




我们再来看一下PL/SQL块的执行过程:当PL/SQL运行时引擎处理一块代码时,它使用PL/SQL引擎来执行过程化的代码,而将SQL语句发送给SQL引擎来执行;SQL引擎执行完毕后,将结果再返回给PL/SQL引擎。这种在PL/SQL引擎和SQL引擎之间的交互,称为上下文交换(context switch)。每发生一次交换,就会带来一定的额外开销。

1. FORALL,用于增强PL/SQL引擎到SQL引擎的交换。
2. BULK COLLECT,用于增强SQL引擎到PL/SQL引擎的交换。
FORALL介绍
1. FORALL介绍
使用FORALL,可以将多个DML批量发送给SQL引擎来执行,最大限度地减少上下文交互所带来的开销。下面是 FORALL 的一个示意图:
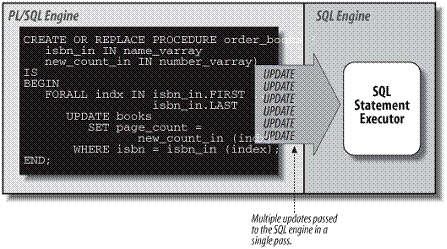
语法:
FORALL index_name IN
{ lower_bound .. upper_bound
| INDICES OF collection_name [ BETWEEN lower_bound AND upper_bound ]
| VALUES OF index_collection
}
[ SAVE EXCEPTIONS ] dml_statement;
说明:
- index_name:一个无需声明的标识符,作为集合下标使用。
- lower_bound … upper_bound:数字表达式,来指定一组连续有效的索引数字下限和上限。该表达式只需解析一次。
- INDICES OF collection_name:用于指向稀疏数组的实际下标。跳过没有赋值的元素,例如被 DELETE 的元素,NULL 也算值。
- VALUES OF index_collection_name:把该集合中的值当作下标,且该集合值的类型只能是 PLS_INTEGER/BINARY_INTEGER。
- SAVE EXCEPTIONS:可选关键字,表示即使一些DML语句失败,直到FORALL LOOP执行完毕才抛出异常。可以使用SQL%BULK_EXCEPTIONS 查看异常信息。
- dml_statement:静态语句,例如:UPDATE或者DELETE;或者动态(EXECUTE IMMEDIATE)DML语句。
2. FORALL的使用
示例所使用表结构:
id NUMBER(5),
name VARCHAR2(50)
);
示例1,使用FORALL批量插入、修改、删除数据:
–批量插入
DECLARE
-- 定义索引表类型
TYPE tb_table_type IS TABLE OF tmp_tab%rowtype INDEX BY BINARY_INTEGER;
tb_table tb_table_type;
BEGIN
FOR i IN 1..100 LOOP
tb_table(i).id:=i;
tb_table(i).name:='NAME'||i;
END LOOP;
FORALL i IN 1..tb_table.count
INSERT INTO tmp_tab VALUES tb_table(i);
END;
/
–批量修改
DECLARE
TYPE tb_table_type IS TABLE OF tmp_tab%rowtype INDEX BY BINARY_INTEGER;
tb_table tb_table_type;
BEGIN
FOR i IN 1..100 LOOP
tb_table(i).id:=i;
tb_table(i).name:='MY_NAME_'||i;
END LOOP;
FORALL i IN 1..tb_table.count
UPDATE tmp_tab t SET row = tb_table(i) WHERE t.id =tb_table(i).id;
END;
/
–批量删除
DECLARE
TYPE tb_table_type IS TABLE OF tmp_tab%rowtype INDEX BY BINARY_INTEGER;
tb_table tb_table_type;
BEGIN
FOR i IN 1..10 LOOP
tb_table(i).id:=i;
tb_table(i).name:='MY_NAME_'||i;
END LOOP;
FORALL i IN 1..tb_table.count
DELETE FROM tmp_tab WHERE id =tb_table(i).id;
END;
/
示例2,使用INDICES OF子句:
DECLARE
TYPE demo_table_type IS TABLE OF tmp_tab%rowtype INDEX BY BINARY_INTEGER;
demo_table demo_table_type;
BEGIN
FOR i IN 1..10 LOOP
demo_table(i).id:=i;
demo_table(i).name:='NAME'||i;
END LOOP;
-- 使用集合的delete方法移除第3、6、9三个成员
demo_table.delete(3);
demo_table.delete(6);
demo_table.delete(9);
FORALL i IN INDICES OF demo_table
INSERT INTO tmp_tab VALUES demo_table(i);
END ;
/
示例3,使用VALUES OF子句:
DECLARE
TYPE index_poniter_type IS TABLE OF pls_integer;
index_poniter index_poniter_type;
