




前言
经常碰到有人问这样的问题:虚拟机里面执行gs_install安装磐维2.0.2时,为啥数据库起不来呢,我都重新安装好几遍了。。。

今天正好又碰到了这个问题,现在把整个处理过程整理出来,以便能帮助到大家。
问题再现
虚拟机里面执行gs_install安装磐维2.0.2数据库,gs_install执行过程记录如下:
omm@node1 ~]$ gs_install -X /database/panweidb/soft/panweidb1m2s.xml \ > --gsinit-parameter="--encoding=UTF8" \ > --gsinit-parameter="--lc-collate=C" \ > --gsinit-parameter="--lc-ctype=C" \ > --gsinit-parameter="--dbcompatibility=B" Parsing the configuration file. Successfully checked gs_uninstall on every node. Check preinstall on every node. Successfully checked preinstall on every node. Creating the backup directory. Successfully created the backup directory. begin deploy.. Installing the cluster. begin prepare Install Cluster.. Checking the installation environment on all nodes. begin install Cluster.. Installing applications on all nodes. Successfully installed APP. begin init Instance.. encrypt cipher and rand files for database. Please enter password for database: Please repeat for database: begin to create CA cert files The sslcert will be generated in /database/panweidb/app/share/sslcert/om Create CA files for cm beginning. Create CA files on directory [/database/panweidb/app_2b900fc/share/sslcert/cm]. file list: ['client.key.rand', 'client.crt', 'cacert.pem', 'server.key', 'server.key.rand', 'server.crt', 'client.key.cipher', 'client.key', 'server.key.cipher'] Non-dss_ssl_enable, no need to create CA for DSS Cluster installation is completed. Configuring. Deleting instances from all nodes. Successfully deleted instances from all nodes. Checking node configuration on all nodes. Initializing instances on all nodes. Updating instance configuration on all nodes. Check consistence of memCheck and coresCheck on database nodes. Successful check consistence of memCheck and coresCheck on all nodes. Warning: The license file does not exist, so there is no need to copy it to the home directory. Configuring pg_hba on all nodes. Configuration is completed. Starting cluster. ====================================================================== [GAUSS-51607] : Failed to start cluster. Error: cm_ctl: checking cluster status. cm_ctl: checking cluster status. cm_ctl: checking finished in 610 ms. cm_ctl: start cluster. cm_ctl: start nodeid: 1 cm_ctl: start nodeid: 2 cm_ctl: start nodeid: 3 .......................................................................................................................................................................................................................................................................................................... cm_ctl: start cluster failed in (300)s! HINT: Maybe the cluster is continually being started in the background. You can wait for a while and check whether the cluster starts, or increase the value of parameter "-t", e.g -t 600. The cluster may continue to start in the background. If you want to see the cluster status, please try command gs_om -t status. If you want to stop the cluster, please try command gs_om -t stop. [GAUSS-51607] : Failed to start cluster. Error: cm_ctl: checking cluster status. cm_ctl: checking cluster status. cm_ctl: checking finished in 