




前言
主要为之前总结的源码文章补充流程图。
总结一下整体流程
说明
之前以Java Client为例,总结了 Insert 源码的整体流程及部分源码,由于各种原因,没有总结完。长时间不看这方面的源码,容易忘记,之前没有总结流程图,现在回忆起来比较麻烦,不如看流程图方便快捷。所以先补充总结一下之前文章中的流程图,再继续学习总结后面的源码,这样比较方便。
流程图
主要分为自己总结以及借助Shiyan Xu
总结的博客中的流程图一起理解。
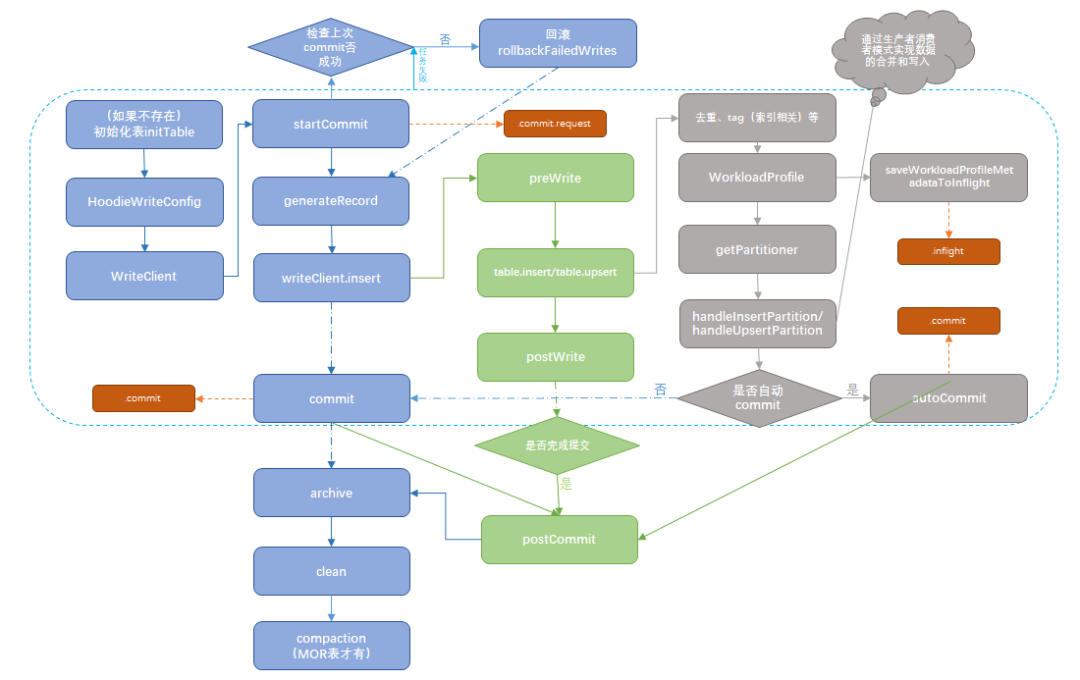
这个流程图主要是为之前的文章总结的,主要记录源码中关键的步骤和函数,适用于Java Client 和 Spark Client,Flink Client不太一样,但主要逻辑类似。
由于之前并没有总结tag(索引相关)和后面的写入合并逻辑(handleInsertPartition/handleUpsertPartition),并且很难在一个图中包含所有的细节,所以本流程图并不算完整。对于本图中不完整的部分我们可以借助其他人总结的流程图来辅助理解。
下面是Shiyan Xu
总结的Hudi从零到一博客系列中的流程图:
整体流程图(高级步骤)
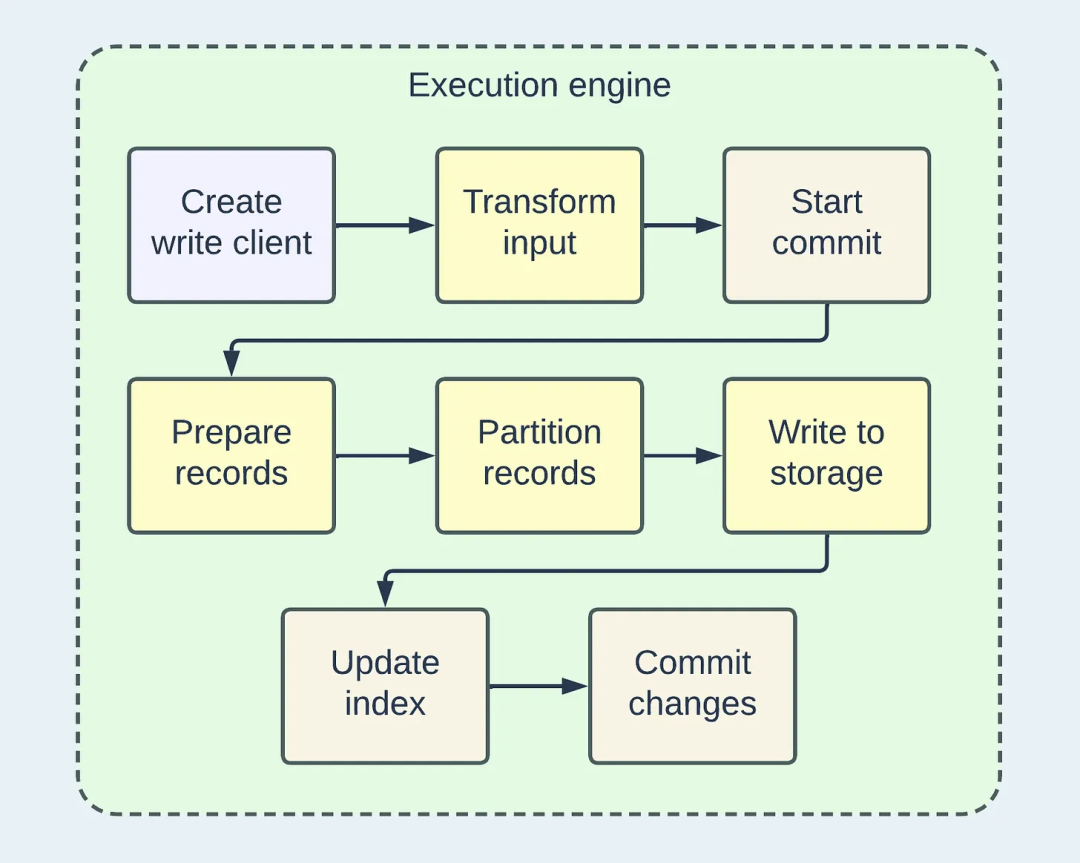
Upsert 流程图(偏细节)
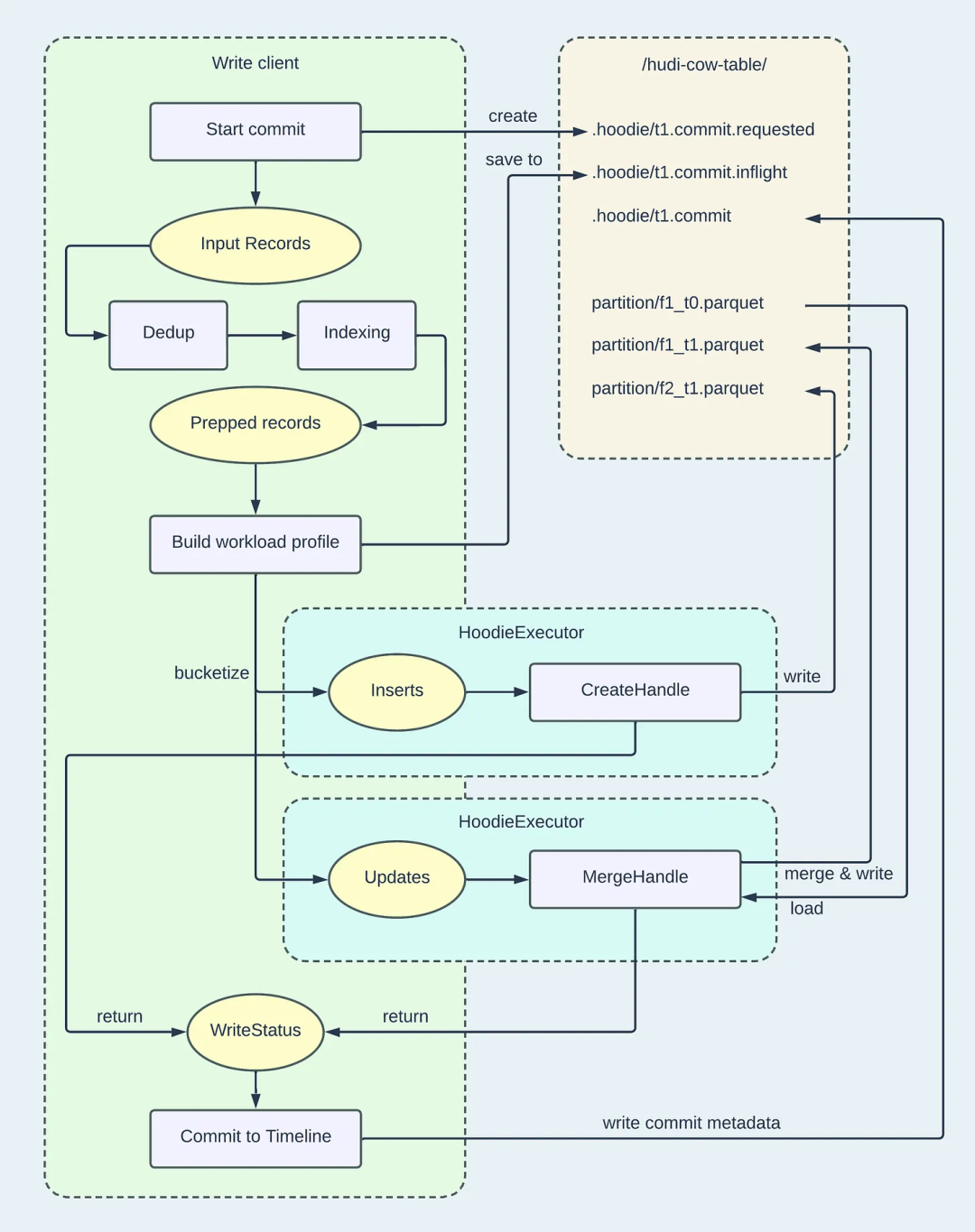
主要步骤
初始化表
initTable 先判断表是否存在,如果不存在,初始化表
Hudi 写配置
HoodieWriteConfig
创建写客户端
创建 WriteClient。
Java HoodieJavaWriteClient , Kafka Connect 使用的是 HoodieJavaWriteClient
Spark SparkRDDWriteClient
Flink HoodieFlinkWriteClient
构造 HoodieRecord (转换数据)
在写入客户端处理输入数据之前,会发生几个转换,包括HoodieRecords的构建和模式协调。让我们深入研究HoodieRecord,因为它是写入路径中的一个基本模型。
将输入的数据转换为 HoodieRecord
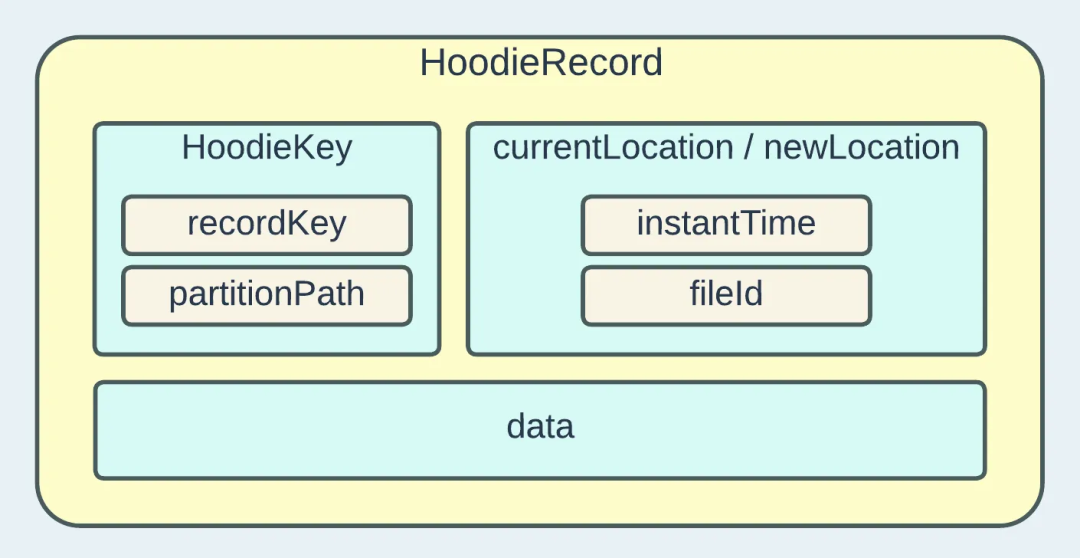