TYPE demo_table_type IS TABLE OF tmp_tab%rowtype INDEX BY BINARY_INTEGER;
demo_table demo_table_type;
BEGIN
index_poniter := index_poniter_type(1,3,5,7);
FOR i IN 1..10 LOOP
demo_table(i).id:=i;
demo_table(i).name:='NAME'||i;
END LOOP;
FORALL i IN VALUES OF index_poniter
INSERT INTO tmp_tab VALUES demo_table(i);
END;
/
3. FORALL注意事项
使用FORALL时,应该遵循如下规则:
- FORALL语句的执行体,必须是一个单独的DML语句,比如INSERT,UPDATE或DELETE。
- 不要显式定义index_row,它被PL/SQL引擎隐式定义为PLS_INTEGER类型,并且它的作用域也仅仅是FORALL。
- 这个DML语句必须与一个集合的元素相关,并且使用FORALL中的index_row来索引。注意不要因为index_row导致集合下标越界。
- lower_bound和upper_bound之间是按照步进 1 来递增的。
- 在sql_statement中,不能单独地引用集合中的元素,只能批量地使用集合。
- 在sql_statement中使用的集合,下标不能使用表达式。
4. BULK COLLECT介绍
BULK COLLECT子句会批量检索结果,即一次性将结果集绑定到一个集合变量中,并从SQL引擎发送到PL/SQL引擎。
通常可以在SELECT INTO、FETCH INTO以及RETURNING INTO子句中使用BULK COLLECT。下面逐一描述BULK COLLECT在这几种情形下的用法。
5. BULK COLLECT的使用
5.1 在SELECT INTO中使用BULK COLLECT
示例:
DECLARE
-- 定义记录类型
TYPE emp_rec_type IS RECORD
(
empno emp.empno%TYPE,
ename emp.ename%TYPE,
hiredate emp.hiredate%TYPE
);
-- 定义基于记录的嵌套表
TYPE nested_emp_type IS TABLE OF emp_rec_type;
-- 声明变量
emp_tab nested_emp_type;
BEGIN
-- 使用BULK COLLECT将所得的结果集一次性绑定到记录变量emp_tab中
SELECT empno, ename, hiredate
BULK COLLECT INTO emp_tab
FROM emp;
FOR i IN emp_tab.FIRST .. emp_tab.LAST LOOP
DBMS_OUTPUT.PUT_LINE('当前记录: '
||emp_tab(i).empno||chr(9)
||emp_tab(i).ename||chr(9)
||emp_tab(i).hiredate);
END LOOP;
END;
/
说明:使用BULK COLLECT一次即可提取所有行并绑定到记录变量,这就是所谓的批量绑定。
5.2 在FETCH INTO中使用BULK COLLECT
在游标中可以使用BLUK COLLECT一次取出一个数据集合,比用游标单条取数据效率高,尤其是在网络不大好的情况下。
语法:
FETCH ... BULK COLLECT INTO ...[LIMIT row_number];
在使用BULK COLLECT子句时,对于集合类型会自动对其进行初始化以及扩展。因此如果使用BULK COLLECT子句操作集合,则无需对集合进行初始化以及扩展。由于BULK COLLECT的批量特性,如果数据量较大,而集合在此时又自动扩展,为避免过大的数据集造成性能下降,因此可以使用LIMIT子句来限制一次提取的数据量。LIMIT子句只允许出现在FETCH操作语句的批量中。
示例:
DECLARE
CURSOR emp_cur IS
SELECT empno, ename, hiredate FROM emp;
TYPE emp_rec_type IS RECORD
(
empno emp.empno%TYPE,
ename emp.ename%TYPE ,
hiredate emp.hiredate%TYPE
);
-- 定义基于记录的嵌套表
TYPE nested_emp_type IS TABLE OF emp_rec_type;
-- 声明集合变量
emp_tab nested_emp_type;
-- 定义了一个变量来作为limit的值
v_limit PLS_INTEGER := 5;
-- 定义变量来记录FETCH次数
v_counter PLS_INTEGER := 0;
BEGIN
OPEN emp_cur;
LOOP
-- fetch时使用了BULK COLLECT子句
FETCH emp_cur
BULK COLLECT INTO emp_tab
LIMIT v_limit; -- 使用limit子句限制提取数据量
EXIT WHEN emp_tab.COUNT = 0; -- 注意此时游标退出使用了emp_tab.COUNT,而不是emp_cur%notfound
v_counter := v_counter + 1; -- 记录使用LIMIT之后fetch的次数
FOR i IN emp_tab.FIRST .. emp_tab.LAST
LOOP
DBMS_OUTPUT.PUT_LINE( '当前记录: '
||emp_tab(i).empno||CHR(9)
