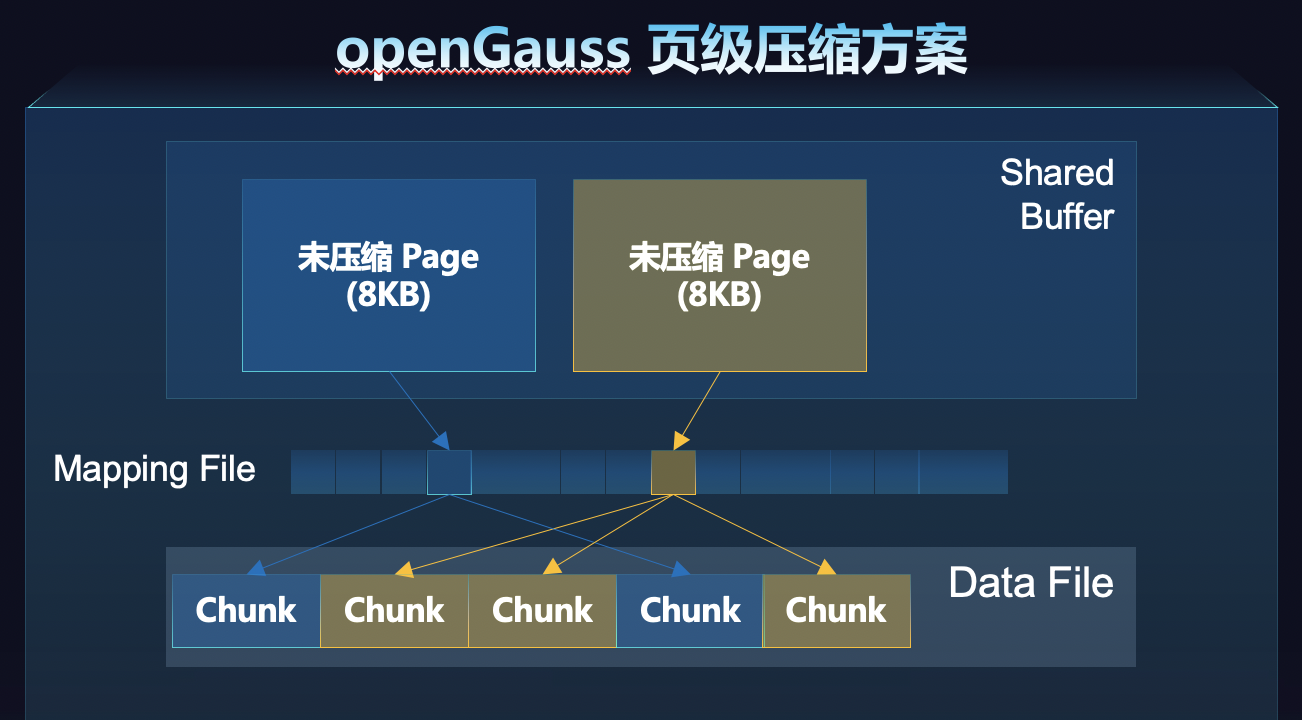
opengauss数据库是以数据页面(Page)为单位进行压缩解压,本特性自openGauss 3.0.0版本开始引入,通过对数据页的透明页压缩和维护页面存储位置的方式,做到高压缩、高性能。提高数据库对磁盘的利用率。
页级压缩方案
数据页面在写入到磁盘前进行压缩,内存中数据为未压缩的状态。数据页面压缩后,拆分为多个定长(1K/2K/4K)的Chunk存储,压缩算法支持lz4和zstd。
行级压缩
本特性自MogDB 3.1.0版本开始引入。
在数据写入aStore行存表时,后台对数据进行压缩,典型场景下可以获得50%的存储空间节省,同时通过后台流控技术减少对系统资源的占用,性能几乎无损。
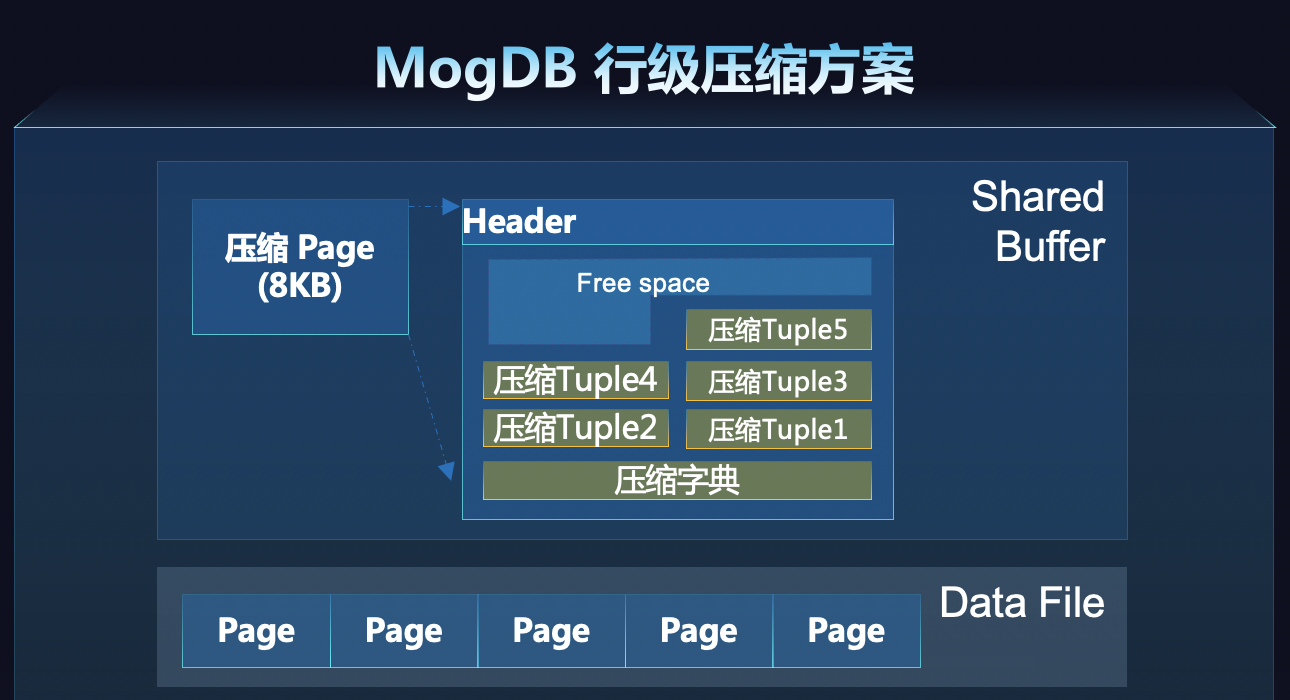
行级压缩方案
MogDB以数据行(Tuple)为单位进行压缩解压,以页面为单位训练字典。数据页面在写入内存页面时,准实时完成压缩,内存中为压缩状态,自研轻量级压缩算法。以记录行为单位进行压缩解压,对于OLTP点查场景,只需要解压一行数据,没有解压放大,能够获得更好的查询性能;
内存中的页面为压缩状态,在相同Shared Buffer大小下可以提供更高的内存命中率,进而提升查询性能;
在MVCC(多版本并发控制)查找历史版本链时,无需解压中间版本,只需要解压目标版本的数据行。这样可以大大减少解压的工作量,提高查询性能;
采用多数据页共享字典的方案,相比单表训练字典的方案,压缩字典可以随数据的变更自动演进,没有字典逐渐失效的问题。
优点
- OLTP点查场景,只需要解压一行数据,没有解压放大;
- 延迟解压,MVCC查找历史版本链时无需解压,只需要解压目标版本;
- 内存中页面为压缩状态,相同Shared Buffer容量下,内存命中率更高;
- 页内压缩,无page颗粒压缩的对齐空洞和磁盘碎片问题;
- 多个页面一起训练并共享压缩字典,减少字典空间占用;
- 专用字典解码器缓存,解压时无需频繁构建解码器,提升解码性能。
行级压缩支持的功能
Astore行级压缩支持如下功能:
- 创建和修改压缩表;
- 在对压缩表进行读写操作时自动完成压缩或解压操作;