Hudi使用 HoodieKey 模型来标识唯一记录,该模型由“recordKey”和“partitionPath”组成。这些值是通过实现 KeyGenerator API 来填充的。该 API 可以灵活地根据输入模式提取自定义字段并将其转换为Key。“currentLocation”和“newLocation”均由 Hudi 时间线的操作时间戳和FileGroup的 ID 组成。时间戳指向特定 FileGroup 内的 FileSlice。“位置”属性用于使用逻辑信息来定位物理文件。如果“currentLocation”不为空,则表示表中存在具有相同键的记录,而“newLocation”则指定应将传入记录写入何处。“数据”字段是一个通用类型,包含记录的实际字节,也称为有效负载。通常,此属性实现 HoodieRecordPayload ,它指导引擎如何将旧记录与新记录合并。从 0.13.0 版本开始,引入了新的实验接口 HoodieRecordMerger 来替代 HoodieRecordPayload 并作为统一的合并 API。
在Spark Client 中用就是 HoodieRecord,具体构造为
JavaRDD[[HoodieRecord[_ <: HoodieRecordPayload]]
,在Java Client中构造的 HoodieRecord 为其子类 HoodieAvroRecord,具体为List<HoodieRecord<HoodieRecordPayload>>HoodieRecord 构造函数有两个参数:HoodieKey key, T data ,另外还有两个比较重要的属性:
currentLocation
和newLocationHoodieKey 由 recordKey 和 partitionPath 组成,用来标识唯一记录。
这里的 data 为 HoodieRecordPayload 的实现类。
currentLocation 和 newLocation 都是 HoodieRecordLocation ,分别代表文件的当前位置和新的位置。HoodieRecordLocation 由 instantTime 和 fileId 组成。currentLocation 和 newLocation 在构造 HoodieRecord 时的初始值均为 null ,具体使用在后面的索引和数据合并中。
开始提交
startCommit,会先判断是否有失败的commit,如果有,先执行回滚(rollbackFailedWrites)。这里对应创建 .commit.request
客户端执行写操作
writeClient.insert/upsert 等。
在 writeClient.insert/upsert 中执行 preWrite、table.insert/table.upsert、postWrite。
