





石原子实时数仓系统(简称 StoneData)是杭州石原子科技有限公司(StoneAtom)自主设计、研发的企业级实时数据仓库产品,支持对海量数据进行批量处理和实时分析,可实现对千亿级数据的秒级到毫秒级多维分析透视和业务探索。
随着 AGI 的进一步发展潮流,向量数据库的重要性愈发凸显,其中,向量检索作为向量数据库的底层技术要求之一,也被越来越多的大数据产品接入,StoneData 也实现了向量计算与实时数仓的融合,本文主要分享我们在非结构化分析场景下融合向量检索的思考与实践(文末有相关案例视频演示~)。

实现原理
StoneData 旨在帮助用户更灵活方便的使用向量检索的能力,实现对非结构化数据的近似检索分析。其实现原理是通过AI算法提取非结构化数据的特征,然后利用特征向量唯一标识非结构化数据,向量间的距离用于衡量非结构化数据之间的相似度。通过SIMD指令加速、高效索引算法、混合检索CBO策略以及低成本存储技术,帮助您实现高性能、低成本的非结构化数据近似查询和分析。

典型应用场景
图像相似性搜索:通过图片检索近似图片; 视频相似性搜索:通过输入视频中的截图查找目标视频; 音频相似性搜索:快速检索大量音频数据,如语音、音乐、音效、动物/自然音,快速检索相似声音; 推荐系统:根据用户画像的信息找出与之匹配的目标产品; 问答系统:交互式数字问答聊天机器人,基于知识库自动回答客户的问题; 文本搜索引擎:通过将关键字与文本数据库进行比较,帮助用户找到他们正在寻找的信息。

通过 StoneData 产品搭建向量分析的典型架构如下:
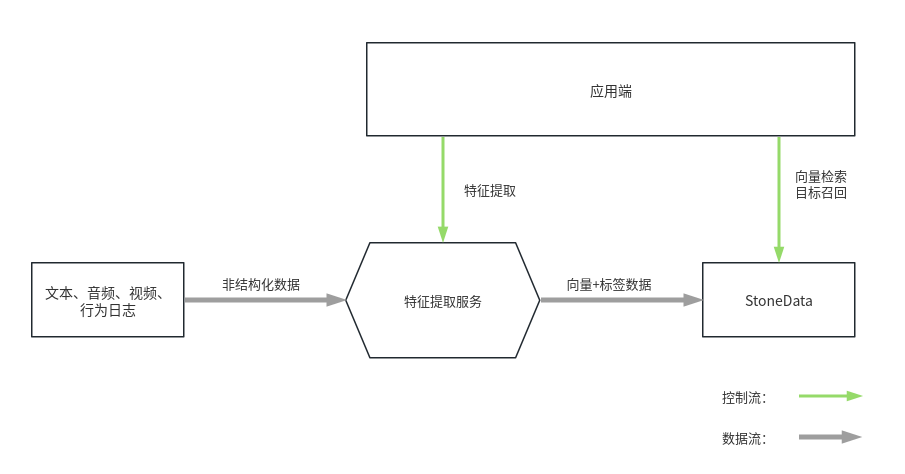

架构简单、功能强大,使用 StoneData 即可完成关系型-非关系型数据的融合分析,无需引入额外的技术组件。 例如,可以检索与输入图片中的连衣裙相似度最高、价格在100元到200元之间且上架时间在最近1个月以内的产品。 支持标准SQL,兼容MySQL方言,简化开发流程,用户使用简单的 SQL 指令即可完成向量数据检索; 支持数据实时更新,传统的向量分析系统中数据只能按照T+1更新,不支持数据实时写入。StoneData 支持数据实时更新和查询; 高可用与高扩展性,支持3副本存储、支持高可用集群,即便少数节点出现故障也不会收到影响; 高性能,支持 HNSW 索引算法,实现毫秒级向量信息检索和10k+的QPS。

