




PostgreSQL17索引优化之支持并行创建BRIN索引
最近连续写了几篇关于PostgreSQL17优化器改进的文章,其实感觉还是挺有压力的。对于原理性的知识点,一方面是对这些新功能也不熟悉,为了尽可能对于知识点表述或总结做到准确,因此需要去阅读官网的讨论邮件及源码;另外对于知识点,如何快速的把自己写文章的本意,很清晰的表达清楚,也在不断调整写作方式。希望不会对大家的阅读造成困扰,也希望大家有所收获。
关于PostgreSQL17索引优化之支持并行创建BRIN索引这个主题,相对来说更倾向于实操类型的,对于底层具体是如何实现的,其实对于大部分人来说应该是不太关注。下面我们直接进入正题,直接实操验证该功能。
创建测试用例表并插入数据
CREATE TABLE brin_parallel_test (a int, b text, c bigint) WITH (fillfactor=40); --生成的数据中需要有null或非null的值 INSERT INTO brin_parallel_test SELECT (CASE WHEN (mod(i,231) = 0) THEN NULL ELSE i END), (CASE WHEN (mod(i,233) = 0) THEN NULL ELSE md5(i::text) END), (CASE WHEN (mod(i,233) = 0) THEN NULL ELSE (i/100) + mod(i,8) END) FROM generate_series(1,50000000) S(i);复制
串行创建BRIN索引
查看max_parallel_maintenance_workers默认参数值
查看max_parallel_maintenance_workers,该参数设置单一工具性命令能够启动的并行工作者的最大数目。默认值2,表示条件允许,可以启动两个工作程序来帮助创建索引。
testdb=# show max_parallel_maintenance_workers; max_parallel_maintenance_workers ---------------------------------- 2 (1 row)复制
设置max_parallel_maintenance_workers值
为了确保不会选择多核创建索引,在这里将max_parallel_maintenance_workers设置为0
SET max_parallel_maintenance_workers = 0;复制
创建BRIN索引
CREATE INDEX brin_test_serial_idx ON brin_parallel_test USING brin (a int4_minmax_ops, a int4_bloom_ops, b, c int8_minmax_multi_ops) WITH (pages_per_range=7); CREATE INDEX Time: 52435.488 ms (00:52.435)复制
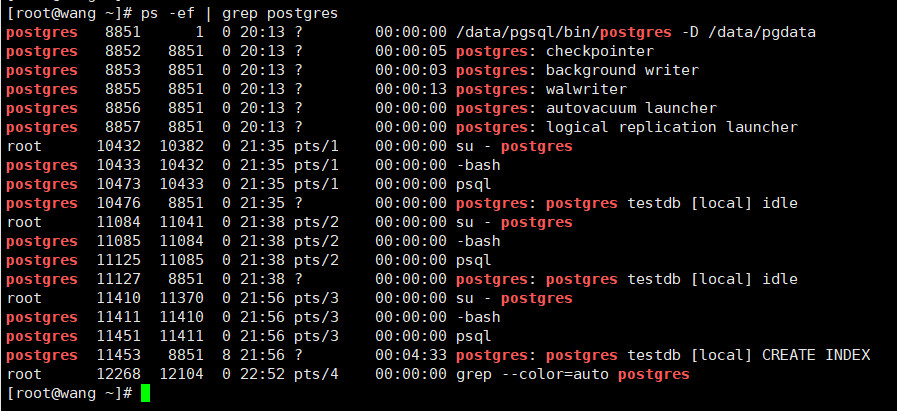
并行创建BRIN索引
设置并行参数及maintenance_work_mem
SET min_parallel_table_scan_size = 0; SET max_parallel_maintenance_workers = 4; SET maintenance_work_mem = '128MB';复制
创建BRIN索引
CREATE INDEX brin_test_parallel_idx ON brin_parallel_test USING brin (a int4_minmax_ops, a int4_bloom_ops, b, c int8_minmax_multi_ops) WITH (pages_per_range=7); CREATE INDEX Time: 12246.050 ms (00:12.246)复制
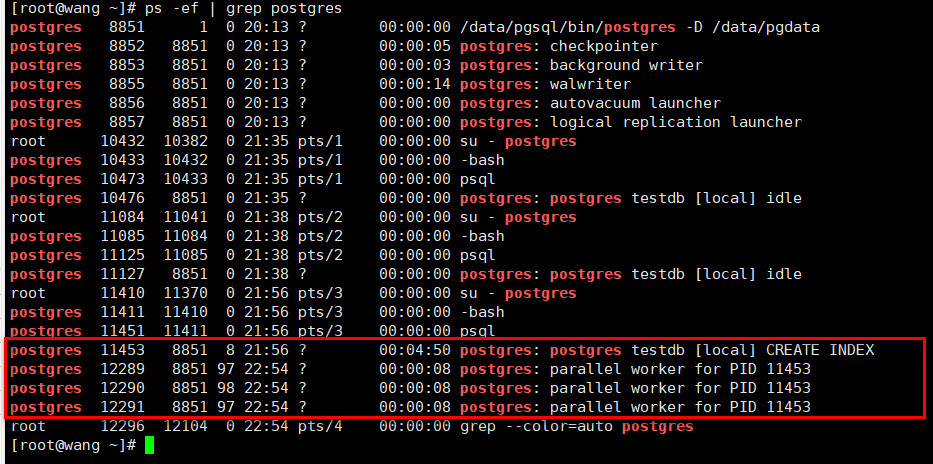
对比串行和并行串行索引是否一致
SELECT relname, relpages FROM pg_class WHERE relname IN ('brin_test_serial_idx', 'brin_test_parallel_idx') ORDER BY relname; relname | relpages ------------------------+---------- brin_test_parallel_idx | 3 brin_test_serial_idx | 3 (2 rows) --检查(A except B)和(B except A)是否为空,如果为空,这意味着索引是相同的。 SELECT * FROM brin_page_items(get_raw_page('brin_test_parallel_idx', 2), 'brin_test_parallel_idx') EXCEPT SELECT * FROM brin_page_items(get_raw_page('brin_test_serial_idx', 2), 'brin_test_serial_idx'); SELECT * FROM brin_page_items(get_raw_page('brin_test_serial_idx', 2), 'brin_test_serial_idx') EXCEPT SELECT * FROM brin_page_items(get_raw_page('brin_test_parallel_idx', 2), 'brin_test_parallel_idx');复制
从这里我们可以看出,对于串行和并行创建的索引,其结果是一致的。
总结
从上述的验证,在串行创建BRIN索引,耗时52.435s,并行创建BRIN索引,耗时12.246s,性能大幅提升。对于并行创建BRIN索引,当max_parallel_maintenance_workers为4时,通过观察后台的进程,是由一个主进程和3个辅助进程来创建索引的。
– / END / –
可以通过下面的方式联系我
如果这篇文章为你带来了灵感或启发,就请帮忙点赞、收藏、转发;如果文章中不严谨或者错漏之处,请及时评论指正。非常感谢!
最后修改时间:2025-02-06 11:07:09
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
目录
