




Akka的功能是分布式环境下的高并发与高可用,spark底层的设计与实现也是基于Akka的方式。首先看看Akka的基本架构,画个图,如下图所示:
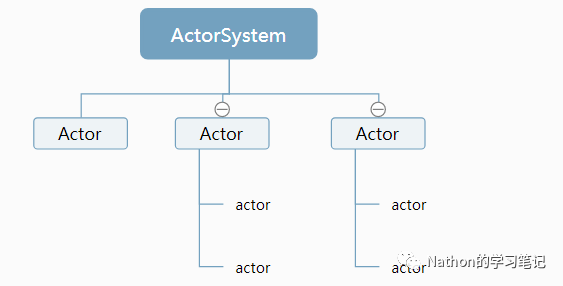
ActorSystem负责创建并监听下面的Actor,就好比一个公司里面,ActorSystem作为老板管理下面的各个部门(Actor),而各个部分Actor再负责具体任务的下发。
然而,再整个集群中,一个ActorSystem还需要跟其他的ActorSystem进行通信。那么,通过scala来实现模拟这个过程,如下:
master节点启动后便启动一个定时器,定时检测集群中超时的worker,并将超时的worker从集群中移除;
worker节点启动后向master节点进行注册(包括运行所需的内存,cpu资源等);
master收到worker注册的消息后将其持久化保存起来;
master向worker发送注册成功的消息
worker接收到注册成功消息后,启动定时器,定时向master汇总自己的心跳,确保自己的存活;
master接收到worker的汇报心跳信息后,更新worker最近一次的汇报时间。
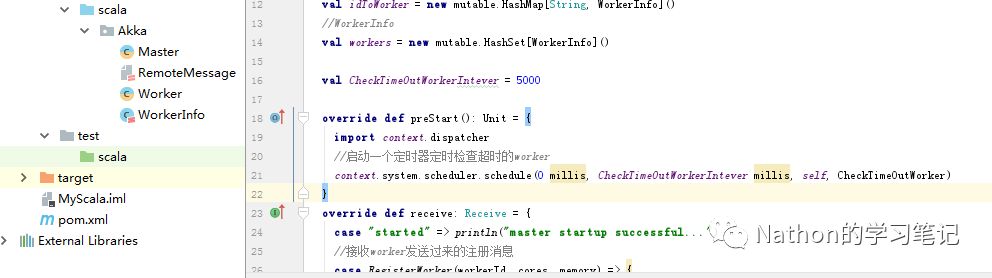
在idea中建立scala项目来实现上面的流程,这里建立了一个master类,一个worker类,remotemessage类作为消息通信的序列化,workinfo类用来封装启动的配置信息。
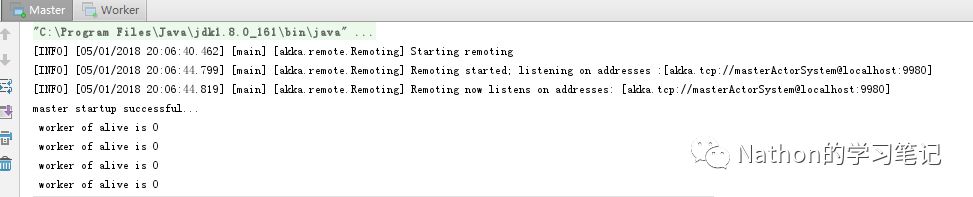
当启动master节点后,会一直监听是否有存活的worker节点,这时我再启动一个worker节点,可以看到master可以监听到有一个存活的worker节点。

文章转载自Nathan的笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