支持的度量和索引
欧氏距离(L2):该指标通常用于计算机视觉领域(CV) 内积(IP):该指标通常用于自然语言处理领域(NLP) 余弦夹角(COSINE):该指标适用与 CV/NLP/LLM 等
HNSW:HNSW是一种基于图形的索引,最适合于对搜索效率有很高需求的场景 FLAT:FLAT最适合于在小规模,百万级数据集上寻求完全准确和精确的搜索结果的场景
 案例介绍(一)
案例介绍(一)
使用 StoneData 实现图片检索引擎-以图搜图
本章主要介绍如何使用 StoneData 构建图片检索服务。依赖的第三方软件包括:
YOLOv3
ResNet-50
ToWhee
本演示使用图像特征提取模型 ResNet50 和 StoneData 构建一个可以执行反向图像搜索的系统。
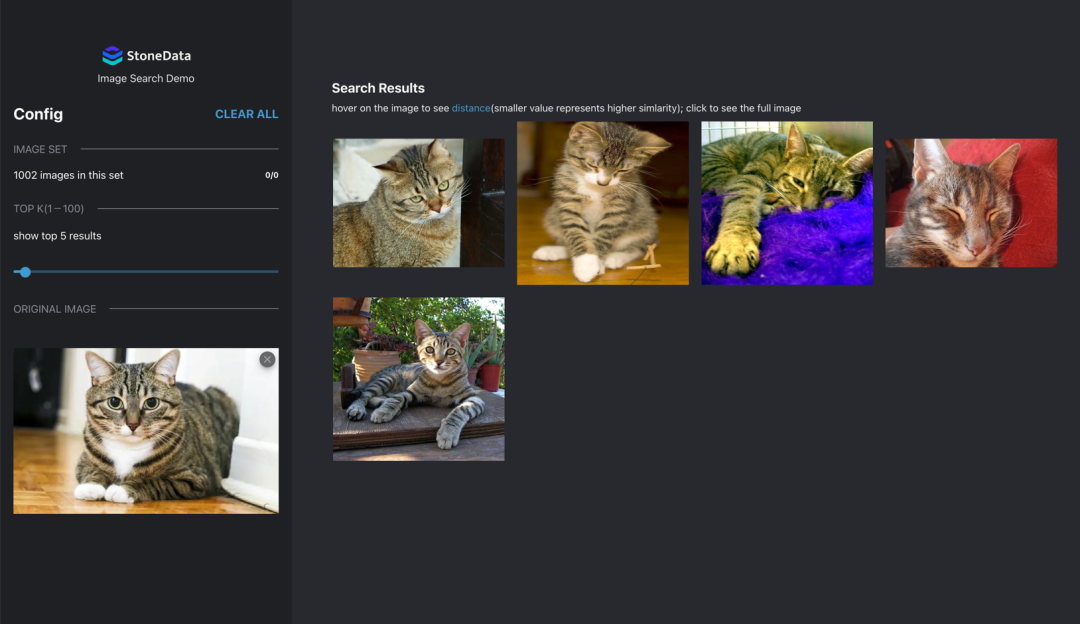
数据源及初始化配置
图片数据集大小: ~ 2 GB.下载地址:
https://drive.google.com/file/d/1n_370-5Stk4t0uDV1QqvYkcvyV8rbw0O/view?usp=sharing
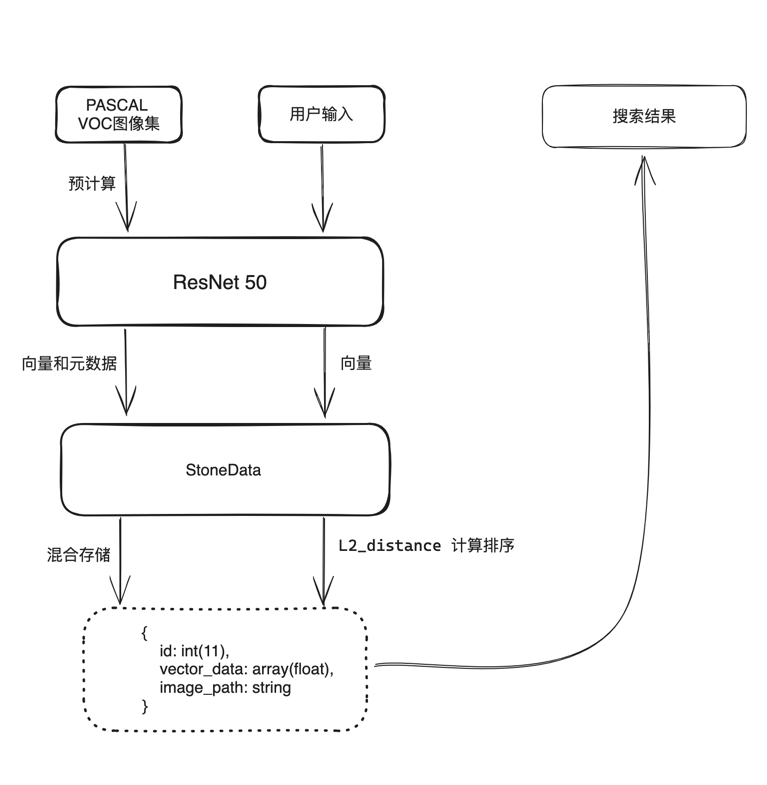
使用 ResNet-50 进行图像特征提取,然后将向量与图片地址存储在 StoneData 中。
@app.post('/img/load')async def load_images(item: Item):# Insert all the image under the file path to stonedatatry:total_num = do_load(item.Table, item.File, MODEL, StoneData_CLI)LOGGER.info(f"Successfully loaded data, total count: {total_num}")return "Successfully loaded data!"except Exception as e:LOGGER.error(e)return {'status': False, 'msg': e}, 400# Import vectors to StoneDatadef do_load( image_dir: str, model: Resnet50, stonedata_client: StoneDataHelper):stonedata_client.stoneatom_create_table()vectors, names = extract_features(image_dir, model)lens = 0for vector, name in zip(vectors, names):stonedata_client.stoneatom_insert_table( vector,bytes.decode(name))lens = lens + 1return len(lens)# Get the vector of imagesdef extract_features(img_dir, model):try:cache = Cache('./tmp')feats = []names = []img_list = get_imgs(img_dir)total = len(img_list)cache['total'] = totalfor i, img_path in enumerate(img_list):try:norm_feat = model.resnet50_extract_feat(img_path)feats.append(norm_feat)names.append(img_path.encode())cache['current'] = i + 1LOGGER.info(f"Extracting feature from image No. {i + 1} , {total} images in total")except Exception as e:LOGGER.error(f"Error with extracting feature from image {e}")continuereturn feats, namesexcept Exception as e:LOGGER.error(f"Error with extracting feature from image {e}")sys.exit(1)
