





对于一定规模的系统而言,数据仓库往往需要访问外部数据来完成分析和计算。外部数据包装器(Foreign Data Wrapper, 简称 FDW)是 PostgreSQL 提供的访问外部数据源机制。用户可以使用简单的SQL语句访问和操作外部数据源,就像操作本地表一样。
在上次直播中,我们深入探讨了PostgreSQL FDW的基本概念、详细使用方法、实现原理以及源码实现。以下是根据直播内容整理成稿。
01
FDW使用详解
FDW是PostgreSQL中的一项关键特性,它赋予用户直接通过SQL语句访问存储于外部数据源的能力。FDW遵循SQL/MED标准设计,使PostgreSQL能够无缝对接多种异构数据库系统以及非数据库类数据源。
FDW 可以用于以下场景:
1. 跨数据库查询:在PostgreSQL数据库中,我们可以通过FDW直接请求和查询其他 PostgreSQL 实例,或是其他数据库如 MySQL、Oracle、DB2、SQL Server 等。
2. 数据整合:当我们需要从不同数据源整合数据时,例如REST API、文件系统、NoSQL数据库以及流式系统等,FDW能够帮助我们轻松实现这种跨来源的数据整合。
3. 数据迁移:利用FDW,我们可以高效地将数据从旧系统迁移到新的PostgreSQL数据库中。
4. 实时数据访问:通过FDW,我们能够访问外部实时更新的数据源。