table.insert/table.upsert 主要执行:去重、tag(索引相关)、WorkloadProfile、getPartitioner、partition、handleInsertPartition/handleUpsertPartition、updateIndex、autoCommit。其中 WorkloadProfile、getPartitioner、partition、handleInsertPartition/handleUpsertPartition、updateIndex、autoCommit 是在 BaseCommitActionExecutor.execute 执行的。
postWrite 会判断是否完成提交,如果完成提交会调用postCommit,在 postCommit 中会执行后面的 archive和clean操作
准备数据
所提供的 HoodieRecord 可以根据用户配置和操作类型选择性地进行重复数据删除和索引。如果需要重复数据删除,具有相同键的记录将被合并为一条。如果需要索引,如果记录存在,则将填充“currentLocation”。
Java 和 Spark Client 在 AbstractWriteHelper.write 中实现;Flink 的代码逻辑和配置项都不太一样,Flink对应的实现类为 FlinkWriteHelper,但是 去重和tag(索引)并不是在 FlinkWriteHelper.write 中。
根据配置项 hoodie.combine.before.insert 判断是否需要去重,insert 默认不去重,upsert 默认去重。具体的去重逻辑通过各自的实现类中的 deduplicateRecords 方法实现。
Java Client : JavaWriteHelper
Spark Client : SparkWriteHelper
Flink Client : FlinkWriteHelper
索引在 AbstractWriteHelper.write 中通过调用 tag 方法实现。首先判断是否需要索引(performTagging),insert不需要索引,upsert需要索引。以布隆索引为例:
索引的逻辑主要是根据 parquet 文件中保存的索引信息,判断记录是否存在,如果不存在,代表是新增数据,如果记录存在则代表是更新数据,需要找到并设置 currentLocation。
主要是通过具体索引实现类的 tagLocation 设置 currentLocation。Java Client 对应实现类为 HoodieBaseBloomIndex;Spark Client 对应实现类为 SparkHoodieBloomIndex;Flink 不支持布隆索引。