- 支持压缩表主备同步;
- 支持压缩表过期版本回收;
- 当数据导入到压缩表时支持自动完成压缩;
- 支持通过GS_COMPRESSION视图展示系统所有压缩表的压缩情况;
- 兼容一级分区表,包括移动、迁移、合并、更新,分裂,添加,删除,截断分区等所有功能;兼容二级分区表,二级子分区的相关操作包括新增、删除、分裂、截断分区;
- 支持在段页式模式下创建压缩表,且段页式压缩表增删改查等特性能正常执行;
- 压缩表兼容MogDB已经发布的工具;
- 在autovacuum线程中加入compress page流程,减少磁盘IO次数,加锁次数,从而降低后台压缩开销;同时,Astore行级压缩优化了相关压缩算法;表的压缩效果对用户透明。
行级压缩约束
- 仅对Astore行存表生效,不能用于Ustore行存表、列存表和MOT;
- 默认创建非压缩表;
- 不能为系统表指定压缩属性;
- 不能为外表指定压缩属性;
- 不支持tablespace压缩属性;
- 分区压缩表,单个分区数据量大于128MB才会执行压缩;
- 普通vacuum命令,不会执行压缩,vacuum full命令会执行压缩;
- 后台压缩节省出来的空间不会立即反应到磁盘的空间占用,后续的数据插入会重复使用压缩节省出来的空间;
- 不支持3.0版本的段页式压缩表升级到5.0版本。如果3.0版本中有段页式压缩表,升级前请将段页式压缩表中的数据导入非压缩表进行备份,然后将段页式压缩表删除,升级完成后重新创建段页式压缩表,并将备份的数据导入新创建的段页式压缩表;
实战
1、创建压缩表和非压缩表。
MogDB=# CREATE TABLE tb_mogdb_compress (id INT, name TEXT, addr TEXT, info TEXT) WITH (compression = yes);
CREATE TABLE
MogDB=# CREATE TABLE tb_mogdb_no_compress (id INT, name TEXT, addr TEXT, info TEXT);
CREATE TABLE
复制2、插入随机数据。