PostgreSQL支持非常多常见的FDW,能够直接访问多种类型的外部数据源。例如,可以连接并查询远程的PostgreSQL,或者主流的SQL数据库如Oracle、MySQL、DB2以及SQL Server。同时,PostgreSQL FDW也具备灵活的接口,支持用户自定义外部访问方式。
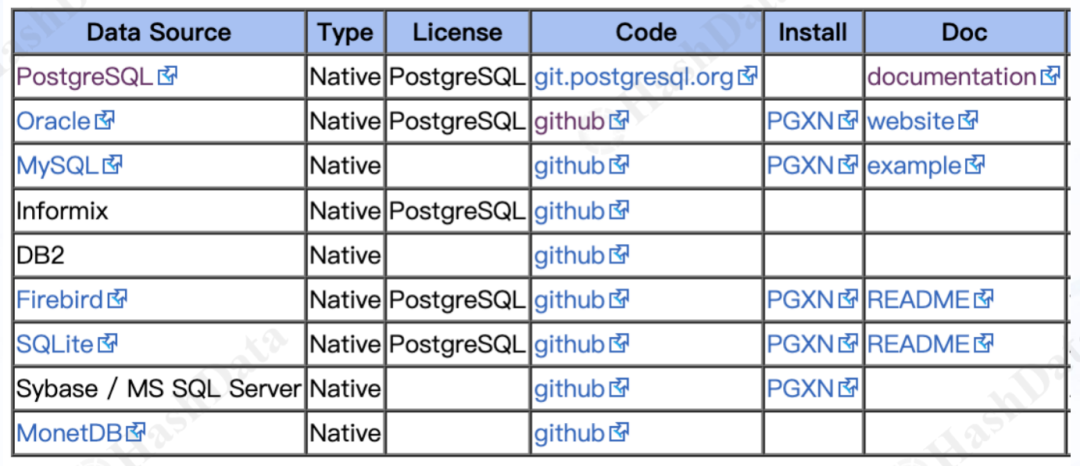
表1.常见的FDW—SQL Database
此外,对于NoSQL数据库,如HBase、Cassandra、ClickHouse,以及实时数据库如InfluxDB、消息队列如Kafka、文档型数据库如MongoDB等等都能通过FDW实现数据访问。
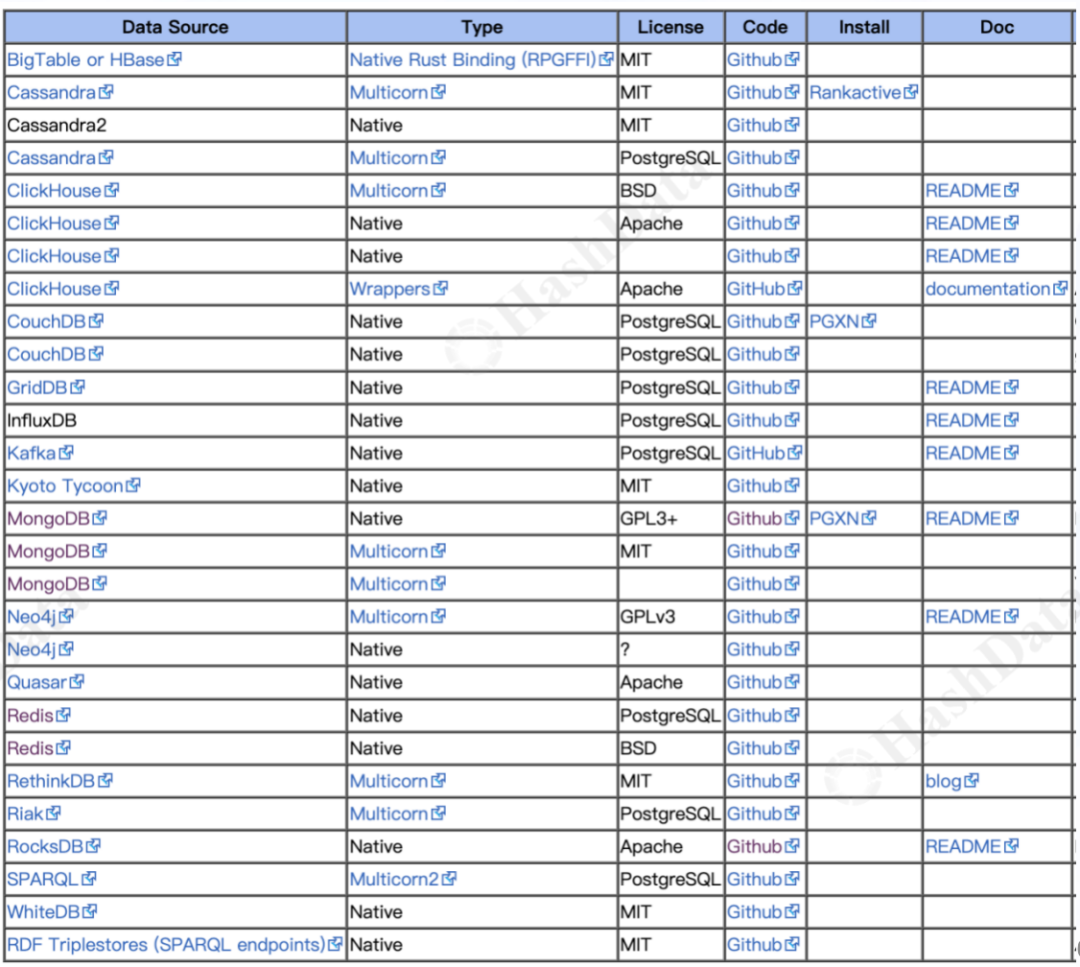
表2.常见的FDW—NoSQL Database
常见的文本格式数据,如CSV、JSON、Parquet和XML,也可以通过FDW轻松访问。大数据组件如Elasticsearch、BigQuery,以及Hadoop生态系统中的HDFS和Hive等等都可以通过FDW实现无缝集成。
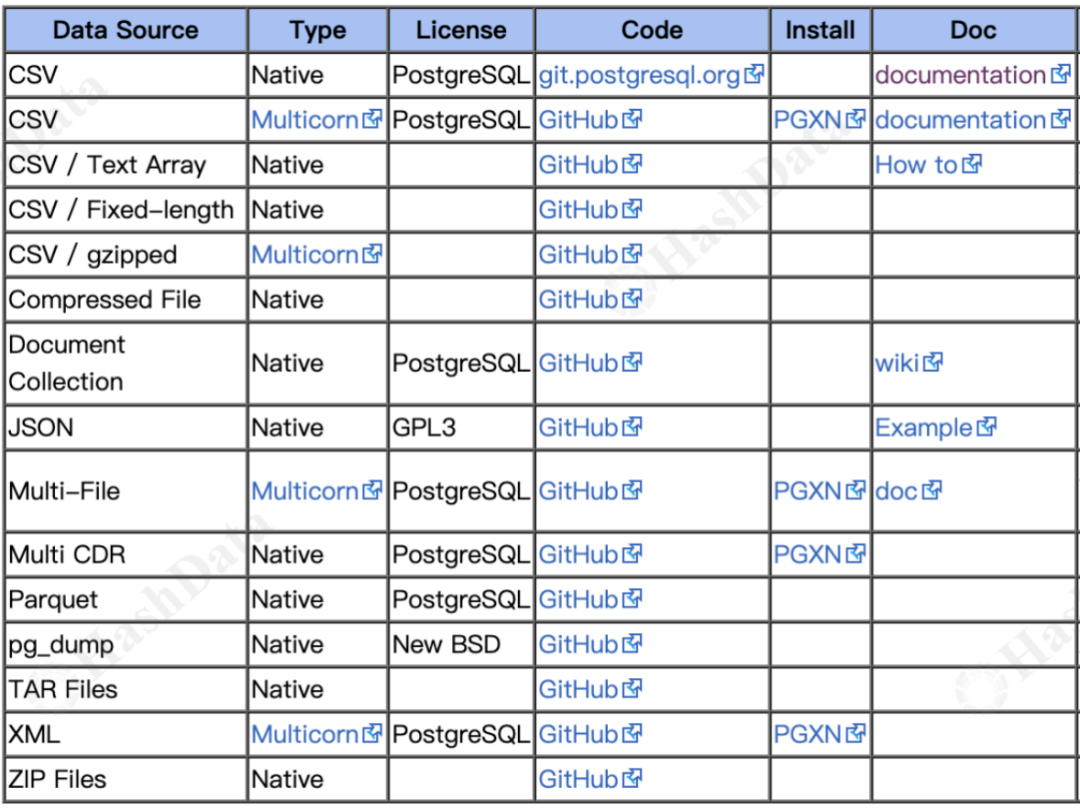
表3.常见的 FDW—File Wrapper
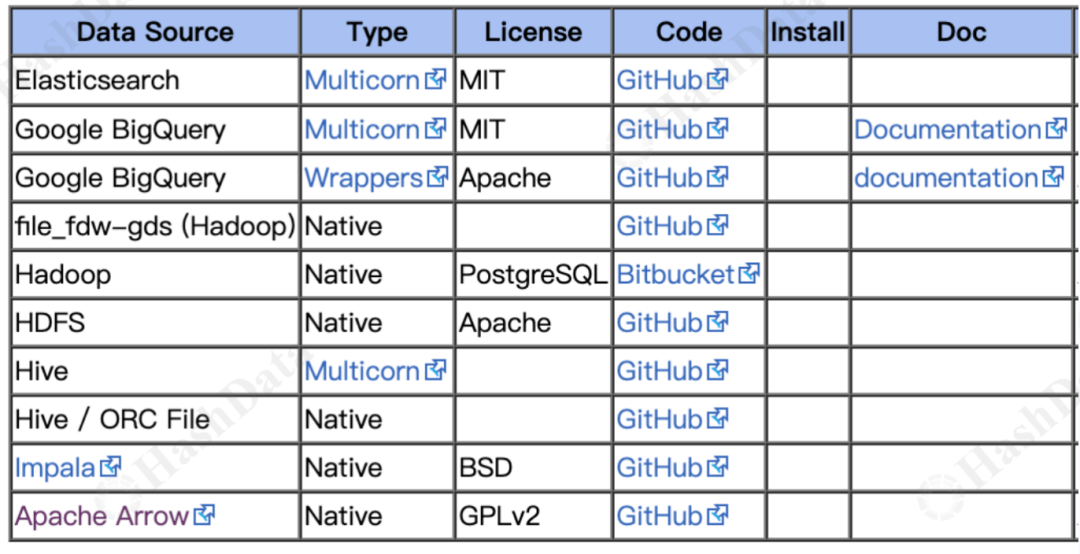
表4.常见的 FDW—Big Data
FDW机制由四个核心组件构成:
1. Foreign Data Wrapper:特定于各数据源的库,定义了如何建立与外部数据源的连接、执行查询及处理其他操作。例如,postgres_fdw用于连接其他PostgreSQL服务器,mysql_fdw则专门连接MySQL数据库。
