




oracle问题分析及解决 enq:HW–contention
根据开发反馈。盘点时间内数据库变得很慢,根据AWR报告分析了解到。enq:HW–contention占大头.将近60%.
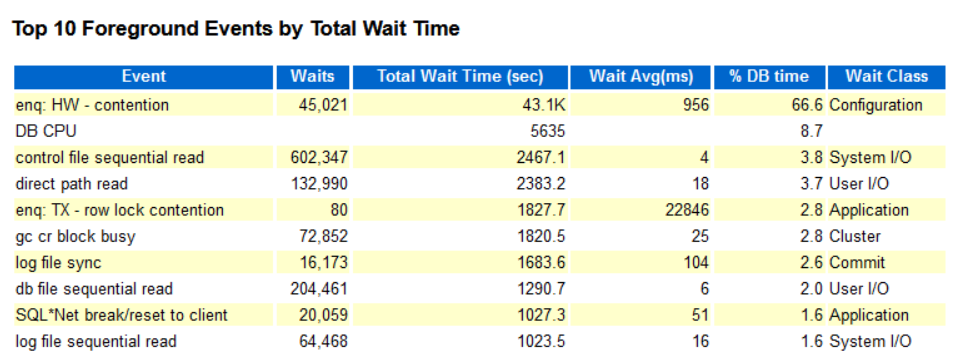
enq: HW - contention的官方说明及解释
通过查询官方能够得到大概意思.等待事件从分类来看属于enq,这个是内存结构锁且是serial。
Enqueues are shared memory structures (locks) that serialize access to database resources. They can be associated with a session or transaction.
The HW enqueue is used to manage the allocation of space beyond the high water mark of a segment. The high water mark of a segment is the boundary between used and unused space in that segment. If contention is occurring for “enq: HW – contention” it is possible that automatic extension is occuring to allow the extra data to be stored since the High Water Mark has been reached. Frequent allocation of extents, reclaiming chunks, and sometimes poor I/O performance may be causing contention for the LOB segments high water mark.
据官方文档描述,Oracle设计 HW – contention队列意义在于对于数据库资源来讲,对于保护内存结构都需要“锁”的概念来控制并发,当申请超过高水位空间时,为防止多个进程同时修改HWM而提供的锁称为HW锁。想要移动HWM的进程必须获得HW锁,但是获取HW锁还是排他锁,因为是加排他锁来保证结构不被破坏.enq: HW – contention这个等待,简言之为’HW等待’,每当请求扩展segment高水位线high water mark之外的空间时需要获取申请锁。
HW锁争用大部分是因大量执行insert所引发的,偶尔也会因大量执行update在回滚段中发生HW锁争用现象。若是update,表中段的扩展的大小虽然不多,但在创建回滚数据的过程中,需要回滚段的急速扩张。HW锁争用是在急速空间扩张时普遍出现的等待现象,有时也会引发严重的性能下降。
enq:HW–contention问题分析
查询对应时间段内的enq: HW - contention
select p1,p2,p3,count(*) from dba_hist_active_sess_history t
where event='enq: HW - contention' and t.sample_time>=timestamp'2021-11-25 15:20:00' and t.sample_time<=timestamp'2021-11-25 15:30:00'复制
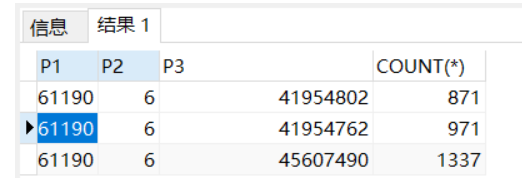
其中p1,p2,p3解释:
P1 = name|mode
P2 = tablespace#
P3 = block (RDBA)
name|mode
The lock name and requested mode are encoded into P1 as "name<<16 | mode". This is best seen in P1RAW (or you can convert P1 to hexadecimal).
For this wait:
name is always the ASCII for "HW" = 0x4857
mode is the mode that the HW lock is being requested in.
In most cases mode will be either mode 4 or mode 6:
"6" = eXclusive mode TX wait.
"4" = Shared mode TX wait.