每当您上传新图像到图像搜索服务时,它将被转换为新向量,并与以前存储在 StoneData 中的向量进行比较。 然后, StoneData 返回最相似向量的ID,您可以在文件系统中查询相应的图像。以下是演示代码:
@app.post('/img/search')async def search_images(image: UploadFile = File(...), topk: int = Form(TOP_K)):# Search the upload image in StoneDatatry:# Save the upload image to server.content = await image.read()img_path = os.path.join(UPLOAD_PATH, image.filename)with open(img_path, "wb+") as f:f.write(content)items = do_search(img_path, topk, MODEL, StoneData_CLI)paths = [x[1] for x in items]distances = [x[2] for x in items]res = dict(zip(paths, distances))res_items = sorted(res.items(), key=lambda item: item[1])LOGGER.info("Successfully searched similar images!")return res_itemsexcept Exception as e:LOGGER.error(e)return {'status': False, 'msg': e}, 400def do_search(img_path: str, top_k: int, model: Resnet50, stonedata_cli: StoneDataHelper):try:# verctor for featfeat = model.resnet50_extract_feat(img_path)items = stonedata_cli.search_vectors(feat, top_k)return itemsexcept Exception as e:LOGGER.error(f"Error with search : {e}")sys.exit(1)def search_vectors(self, vectors, top_k):st = "[" + ','.join(str(x) for x in vectors) + "]"try:sql = "select id ,image_path, distance from (select id, l2_distance(data, '"+ st +"') as distance, image_path from "+ DEFAULT_TABLE +") order by distance limit "+ str(top_k)self.cursor.execute(sql)results = self.cursor.fetchall()LOGGER.debug(f"Successfully search in StoneData: {results}")return resultsexcept Exception as e:LOGGER.error(f"Failed to search StoneData in Milvus: {e}")sys.exit(1)