610 ms. cm_ctl: start cluster. cm_ctl: start nodeid: 1 cm_ctl: start nodeid: 2 cm_ctl: start nodeid: 3 .......................................................................................................................................................................................................................................................................................................... cm_ctl: start cluster failed in (300)s! HINT: Maybe the cluster is continually being started in the background. You can wait for a while and check whether the cluster starts, or increase the value of parameter "-t", e.g -t 600. [omm@node1 ~]$复制
处理过程
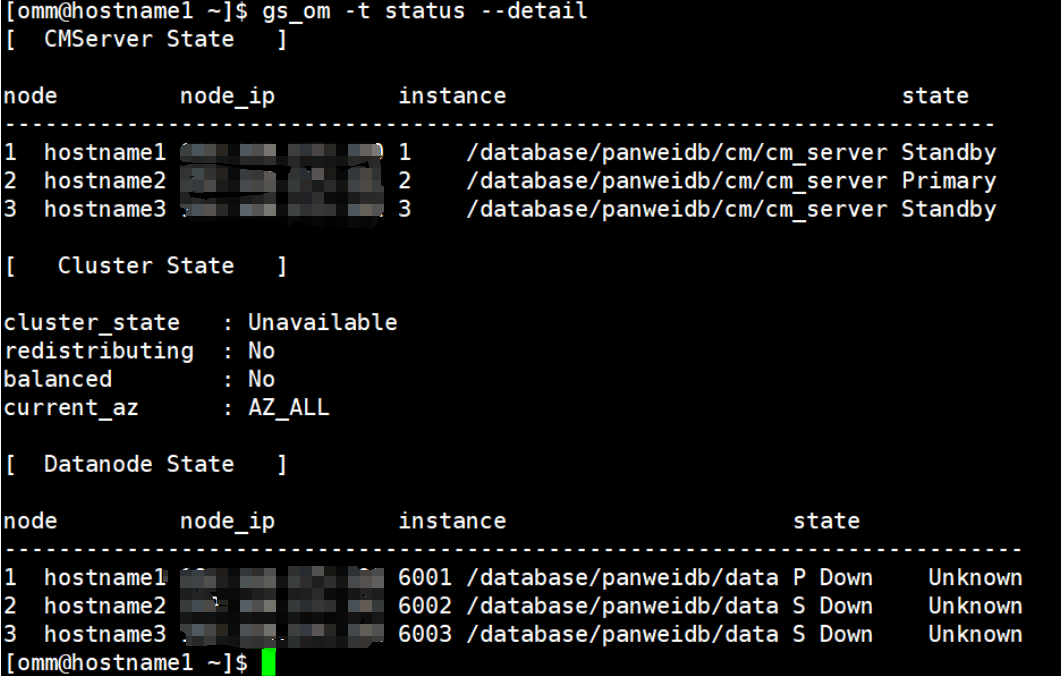
在集群另一个节点查看集群状态,可以看到 CMServer 已经正常启动,但是Datanode State异常。
[omm@node2 ~]$ gs_om -t status --detail [ CMServer State ] node node_ip instance state --------------------------------------------------------------------- 1 node1 *.*.*.50 1 /database/panweidb/cm/cm_server Primary 2 node2 *.*.*.52 2 /database/panweidb/cm/cm_server Standby 3 node3 *.*.*.54 3 /database/panweidb/cm/cm_server Standby [ Cluster State ] cluster_state : Unavailable redistributing : No balanced : No current_az : AZ_ALL [ Datanode State ] node node_ip instance state ----------------------------------------------------------------------- 1 node1 *.*.*.50 6001 /database/panweidb/data P Down Unknown 2 node2 *.*.*.52 6002 /database/panweidb/data S Down Unknown 3 node3 *.*.*.54 6003 /database/panweidb/data S Down Unknown复制
在datanode主节点查看数据库日志
[omm@node1 ~]$ cd /database/panweidb/log/omm/pg_log/dn_6001/ [omm@node1 dn_6001]$ ls -l total 0复制
可以看到,数据库日志没有生成。
在datanode主节点尝试手工拉起数据库单实例
[omm@node1 dn_6001]$ gs_ctl start -D /database/panweidb/data [2024-07-08 19:44:12.084][84774][][gs_ctl]: gs_ctl started,datadir is /database/panweidb/data [2024-07-08 19:44:12.135][84774][][gs_ctl]: waiting for server to start... ...<略> ...<略> 2024-07-08 19:44:12.267 668bd10c.1 [unknown] 139661863719424 [unknown] 0 dn_6001_6002_6003 00000 0 [BACKEND] LOG: Set max backend reserve memory is: 660 MB, max dynamic memory is: 4192174 MB 2024-07-08 19:44:12.267 668bd10c.1 [unknown] 139661863719424 [unknown] 0 dn_6001_6002_6003 42809 0 [BACKEND] FATAL: the values of memory out of limit, the database failed to be started, max_process_memory (2048MB) must greater than 2GB + cstore_buffers(512MB) + (udf_memory_limit(200MB) - UDF_DEFAULT_MEMORY(200MB)) + shared_buffers(647MB) + preserved memory(3018MB) = 6225MB, reduce the value of shared_buffers, max_pred_locks_per_transaction, max_connection, wal_buffers..etc will help reduce the size of preserved memory 2024-07-08 19:44:12.275 668bd10c.1 [unknown] 139661863719424 [unknown] 0 dn_6001_6002_6003 00000 0 [BACKEND] LOG: FiniNuma allocIndex: 0. [2024-07-08 19:44:13.136][84774][][gs_ctl]: waitpid 84777 failed, exitstatus is 256, ret is 2 [2024-07-08 19:44:13.136][84774][][gs_ctl]: stopped waiting [2024-07-08 19:44:13.136][84774][][gs_ctl]: could not start server Examine the log output.复制
可以看到这样的报错:the database failed to be started, max_process_memory (2048MB) must greater than …
至此,问题已经一目了然,是因为 max_process_memory 内存参数小于其他内存参数值的总和导致的数据库实例无法正常启动。