2. Foreign Server:在本地PostgreSQL中定义一个外部服务器对象,对应实际的远程或非本地数据存储实例。
3. User Mapping:为每个外部服务器设置用户映射,明确哪些本地用户有权访问,并提供相应的认证信息,如用户名和密码。
4. Foreign Table:在本地数据库创建表结构,作为外部数据源中表的映射。对这些外部表发起的SQL查询将被转换并传递给相应的FDW,在外部数据源上执行。
接下来,我们以常见的postgres_fdw为例,来简要探讨一下FDW的基本使用方法。
步骤一:创建插件
test=create extension postgres_fdw;CREATE EXTENSION
步骤二:创建 Foreign Server
CREATE SERVER foreign_serverFOREIGN DATA WRAPPER postgres_fdwOPTIONS (host '127.0.0.1', port '8001', dbname 'postgres');
步骤三:创建 User Mapping
CREATE USER MAPPING FOR gpadmin SERVER foreign_server;
步骤四:创建外部表
CREATE FOREIGN TABLE foreign_table (val int)SERVER foreign_serverOPTIONS (schema_name 'public', table_name 't2');
02
FDW实现原理
在PostgreSQL的内核代码中,FDW访问外部数据源的操作接口主要通过FdwRoutine这一结构体进行定义。任何接入外部数据源的插件都可以根据自身需要去实现这些接口。
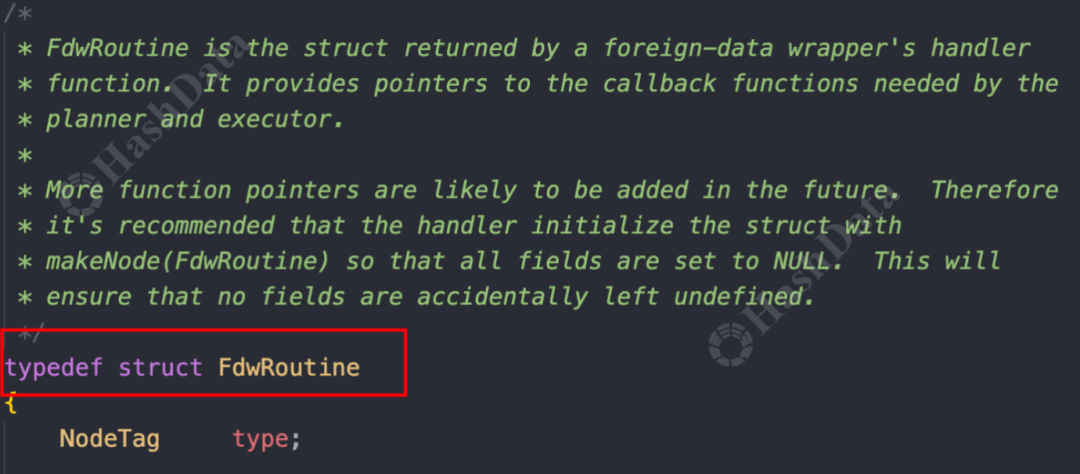
图1.FdwRoutine 定义了外部数据操作的接口
接口函数大致分为多个类别,包括但不限于扫描、修改、分析外部表等等。例如,扫描外部表相关接口定义了如何扫描外部表,常见的操作包括开始扫描( BeginForeignScan,主要进行准备工作)、执行扫描(IterateForeign Scan,从扫描中获取数据)、重新扫描(RescanForeignScan)以及结束扫描(EndForeignScan)等。
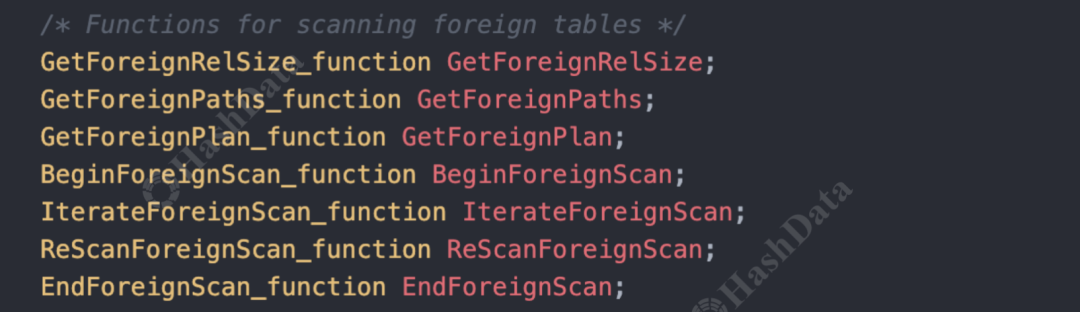
图2.扫描外部表相关接口
此外,还有用于修改数据的外部表接口,支持对数据进行insert、delete、update等操作,以及explain和analyze等外部表接口。
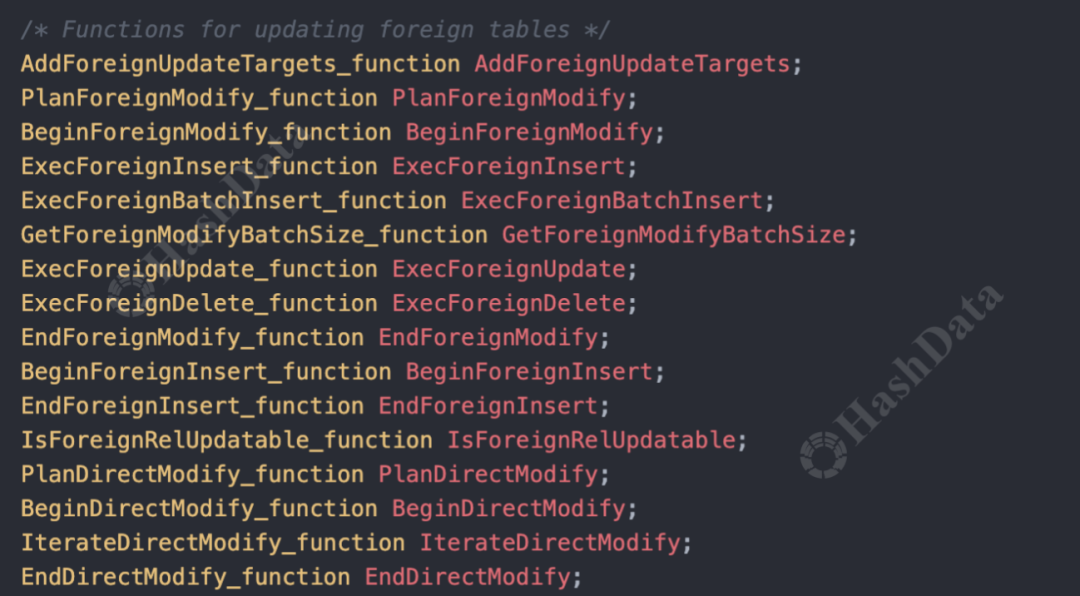
图3.insert/delete/update外部表接口
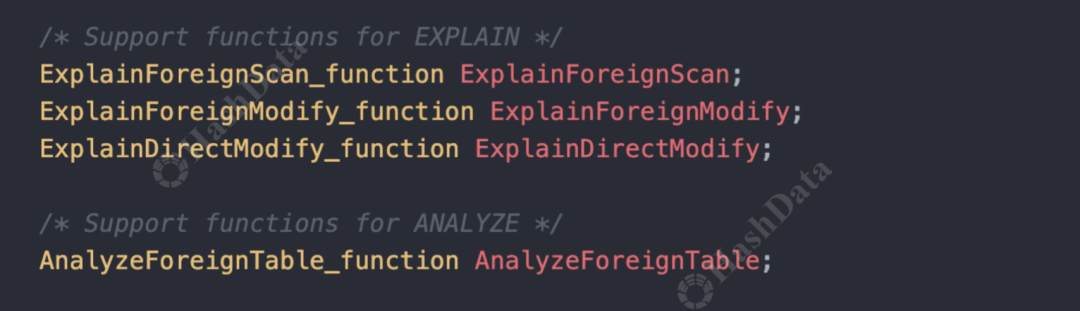
图4.explain/analyze 外部表接口