MogDB=# INSERT INTO tb_mogdb_compress VALUES (generate_series(0, 1999999), 'fasdfasdhigasidfdfhgioashdfgohaosdgh', 'fasdfasdfasdahasdhsfsdgstyjdth', 'fasdhgsoidfhisdifgiosdfiogio');
INSERT 0 2000000
MogDB=# INSERT INTO tb_mogdb_no_compress VALUES (generate_series(0, 1999999), 'fasdfasdhigasidfdfhgioashdfgohaosdgh', 'fasdfasdfasdahasdhsfsdgstyjdth', 'fasdhgsoidfhisdifgiosdfiogio');
INSERT 0 2000000
复制3、执行vacuum full可以立即触发压缩指令。
MogDB=# vacuum full tb_mogdb_compress;
复制4、查看压缩表和非压缩表所占大小。
MogDB=# \d+
List of relations
Schema | Name | Type | Owner | Size | Storage | Description
--------+----------------------+-------+--------+--------+-----------------------------------+-------------
public | tb_mogdb_compress | table | yaojun | 105 MB | {orientation=row,compression=yes} |
public | tb_mogdb_no_compress | table | yaojun | 256 MB | {orientation=row,compression=no} |
(2 rows)
复制可以看出节约了50%以上的存储空间节省,MogDB的行级压缩更省CPU,性能更好,适用于金融高负载场景。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