解决方法
方法一:
使用gs_guc命令调整max_process_memory参数的值,使其大于日志里面提示的其他各项参数的和即可。
方法二:
减小其他各项参数的值,shared_buffers, cstore_buffers,max_pred_locks_per_transaction, max_connection参数。
这里使用方法一,使用gs_guc命令调整加大max_process_memory参数的值解决。方法二大家可以自行去尝试。
[omm@node1 dn_6001]$ gs_guc set -N all -I all -c "max_process_memory=7000MB" The pw_guc run with the following arguments: [gs_guc -N all -I all -c max_process_memory=7000MB set ]. Begin to perform the total nodes: 3. Popen count is 3, Popen success count is 3, Popen failure count is 0. Begin to perform gs_guc for datanodes. Command count is 3, Command success count is 3, Command failure count is 0. Total instances: 3. Failed instances: 0. ALL: Success to perform gs_guc! [omm@node1 dn_6001]$ gs_guc set -N all -I all -c "max_process_memory=7000MB" The pw_guc run with the following arguments: [gs_guc -N all -I all -c max_process_memory=7000MB set ]. Begin to perform the total nodes: 3. Popen count is 3, Popen success count is 3, Popen failure count is 0. Begin to perform gs_guc for datanodes. Command count is 3, Command success count is 3, Command failure count is 0. Total instances: 3. Failed instances: 0. ALL: Success to perform gs_guc! [omm@node1 dn_6001]$ cm_ctl stop cm_ctl: stop cluster. cm_ctl: stop nodeid: 1 cm_ctl: stop nodeid: 2 cm_ctl: stop nodeid: 3 ............ cm_ctl: stop cluster successfully. [omm@node1 dn_6001]$ cm_ctl start cm_ctl: checking cluster status. cm_ctl: checking cluster status. cm_ctl: checking finished in 600 ms. cm_ctl: start cluster. cm_ctl: start nodeid: 1 cm_ctl: start nodeid: 2 cm_ctl: start nodeid: 3 ................................... cm_ctl: start cluster successfully.复制
查看集群状态
[omm@node1 dn_6001]$ gs_om -t status --detail [ CMServer State ] node node_ip instance state --------------------------------------------------------------------- 1 node1 *.*.*.50 1 /database/panweidb/cm/cm_server Primary 2 node2 *.*.*.52 2 /database/panweidb/cm/cm_server Standby 3 node3 *.*.*.54 3 /database/panweidb/cm/cm_server Standby [ Cluster State ] cluster_state : Normal redistributing : No balanced : Yes current_az : AZ_ALL [ Datanode State ] node node_ip instance state ----------------------------------------------------------------------- 1 node1 *.*.*.50 6001 /database/panweidb/data P Primary Normal 2 node2 *.*.*.52 6002 /database/panweidb/data S Standby Normal 3 node3 *.*.*.54 6003 /database/panweidb/data S Standby Normal复制
至此,数据库集群已经正常启动。
总结
把处理问题的过程分享出来是一种快乐,希望大家都能学有所获。
同时,希望大家能一起交流,共同进步!
最后修改时间:2024-07-10 10:49:38
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
磐维运维管理平台(panwei_dbops)部署及使用(2025.03.30)
飞天
121次阅读
2025-03-30 23:47:45
磐维分布式数据库备份部署
飞天
78次阅读
2025-03-28 23:46:28
【磐维数据库】容灾搭建过程中的 step 与 sdr 状态更新
Darcy
69次阅读
2025-03-16 19:42:55
磐维数据库运维合集(一):日常运维相关命令
钟一
65次阅读
2025-04-02 17:20:32
【磐维数据库】单机扩容一主一备高可用实践指南
Darcy
65次阅读
2025-03-16 19:00:55
磐维数据库gs_probackup的PITR恢复演练
杨金福
64次阅读
2025-03-21 16:51:38
【实操记录】磐维数据库-a模式下的一个别名大小写问题,及相关参数测试
磐维数据库
59次阅读
2025-03-31 17:41:46
【干货分享】磐维数据库分布式升级v1.4经验分享
磐维数据库
57次阅读
2025-03-31 17:02:10
【数据安全管理】磐维数据库-关于审计的经验分享
磐维数据库
53次阅读
2025-03-31 17:37:00
磐维数据库出现锁超时如何处理“ERROR: Lock wait timeout”
王贝
39次阅读
2025-04-01 10:28:33