Flink 并不是通过tag方法实现,由于对Flink 源码不是特别熟悉,并没有看到具体在哪里实现,原因可能和 Flink不支持布隆索引有关系。Flink 仅支持两种索引:`FLINK_STATE`和`BUCKET`(后来新增),默认`FLINK_STATE`。
分区记录
这是一个重要的预写入步骤,它确定哪个记录进入哪个文件组,并最终进入哪个物理文件。传入的记录将被分配到更新桶和插入桶,这意味着后续文件写入的策略不同。每个桶代表一个 RDD 分区,用于分布式处理,就像 Spark 的情况一样。
构建 WorkloadProfile
首先通过buildProfile构建WorkloadProfile,构建WorkloadProfile的目的主要是为给getPartitioner使用。WorkloadProfile包含了分区路径对应的insert/upsert数量以及upsert数据对应的文件位置信息 (fileId)。数量信息是为了分桶,或者说是为了分几个文件,这里涉及了小文件合并、文件大小等原理,位置信息是为了获取要更新的文件,也就是对应的fileId。对于upsert数据,我们复用原来的fileId,对于insert数据,我们生成新的fileId,如果record数比较多,则分多个文件写。
我们构建完 WorkloadProfile 之后,会先通过 saveWorkloadProfileMetadataToInflight 将WorkloadProfile元数据信息持久化到.inflight文件中。这里对应创建 .inflight
getPartitioner
根据WorkloadProfile获取 Partitioner 。
Java:无论 INSERT 还是 UPSERT 都返回 JavaUpsertPartitioner, 父类为 Hudi 中定义的 org.apache.hudi.table.action.commit.Partitioner
Spark 无论 INSERT 还是 UPSERT 都返回 UpsertPartitioner,父类为 Spark 源码中的 org.apache.spark.Partitioner
在 Partitioner 的构造函数中,会先调用 assignUpdates 然后调用 assignInserts 。assignUpdates 和 assignInserts 是这一步的主要逻辑
整体逻辑:
对于 updaet 数据,将 profile 中的fileId 分配到对应的 UPDATE 桶(对应update数据),