注:需要明确的是,当实现一个访问外部数据源的FDW时,并不需要实现以上提到所有的外部访问数据接口。开发者只需根据实际需求实现对应的接口即可。例如,如果只访问查询某个Web数据源而不进行修改或删除操作,那么就不需要实现关于删改和更新的操作接口,只需实现SCAN扫描相关的接口即可。
如下图,这是一个FDW插件实现FdwRoutine的示例,这里仅实现了一些基础的扫描操作接口(如BeginForeignScan、IterateForeignScan等),以及用于性能分析的AnalyzeForeignTable接口。
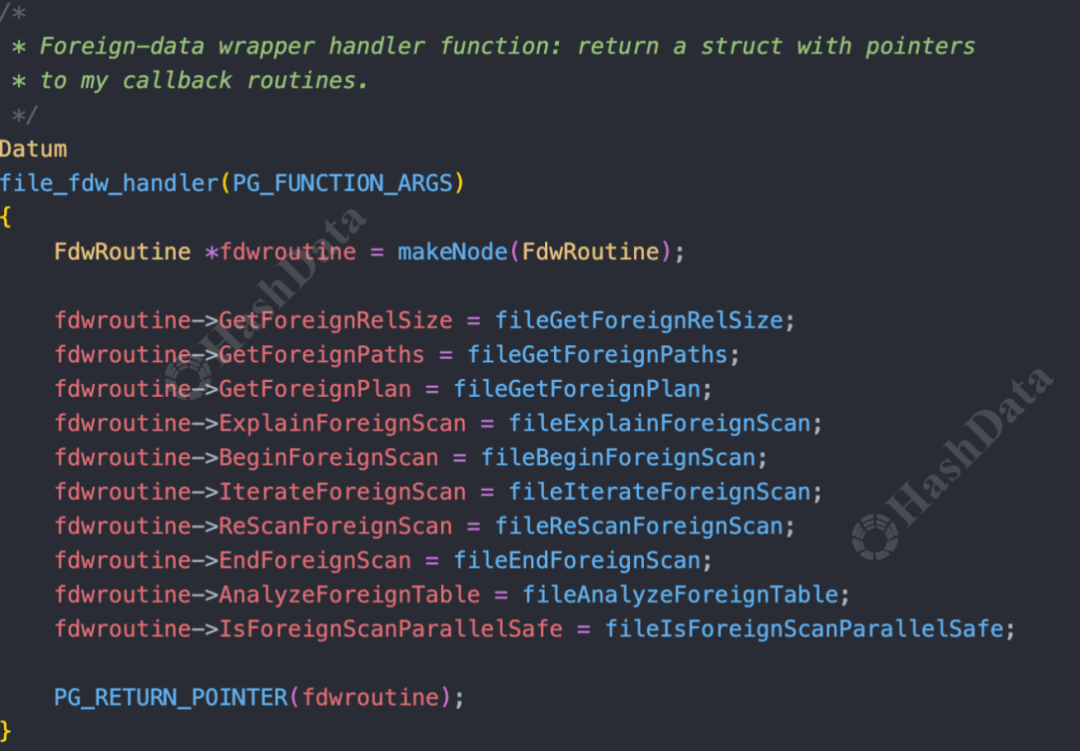
图5.插件实现 FdwRoutine
在PostgreSQL的执行过程中,这些接口函数会在planner或executor阶段被调用。尤其是当executor需要依赖外部服务插件访问数据时,它会通过插件提供的数据访问接口来获取数据。这使得FDW能够与PostgreSQL的Parser、Planner 以及Rewriter等组件能够无缝协作。
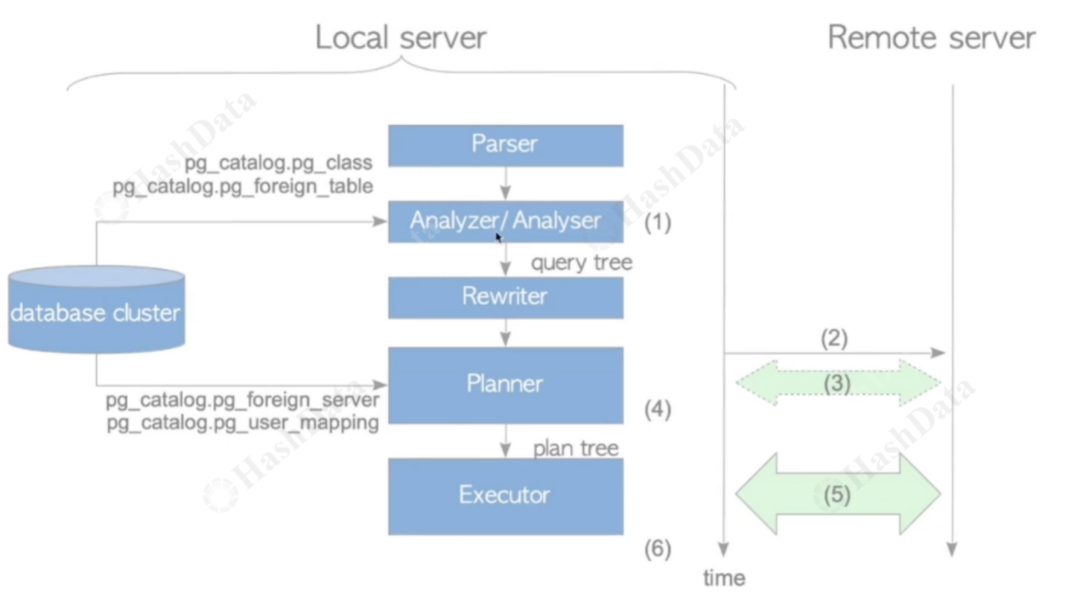
图6.接口调用与访问协作流程
在需要访问外部数据源时,我们只需定义好相应的数据访问接口,就能直接获取数据,并按照PostgreSQL的标准流程进行后续处理。在执行过程中,执行器会分解为几个阶段进行:
1.首先进入 init 阶段,核心任务是执行外部表扫描ExecInitForeignScan。在这个阶段,主要是定义了一些外部扫描的接口,并调用FdwRoutine中用户自定义的接口,从而进行扫描前的准备。