||emp_tab(i).ename||CHR(9)
||emp_tab(i).hiredate);
END LOOP;
END LOOP;
CLOSE emp_cur;
DBMS_OUTPUT.put_line( '总共获取次数为:' || v_counter );
END;
/
5.3 在RETURNING INTO中使用BULK COLLECT
BULK COLLECT除了与SELECT,FETCH进行批量绑定之外,还可以与INSERT,DELETE,UPDATE语句结合使用。当与这几个DML语句结合时,需要使用RETURNING子句来实现批量绑定。
示例:
DECLARE
TYPE emp_rec_type IS RECORD
(
empno emp.empno%TYPE,
ename emp.ename%TYPE,
hiredate emp.hiredate%TYPE
);
TYPE nested_emp_type IS TABLE OF emp_rec_type;
emp_tab nested_emp_type;
BEGIN
DELETE FROM emp WHERE deptno = 20
RETURNING empno, ename, hiredate -- 使用returning 返回这几个列
BULK COLLECT INTO emp_tab; -- 将返回的列的数据批量插入到集合变量
DBMS_OUTPUT.put_line( '删除 ' || SQL%ROWCOUNT || ' 行记录' );
COMMIT;
IF emp_tab.COUNT > 0 THEN -- 当集合变量不为空时,输出所有被删除的元素
FOR i IN emp_tab.FIRST .. emp_tab.LAST LOOP
DBMS_OUTPUT.PUT_LINE('当前记录:'
|| emp_tab( i ).empno || CHR( 9 )
|| emp_tab( i ).ename || CHR( 9 )
|| emp_tab( i ).hiredate
|| ' 已被删除' );
END LOOP;
END IF;
END;
/
6. BULK COLLECT的注意事项
- BULK COLLECT INTO 的目标对象必须是集合类型。
- 只能在服务器端的程序中使用BULK COLLECT,如果在客户端使用,就会产生一个不支持这个特性的错误。
- 不能对使用字符串类型作键的关联数组使用BULK COLLECT子句。
- 复合目标(如对象类型)不能在RETURNING INTO子句中使用。
- 如果有多个隐式的数据类型转换的情况存在,多重复合目标就不能在BULK COLLECT INTO子句中使用。
- 如果有一个隐式的数据类型转换,复合目标的集合(如对象类型集合)就不能用于BULK COLLECTINTO子句中。
7. FORALL与BULK COLLECT综合运用
FORALL与BULK COLLECT是实现批量SQL的两个重要方式,我们可以将其结合使用以提高性能。
示例:
-- 创建表tb_emp
CREATE TABLE tb_emp AS
SELECT empno, ename, hiredate
FROM emp
WHERE 1 = 0;
DECLARE
-- 声明游标
CURSOR emp_cur IS
SELECT empno, ename, hiredate FROM emp;
-- 基于游标的嵌套表类型
TYPE nested_emp_type IS TABLE OF emp_cur%ROWTYPE;
-- 声明变量
emp_tab nested_emp_type;
BEGIN
SELECT empno, ename, hiredate
BULK COLLECT INTO emp_tab
FROM emp
WHERE sal > 1000;
-- 使用FORALL语句将变量中的数据插入到表tb_emp
FORALL i IN 1 .. emp_tab.COUNT
INSERT INTO (SELECT empno, ename, hiredate FROM tb_emp)
VALUES emp_tab( i );
COMMIT;
DBMS_OUTPUT.put_line('总共向 tb_emp 表中插入记录数: ' || emp_tab.COUNT);
END;
/
1. 什么是事务
在数据库中事务是工作的逻辑单元,一个事务是由一个或多个完成一组的相关行为的SQL语句组成,通过事务机制确保这一组SQL语句所作的操作要么都成功执行,完成整个工作单元操作,要么一个也不执行。
如:网上转帐就是典型的要用事务来处理,用以保证数据的一致性。
2. 事务特性
SQL92标准定义了数据库事务的四个特点:
- 原子性(Atomicity):一个事务里面所有包含的SQL语句是一个执行整体,不可分割,要么都做,要么都不做。
- 一致性(Consistency):事务开始时,数据库中的数据是一致的,事务结束时,数据库的数据也应该是一致的。
- 隔离性(Isolation):是指数据库允许多个并发事务同时对其中的数据进行读写和修改的能力,隔离性可以防止事务的并发执行时,由于他们的操作命令交叉执行而导致的数据不一致状态。
- 持久性 (Durability) : 是指当事务结束后,它对数据库中的影响是永久的,即便系统遇到故障的情况下,数据也不会丢失。
- 一组SQL语句操作要成为事务,数据库管理系统必须保证这组操作的原子性(Atomicity)、一致性(consistency)、隔离性(Isolation)和持久性(Durability),这就是ACID特性。
转载自:https://www.cnblogs.com/hellokitty1/p/4584333.html