对于 insert 数据,根据 insert数量首先分配到小文件中,每个小文件对应的 fileId 分配对应的 UPDATE 桶, 如果还有未分配的数量,则根据剩余数量计算需要几个桶,将剩余数量分配到新增的几个 INSERT 桶中。
对于 insert 数据对应的桶,根据每个桶要插入的数据量和插入总数据量,计算权重 weight,构造
List<InsertBucketCumulativeWeightPair>
,为后面的 getPartition 方法使用。对于 UPDATE 桶,记录桶号和 fileId的对应关系,对于 INSERT 桶,记录桶号和对应的数据量。
assignUpdates :遍历 profile 中的分区路径以及对应的 fileId ,调用 addUpdateBucket 方法将 fileId 和 桶号对应起来, 一个 fileId 对应一个桶号,并且创建对应的 UPDATE 桶信息 BucketInfo , BucketInfo 包括 BucketType,fileId,partitionPath,桶信息也和对应的桶号意义对应,这里的桶类型为 UPDATE 。这里的步骤对应本次数据涉及更新的文件。
assignInserts :对于不涉及更新,只有插入的记录,调用 assignInserts。主要逻辑:遍历分区路径,根据 profile 获取该分区路径对应的插入总数据,接着获取所有的小文件,首先尝试将记录合并写到小文件中。
合并小文件逻辑:首先计算该小文件还可以插入多少条记录,以便更新剩余的未插入总数。根据小文件的fileId判断该小文件是否有对应的桶,如果该小文件已经存在于前面的 UPDATE 桶中了,则复用前面的桶,并记录该桶对应的insert数,如果没有,则调用 addUpdateBucket 新创建一个 UPDATE 桶。这里表明无论是更新数据还是插入数据,只要是已经存在fileId对应的桶类型都为 UPDATE。
分配完小文件,如果还有剩余记录未分配,则根据剩余记录数和每个桶可以插入的记录数计算新增的桶数。该新增桶类型 为 INSERT,记录每个新增的 INSERT 桶信息和桶号的对应关系。
partition
返回 partitionedRecords(<桶号,对应的HoodieRecord>),一个桶对应一个文件 fileId。
主要逻辑,通过调用 Partitioner 的 getPartition 方法,返回每个 HoodieRecord 对应的桶号。
getPartition 逻辑:
HoodieRecord 中有 HoodieKey 和 HoodieRecordLocation 。以 HoodieKey 为维度遍历:
如果该 HoodieRecord 有 HoodieRecordLocation,代表更新数据,则根据 HoodieRecordLocation 的 FileId 获取对应的桶号
如果该 HoodieRecord 没有 HoodieRecordLocation,代表插入数据,则将这些新增插入数据 根据插入总数和 Key 的 hash值算出权重值,利用二分法去前面的
List<InsertBucketCumulativeWeightPair>
查找对应的桶,这里的逻辑没还没有完全看明白。(不知道如何保证分配到每个桶的数据量和前面的计算值一样。)
handleUpsertPartition
遍历 partitionedRecords,每个桶执行一次写操作:handleInsertPartition/handleUpsertPartition,最终通过BoundedInMemoryExecutor.execute 生产者消费者模式写数据。
生产者消费者模式
首先,如何调用 BoundedInMemoryExecutor.execute ?
无论是 handleInsertPartition 还是 handleUpsertPartition 都是调用 handleUpsertPartition
handleUpsertPartition 返回的是
Iterator<List<WriteStatus>>Iterator.forEachRemaining(writeStatuses::addAll) 会调用 Iterator的 hasNext 和 next,将 next 返回的值添加到 writeStatuses 中
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
桶有两种类型(BucketType):INSERT 和 UPDATE 。INSERT 对应新增文件(新的fileId),新增文件只有新增的数据 ,UPDATE 包含更新数据和新增数据(小文件合并部分),UPDATE 对应已经存在的 FileID。
public O next() {
try {
return computeNext();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
@Override
protected List<WriteStatus> computeNext() {
// Executor service used for launching writer thread.