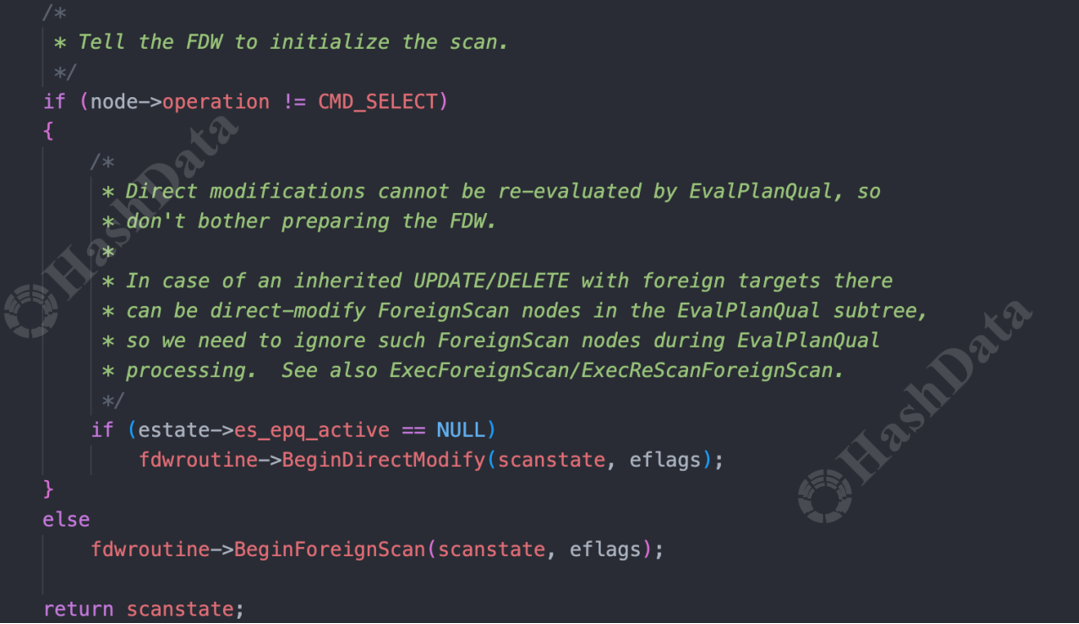
图7.执行 scan 前的准备
2.紧接着是执行查询阶段,此时会调用ExecuteForeignScan方法。在这个方法中,我们主要需指定ForeignNext来获取下一条数据,并定义ForeignRecheck 来检验数据元组的可见性。
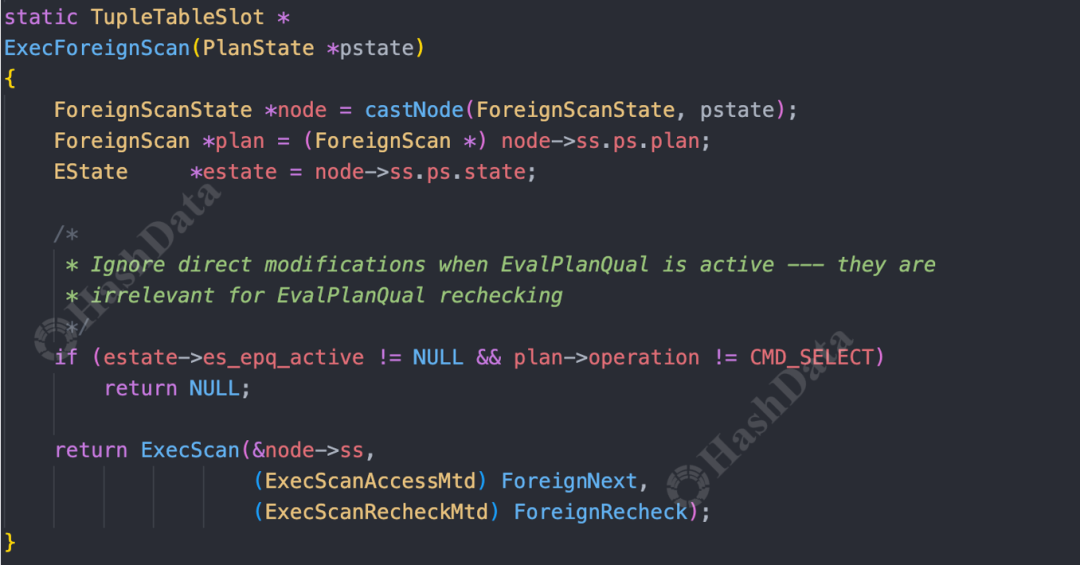
图8.执行查询阶段
3.最后进入结束查询阶段,即执行EndForeignScan,该阶段主要负责资源清理工作。若系统检测到存在 FDWRoutine,就会利用用户自定义的 EndForeignScan 函数来释放资源。
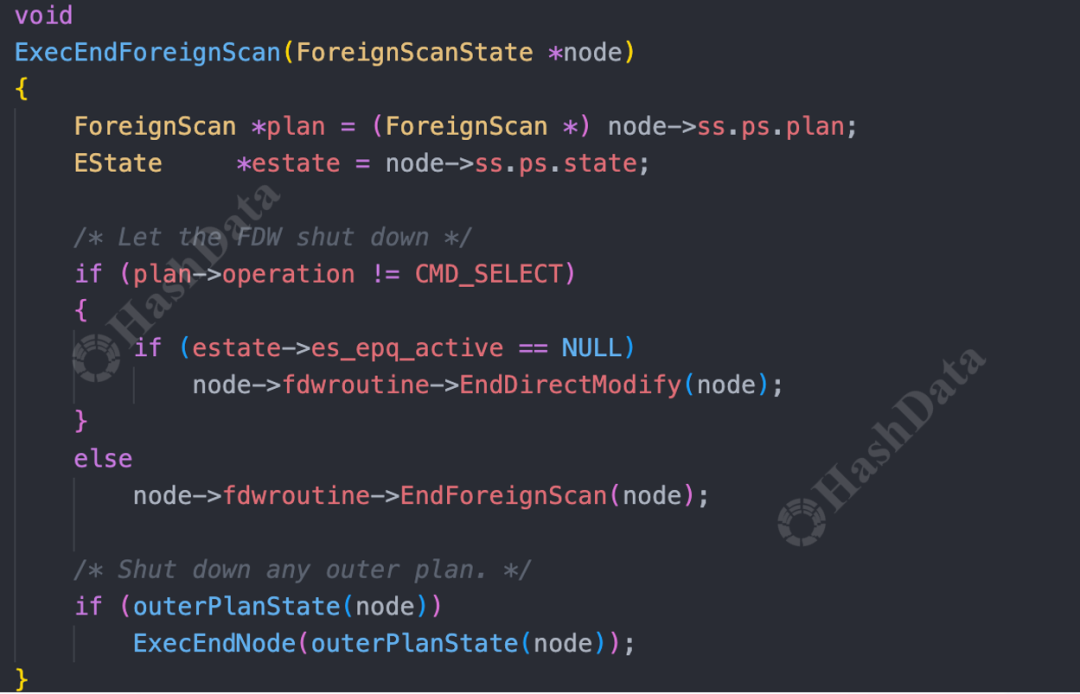
图9.结束查询阶段
以上就是FDW整体的实现流程。接下来,为了更深入地了解FDW的工作机制,我们将深入探讨FDW的源码。
03
FDW源码解析
FDW支持的数据类型众多,但在此我们以常见的Postgres_fdw为例,剖析其源码实现,同样可帮助理解其他FDW的源码逻辑。
FdwRoutine定义
首先,我们需要定义FdwRoutine。前文提到了FdwRoutine主要负责定义外部数据扫描的接口,接口需要自定义实现外部扫描的方法。
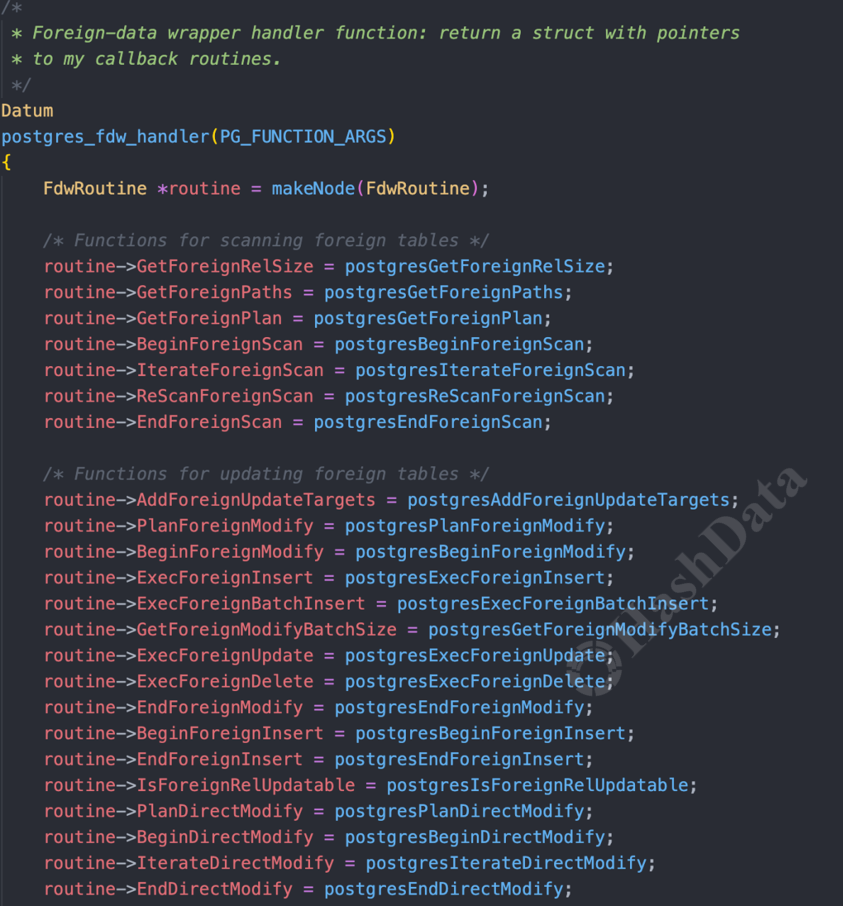
图10.FdwRoutine 定义
访问外部数据源