eg: P1RAW of 48570006 = eXclusive mode HW wait, P1RAW of 48570004 = Shared mode HW wait.----
定位具体对象
用P3定位到具体争用定位对象
SELECT DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE(45607490) RELFILE#, DBMS_UTILITY.DATA_BLOCK_ADDRESS_BLOCK(45607490) BLOCK# FROM dual;复制
FILE# BLOCK#
10 3664450
根据FILE#与BLOCK#定位具体OBJECT
SQL> select OWNER,SEGMENT_NAME from dba_extents where FILE_ID =10 and 3664450 between block_id and block_id + block_id -1;
OWNER
------------------------------
SEGMENT_NAME
--------------------------------------------------------------------------------
OCC_20191204
STOCK_SALE_OUT_ORDER
OCC_20191204
STOCK_SALE_OUT_ORDER
OCC_20191204
STOCK_SALE_OUT_ORDER复制
事件征用
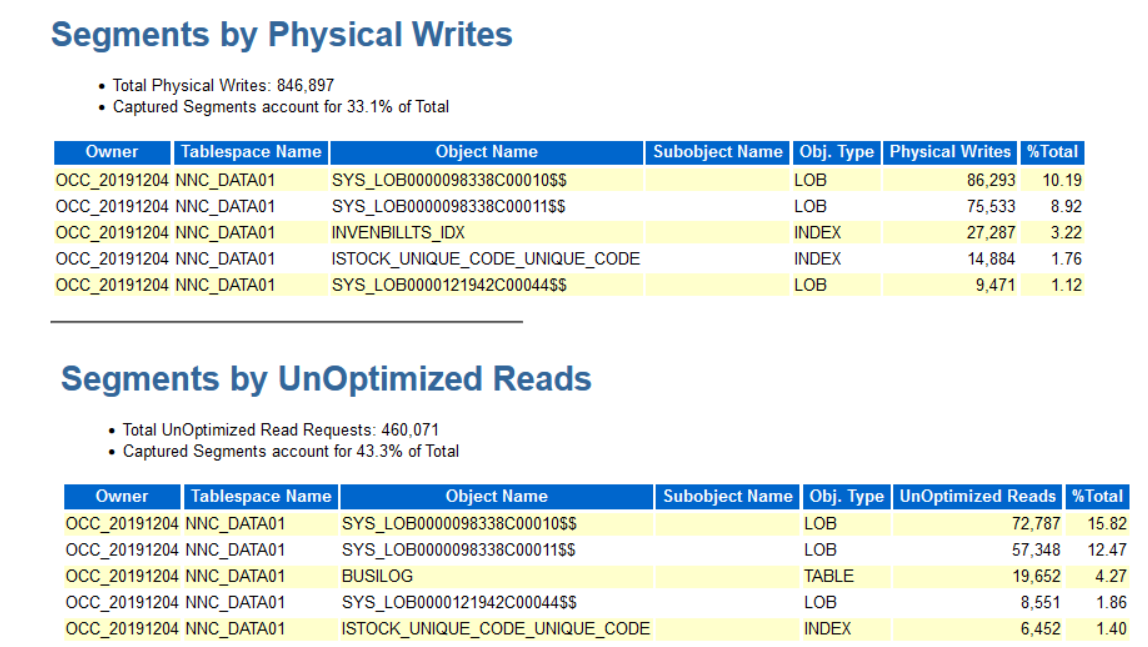
SYS_LOB0000098338C00010$$ Obj. Type LOB
根据lob字段 查到相对应的表。
SELECT OWNER ,
TABLE_NAME ,
SEGMENT_NAME
FROM DBA_LOBS
WHERE SEGMENT_NAME = 'SYS_LOB0000098338C00010$$';
OWNER TABLE_NAME
------------------------------ ------------------------------
SEGMENT_NAME
------------------------------
OCC_20191204 STOCK_INVENTORY_UNIQUE_CODE
SYS_LOB0000098338C00010$$复制
现在,已经查到是哪个LOB段造成的HW等待。应该向段中手动添加一个新的扩展区来解决问题。
添加一个该段中最大扩展区大小相同的扩展区。
查询对象最大扩展区的大小。
SELECT DISTINCT BYTES
FROM DBA_EXTENTS
WHERE SEGMENT_NAME = 'SYS_LOB0000098338C00010$$'
AND OWNER ='OCC_20191204
BYTES
----------
4194304
17825792
67108864
44040192
20971520
6291456
7340032
25165824
58720256
50331648
49283072
BYTES
----------
28311552
18874368
8388608
3145728
47185920
2097152
29360128
66060288
54525952
1048576
41943040
BYTES
----------
60817408
55574528
57671680
65536
5242880
34603008
24117248
42991616复制
向lob字段添加扩展区。
常见的原因:
1, 频繁的insert
2, IO性能差
3, LOB 对象回收
4, LOB相关的BUG
常见的解决⽅法:
1, move 到ASSM 管理的表空间
2, ⼿动预分配空间allocate extent
alter system set events '44951 trace name context forever, level 1024';复制
提高 LOB得预分配空间,减少高水位征用
需要注意的是,这种设置方法在重启数据库后就会失效,若需要重启后永久生效,需设置event:
alter system set event='44951 trace name context forever, level 1024' scope=spfile;复制
两个都要执行
一个是立即生效,另一个是写到参数文件里,重启依然有效;
原理:
LOB字段在insert得时候改参数前默认只分配1个chunk, 并发的insert就是造成频繁的分配, 分配不过来就会等待,就是这个等待事件。 设置参数后,一次分配 1024个chunk, 意思通过加大一次分配的大小,减少了分配的次数,就减少了这个等待;
3, 查找物理IO读较⾼的SQL 或 查找存储性能问题
4, 如果lob对象存在较频繁的更新,可以考虑增加LOB PCTVERSION to 20%,保留更多的空间⽤于lob的旧版本,考虑lob 分区或增加lob 段的chunk⼤⼩
5, 由于ASSM LOB空间分析⼀次只获取⼀个块,导致HW争⽤,应⽤ Bug 6376915实现批量回收,
或通过此修复程序,ASSM LOB将基于事件44951的值获得最⼩数量的块(最⼤设置为1024)。
alter system set events '44951 trace name context forever, level 1024';
6, 迁移basicfile LOBs到Securefiles LOB对于11g or later. Securefile LOBs对于并发的性能更好
alter table USER.TAB modify lob (COL_NAME) (allocate extent (size 64M));
分区表:
alter table USER.TAB modify partition par_Name lob (COL_NAME) (allocate extent (size 2g));复制
评论

 0 点赞
0 点赞