BoundedInMemoryExecutor<HoodieRecord<T>, HoodieInsertValueGenResult<HoodieRecord>, List<WriteStatus>> bufferedIteratorExecutor =
null;
try {
final Schema schema = new Schema.Parser().parse(hoodieConfig.getSchema());
bufferedIteratorExecutor =
new BoundedInMemoryExecutor<>(hoodieConfig.getWriteBufferLimitBytes(), new IteratorBasedQueueProducer<>(inputItr), Option.of(getInsertHandler()), getTransformFunction(schema));
// bufferedIteratorExecutor.execute通过生产者消费者模型实现写数据
final List<WriteStatus> result = bufferedIteratorExecutor.execute();
assert result != null && !result.isEmpty() && !bufferedIteratorExecutor.isRemaining();
return result;
} catch (Exception e) {
throw new HoodieException(e);
} finally {
if (null != bufferedIteratorExecutor) {
bufferedIteratorExecutor.shutdownNow();
}
}
}对于 UPDATE BucketType :调用 handleUpdate ,handleUpdate 首先创建 HoodieMergeHandle,然后在 handleUpdateInternal 方法中 调用了 JavaMergeHelper.newInstance().runMerge(table, upsertHandle) 。最终在 JavaMergeHelper 的 runMerge 方法中调用了 BoundedInMemoryExecutor.execute
对于 INSERT BucketType:调用 handleInsert ,返回 JavaLazyInsertIterable<>(recordItr, true, config, instantTime, table, idPfx, taskContextSupplier, new CreateHandleFactory<>())。JavaLazyInsertIterable 是 LazyIterableIterator的子类,其中 next 方法是在 LazyIterableIterator 中定义的,他会调用 computeNext(),computeNext() 在具体的子类中实现,JavaLazyInsertIterable 的 computeNext 方法中调用了 BoundedInMemoryExecutor.execute
生产消费者模式的大概逻辑
BoundedInMemoryExecutor.execute:
public E execute() {
try {
// 启动生产者,这里的生产者可以为多个
ExecutorCompletionService<Boolean> producerService = startProducers();
// 启动消费者,这里的消费者只能有一个
Future<E> future = startConsumer();
// Wait for consumer to be done
return future.get();
} catch (InterruptedException ie) {
shutdownNow();
Thread.currentThread().interrupt();
throw new HoodieException(ie);
} catch (Exception e) {
throw new HoodieException(e);
}
}
主要逻辑是:1、启动生产者(可以多个)2、启动消费者(只有一个)
生产者:producer.produce(queue),对于 insert 和 update ,producer都为 IteratorBasedQueueProducer ,IteratorBasedQueueProducer.produce :
@Override
public void produce(BoundedInMemoryQueue<I, ?> queue) throws Exception {
LOG.info("starting to buffer records");
while (inputIterator.hasNext()) {
queue.insertRecord(inputIterator.next());
}
LOG.info("finished buffering records");
}
其中,queue.insertRecord 的会调用 transformFunction 并将其返回值添加到 queue 中:
public void insertRecord(I t) throws Exception {
// If already closed, throw exception
if (isWriteDone.get()) {
throw new IllegalStateException("Queue closed for enqueueing new entries");
}
// We need to stop queueing if queue-reader has failed and exited.
throwExceptionIfFailed();
rateLimiter.acquire();
// We are retrieving insert value in the record queueing thread to offload computation
// around schema validation
// and record creation to it.
final O payload = transformFunction.apply(t);
adjustBufferSizeIfNeeded(payload);
queue.put(Option.of(payload));
}
消费者:consumer.consume(queue):
while (iterator.hasNext()) {
consumeOneRecord(iterator.next());
}
到 HoodieCreateHandle 和 HoodieMergeHandle 的调用逻辑?
我们知道:对于更新操作,写数据的逻辑由 HoodieMergeHandle 实现,对于插入操作,写数据的逻辑由 HoodieCreateHandle 实现,那么调用逻辑是啥呢?