定义好FdwRoutine之后,开始访问并扫描外部数据源。在Postgres_fdw中,流程也就是进入BeginForeignScan阶段。这一阶段主要是获取我们先前定义的外部表实例和用户信息,然后初始化并获取一个连接到远端数据源。
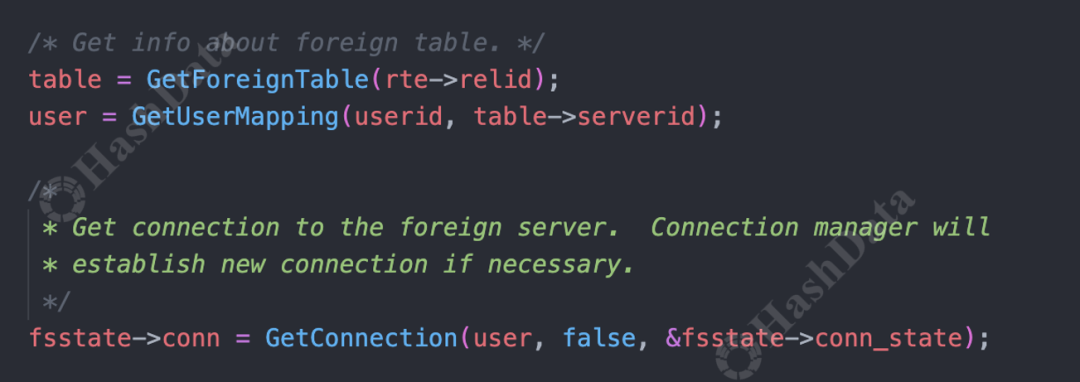
图11.postgresBeginForeignScan
执行查询阶段
获取连接后,执行查询,即进行IterateForeignScan阶段。这个过程的逻辑是创建一个游标迭代器(cursor),并从cursor中持续获取数据。
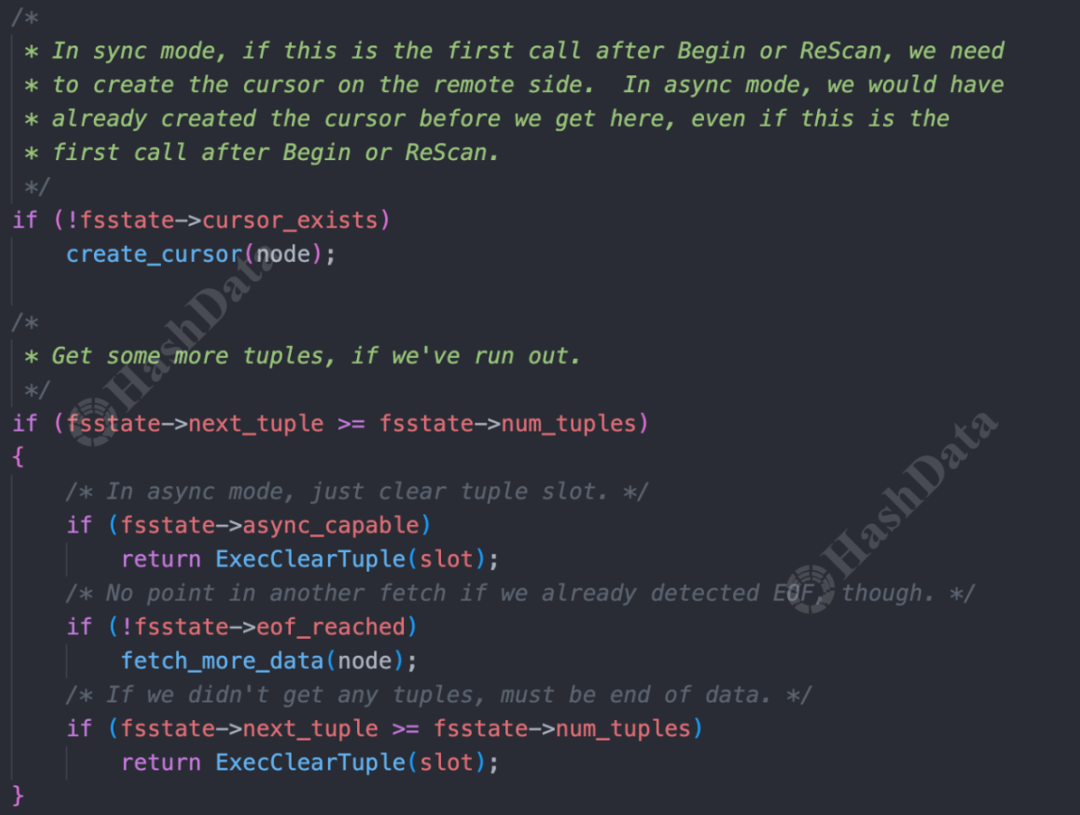
图12.postgresIterateForeignScan
当全部数据迭代或扫描完成后,我们会释放连接并关闭cursor等资源,通过自定义的EndForeignScan阶段完成。
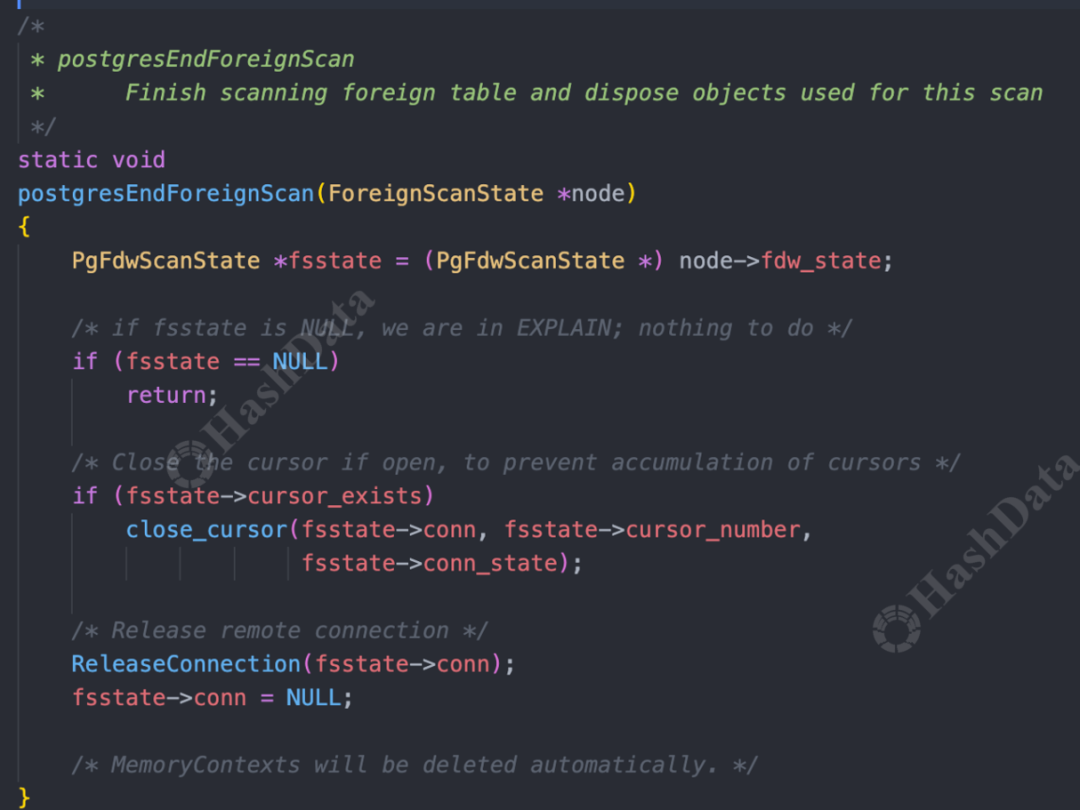
图13.postgresEndForeignScan
insert操作
对于insert操作,例如,在本地PostgreSQL数据库中修改Web数据源,增加一条数据,需要访问插入Web数据的接口。此操作先进入BeginForeignInsert阶段,任务是构造SQL语句,通过预处理语句进行初始化,做好插入准备。
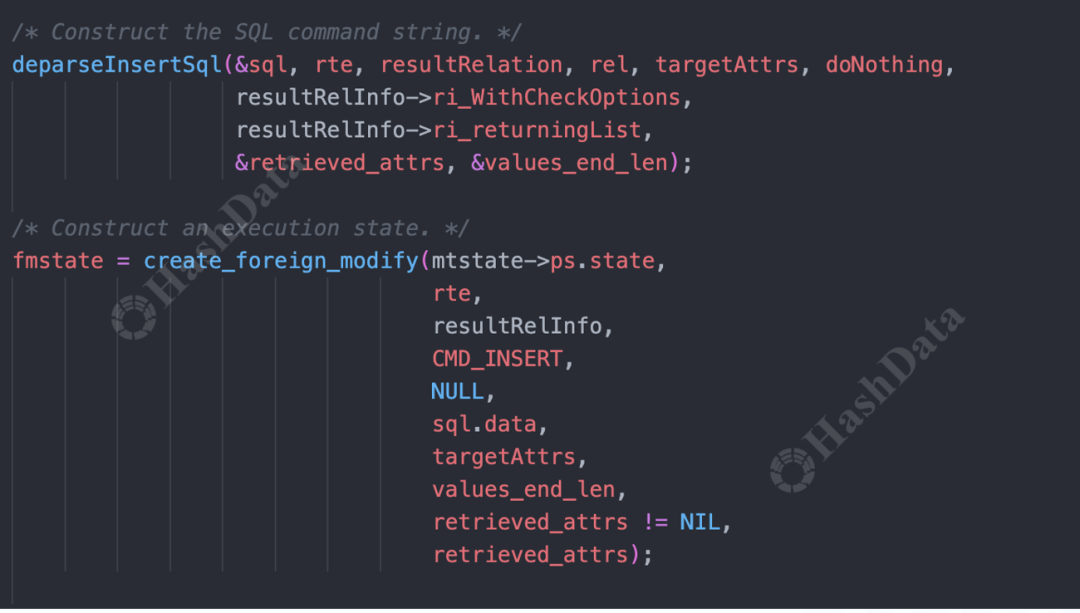
图14.postgresBeginForeignInsert
