




一、什么是并行查询?
PostgreSQL利用多 CPU 让查询更快的查询计划,这种特性被称为并行查询。并行查询是PostgreSQL的一项强大功能,能够显著提升查询性能。很多查询使用并行查询时比之前快了超过两倍,有些查询是以前的四倍甚至更多的倍数。那些访问大量数据但只返回其中少数行给用户的查询最能从并行查询中获益。
二、并行查询如何工作
优化器判断某一个特定的查询,并行查询是最快的执行策略时,将创建一个查询计划。
该计划包括一个Gather或Gather Merge节点。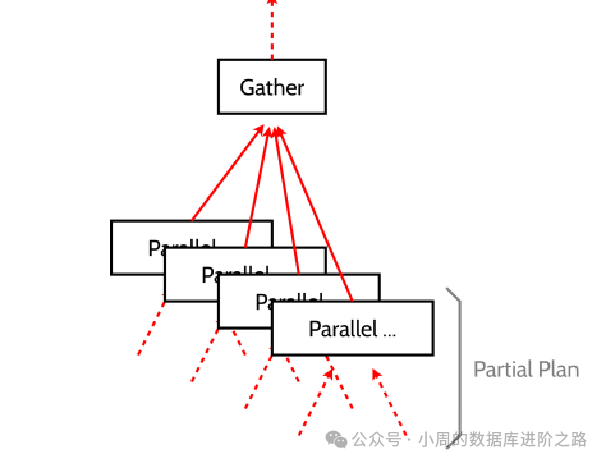
每个后台工作进程都会执行并行查询的并行部分。领导者不仅执行该部分,还负责读取工作进程生成的元组。
当并行部分生成少量元组时,领导者像额外的工作进程一样加快查询速度。
相反,当生成大量元组时,领导者主要忙于读取元组和执行Gather或Gather Merge节点以上的处理步骤,很少执行并行部分。
三、并行查询工作进程数量
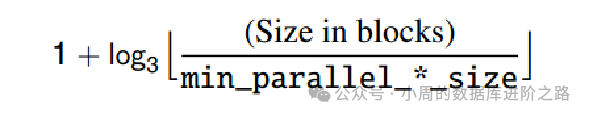
四、并行查询使用先决条件
在确定使用并行技术之前,要确定软硬件的一些先决条件:
任务task必要条件
备选进行并行操作的任务task必须是一个大任务作业,比如,长时间的查询。
任务时间通常可以以分钟、小时进行计数,这样的任务,才值得冒险使用并行操作方案;
资源闲置条件
只有在数据库服务器资源存在闲置的时候,才可以考虑进行并行处理。
如果经常性的繁忙,贸然使用并行只能加剧资源的争用。
五、使用并行查询
1. 启用并行查询
确保配置文件 postgresql.conf 中的相关参数已启用:
# 最大并行工作者数(全局)
max_parallel_workers = 8
# 每个并行查询的最大工作者数
max_parallel_workers_per_gather = 4
重启数据库以应用更改:
sudo systemctl restart postgresql
2. 配置表和查询
确保表统计信息足够详细,以便优化器能正确评估并行查询的收益:
ANALYZE your_table;
3. 控制并行度
通过设置 parallel_setup_cost
和 parallel_tuple_cost
来调整并行查询的成本估算:
SET parallel_setup_cost = 1000;
SET parallel_tuple_cost = 0.1;
4. 使用并行查询
编写支持并行处理的查询,例如:
SELECT COUNT(*)
FROM your_table
WHERE some_column > some_value;
5. 检查并行执行计划
使用 EXPLAIN
命令查看查询的执行计划,确认是否使用并行查询:
EXPLAIN (ANALYZE, VERBOSE)
SELECT COUNT(*)
FROM your_table
WHERE some_column > some_value;
6. 调优并行查询
根据查询性能,调整以下参数:
min_parallel_table_scan_sizemin_parallel_index_scan_size
例如:
SET min_parallel_table_scan_size = '8MB';
SET min_parallel_index_scan_size = '512kB';
7. 监控并行查询
使用系统视图 pgstat_activity 和 pg_stat_progress* 监控并行查询的执行情况:
SELECT * FROM pg_stat_activity WHERE backend_type = 'parallel worker';
文中的概念来源于网络,如有侵权,请联系我删除。
欢迎关注公众号:小周的数据库进阶之路,一起交流数据库、中间件和云计算等技术。欢迎觉得读完本文有收获,可以转发给其他朋友,大家一起学习进步!感兴趣的朋友可以加我微信,拉您进群与业界的大佬们一起交流学习。