INSERT BucketType :consumer 为 getInsertHandler()返回的 CopyOnWriteInsertHandler 。由上面步骤 2 可知会调用 consumeOneRecord ,在 CopyOnWriteInsertHandler 的 consumeOneRecord 方法中通过调用 writeHandleFactory.create 创建了 HoodieCreateHandle(这里的 writeHandleFactory 是在前面的 handleInsert 方法中传入的 CreateHandleFactory),最后调用 HoodieCreateHandle.write 真正实现写数据的逻辑 (插入数据)。
UPDATE BucketType :consumer 为 new UpdateHandler(mergeHandle),这里的 mergeHandle 为 HoodieMergeHandle 。UpdateHandler 的 consumeOneRecord 方法会直接调用 upsertHandle.write 方法也就是调用 HoodieMergeHandle.write 真正实现写数据的逻辑 (更新数据)。
写入存储
这是发生实际 I/O 操作的时候。使用文件写入句柄创建或附加物理数据文件。在此之前,标记文件也可以在.hoodie/.temp/目录中创建,以指示将对相应的数据文件执行的写入操作的类型。这对于高效的回滚和冲突解决方案非常有价值。
插入和更新操作分别对应 HoodieCreateHandle.write 和 HoodieMergeHandle.write 。
更新索引
将数据写入磁盘后,可能需要立即更新索引数据以确保读/写的正确性。这特别适用于在写入过程中未同步更新的索引类型,例如HBase服务器中托管的HBase索引。
执行完 handleUpsertPartition 会调用 updateIndex(writeStatuses, result) 和 updateIndexAndCommitIfNeeded(writeStatuses, result) 更新索引。
Java Client : BaseJavaCommitActionExecutor.execute updateIndex 、updateIndexAndCommitIfNeeded
Spark Client : BaseSparkCommitActionExecutor.execute updateIndexAndCommitIfNeeded
完成提交
在最后一步中,写入客户端将承担多个任务,以正确完成事务写入。例如,如果配置了预提交验证,它可以运行预提交验证、检查与并发写入程序的冲突、将提交元数据保存到Timeline、将WriteStatus与标记文件进行协调等等。
这里对应创建 .commit
自动提交:在 updateIndexAndCommitIfNeeded 会调用 commitOnAutoCommit ,如果自动提交(config.shouldAutoCommit() ,默认true),则通过 autoCommit 方法完成提交。
手动提交:如果 config.shouldAutoCommit() 为false ,如 Spark Client 在 DataSourceUtils.createHoodieConfig 通过 withAutoCommit(false) 将自动提交改为false。这时需要手动调用 coomit方法完成提交。如 Spark Client 是在 HoodieSparkSqlWriter.write 通过调用 commitAndPerformPostOperations 方法继而调用client.commit 等方法完成提交的。
归档
Timline(时间轴)由很多 instant构成,按照时间由小到大排列。当不断写入Hudi数据集时,Timeline上的 Instant会不断增加,为减小 Timeline的操作压力,会在 commit时按照配置对 instant进行归档,并从 Timeline上将已归档的 instant删除。
Archive 在 postCommit 中调用:
HoodieTimelineArchiveLog archiveLog = new HoodieTimelineArchiveLog(config, table);
archiveLog.archiveIfRequired(context);
清理
删除旧版本文件
Clean 同样在 postCommit 调用,方法:autoCleanOnCommit
压缩 (Compaction)
压缩(Compaction)是Hudi专门在读取合并(MOR)表中使用的一种表服务,用于定期将基于行的日志文件(.log)的更新合并到相应的基于列的基础文件(如.parquet),以生成基础文件的新版本。压缩不适用于写入时复制(COW)表,仅适用于MOR表。默认异步压缩
相关阅读及参考文章
Shiyan Xu
总结的Hudi从零到一博客系列https://blog.datumagic.com/p/apache-hudi-from-zero-to-one-310
https://www.linkedin.com/posts/xushiyan_apache-hudi-from-zero-to-one-1010-activity-7184821085631135744-_XnV/?utm_source=share&utm_medium=member_ios
https://www.onehouse.ai/whitepaper/ebook-apache-hudi---zero-to-one
https://info.onehouse.ai/hubfs/ebook-apache-hudi-0-to-1.pdf
Apache Hudi 翻译的
Shiyan Xu
总结的博客自己总结的博客
Hudi 生产者消费者模式
🧐 分享、点赞、在看,给个3连击呗!👇