之后,进入ExecuteForeignInsert阶段,执行数据插入,主要通过预处理语句传递参数,然后发送SQL到远端执行。
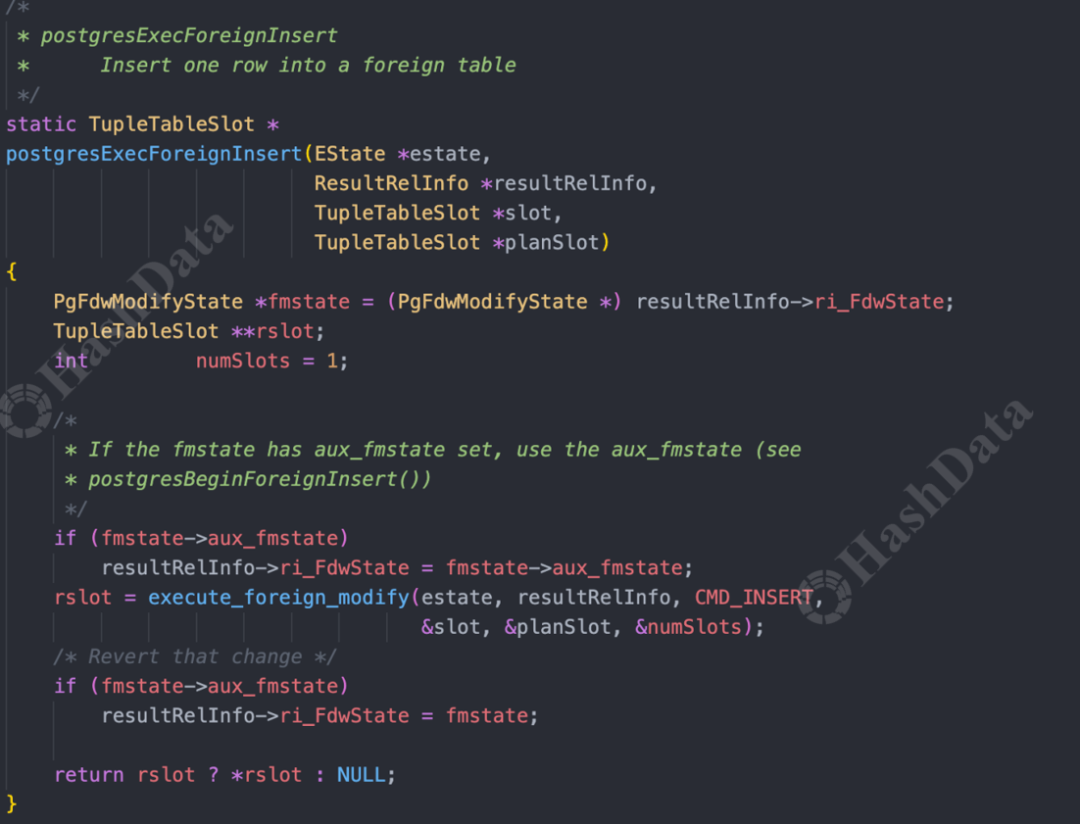
图15.postgresExecForeignInsert
最后,EndForeignInsert阶段负责收尾和资源清理。
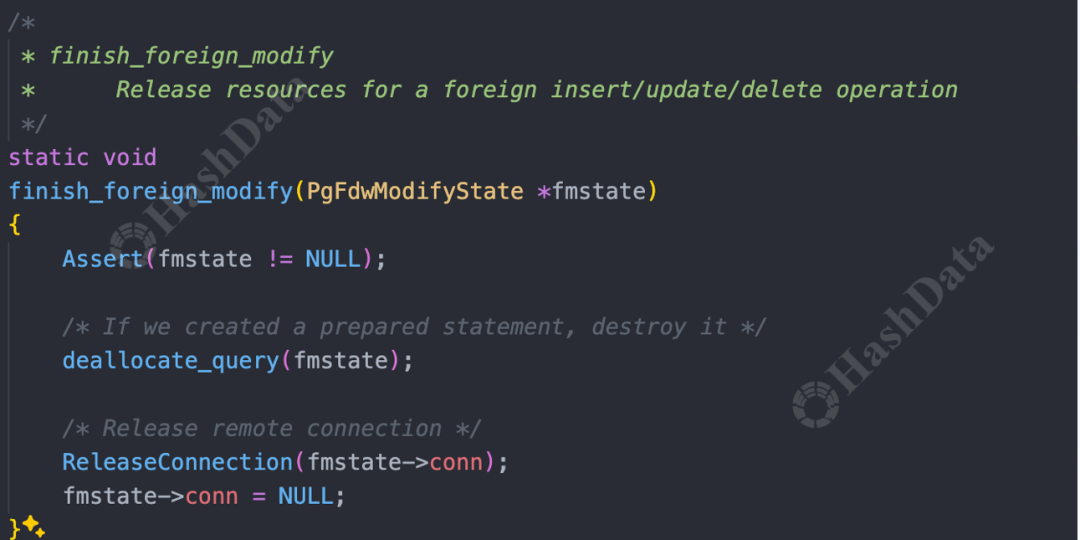
图16.postgresEndForeignInsert
更新/删除操作
更新和删除操作的逻辑与插入类似。首先进入BeginDirectModify阶段,进行数据修改前的准备,如构建查询语句、获取连接等。随后执行修改操作,主要通过发送参数和查询到远端来执行。
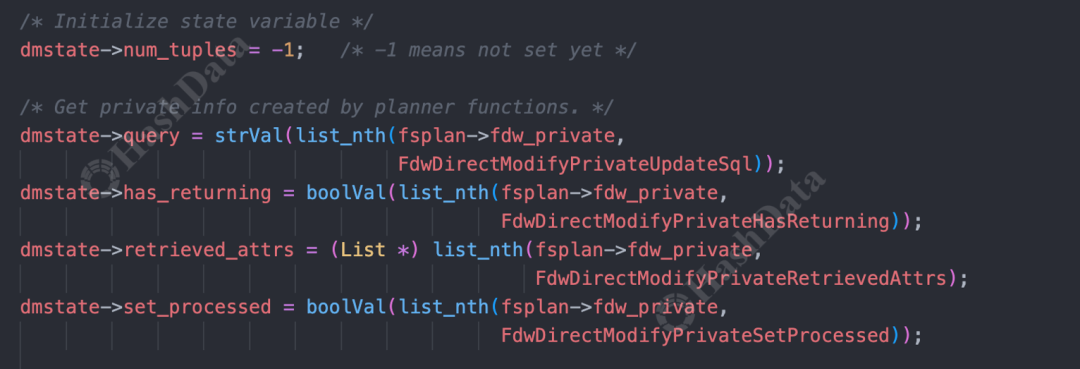
图17.postgresBeginDirectModify
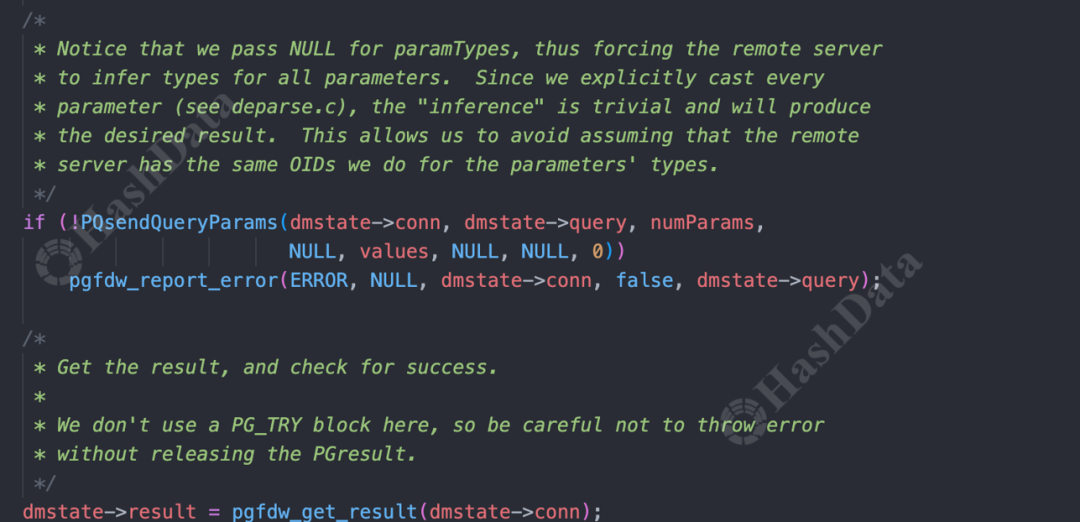
图18.postgresIterateDirectModify
为了更直观地理解这些操作,我们将通过演示具体示例和调试方式来跟踪整个执行链路,从而更深入地理解其工作原理。
本次分享,我们为大家讲解了FDW基本概念、使用场景、实现原理,以及源码解析,文章篇幅有限,更多技术细节讲解欢迎大家点击文末左下角【阅读原文】链接,观看视频回放,希望能与朋友们一起更好地理解和用好FDW。

扫码加入技术交流群