案例介绍(二)
使用 StoneData 实现文字检索引擎 - 知识库
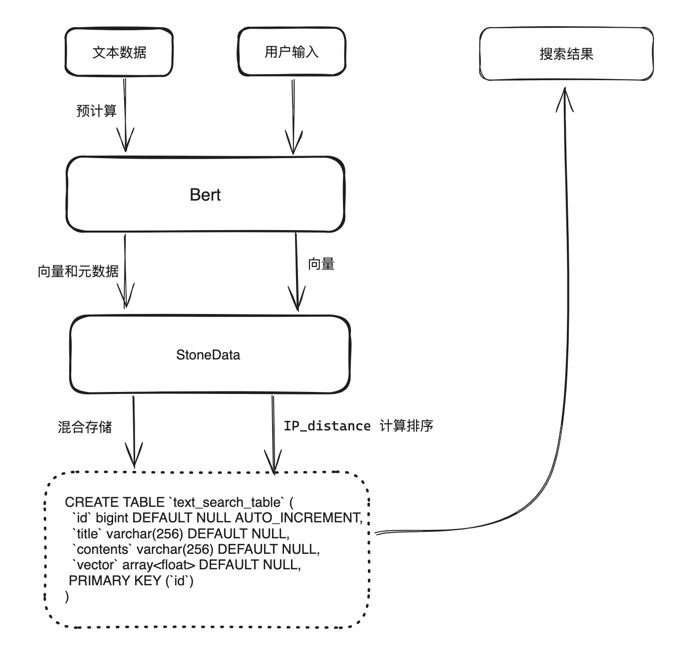
文本搜索是指根据文本的内容(例如关键词、语义等)来搜索的服务,是搜索引擎非常重要的一部分。 本示例使用 Stonedata 和 Bert 构建文本搜索引擎,使用 Bert 将文本转换为向量并存储在 Stonedata 中,然后结合搜索与输入文本相似的文本。
系统架构图
数据源及初始化配置
# 模型初始化def __init__(self):if not os.path.exists(MODEL_PATH):os.makedirs(MODEL_PATH)if not os.path.exists("./paraphrase-mpnet-base-v2.zip"):url = 'https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/paraphrase-mpnet-base-v2.zip'gdown.download(url)with zipfile.ZipFile('paraphrase-mpnet-base-v2.zip', 'r') as zip_ref:zip_ref.extractall(MODEL_PATH)self.model = SentenceTransformer(MODEL_PATH)def sentence_encode(self, data):embedding = self.model.encode(data)sentence_embeddings = normalize(embedding)return sentence_embeddings.tolist()# 上传 example.csv ,预处理 数据@app.post('/load')async def load_text(file: UploadFile = File(...), table_name: str = None):try:text = await file.read()fname = file.filenamedirs = "data"if not os.path.exists(dirs):os.makedirs(dirs)fname_path = os.path.join(os.getcwd(), os.path.join(dirs, fname))with open(fname_path, 'wb') as f:f.write(text)except Exception :return {'status': False, 'msg': 'Failed to load data.'}try:total_num = do_load(table_name, fname_path,MODEL ,STONEDATA_CLI)LOGGER.info(f"Successfully loaded data, total count: {total_num}")return "Successfully loaded data!"except Exception as e:LOGGER.error(e)return {'status': False, 'msg': e}, 400def do_load(table_name, file_dir, model, STONEDATA_CLI):if not table_name:table_name = DEFAULT_TABLESTONEDATA_CLI.create_table()title_data, text_data, sentence_embeddings = extract_features(file_dir, model)lens = 0for title, text, vector in zip(title_data, text_data, sentence_embeddings):st = "[" + ','.join(str(x) for x in vector) + "]"sql = "insert into " + table_name + " (title,contents,vector) values ('" + title + "','" + text + "','"+ st +"');"try:STONEDATA_CLI.cursor.execute(sql)STONEDATA_CLI.conn.commit()LOGGER.debug(f"Insert vectors to StoneData in table: {table_name} with {len(vector)} rows")except Exception as e:LOGGER.error(f"StoneData ERROR: {e} with sql: {sql}")sys.exit(1)lens = lens + 1return len(lens)
每当搜索文字时,它将被转换为新向量,并与以前存储在 StoneData 中的向量进行比较。然后,StoneData 返回最相似向量的ID并返回内容。
@app.get('/search')async def do_search_api(query_sentence: str = None):try:items = STONEDATA_CLI.search_vectors(query_sentence,MODEL, STONEDATA_CLI)res=[]for p, d, in items:dicts = {'title': p, 'content':d}res+=[dicts]LOGGER.info("Successfully searched similar text!")return resexcept Exception as e:LOGGER.error(e)return {'status': False, 'msg': e}, 400def search_vectors(self,query_sentence,MODEL, STONEDATA_CLI,):# 转化为新向量vectors = MODEL.sentence_encode([query_sentence])st = ','.join(str(x) for x in vectors)LOGGER.debug(f"Successfully search in sql: {st}")try:sql = "select title, contents from (select id, l2_distance(vector, '"+ st +"') as distance, title, contents from "+ DEFAULT_TABLE +") order by distance limit 10"LOGGER.debug(f"Successfully search in sql: {sql}")STONEDATA_CLI.cursor.execute(sql)results = STONEDATA_CLI.cursor.fetchall()LOGGER.debug(f"Successfully search in StoneData: {results}")return resultsexcept Exception as e:LOGGER.error(f"Failed to search StoneData in StoneData: {e}")sys.exit(1)


该产品对标 Oracle HeatWave,使用 MySQL 的用户,通过 StoneDB 可以实现 TP+AP 混合负载,分析性能显著提升 10-100 倍以上,不需要进行数据迁移,也无需与其他 AP 系统集成,弥补 MySQL 分析领域的空白,通过 AP 增强到自主可控的 TP,瞄准大量 MySQL 信创升级 + 替代市场。

公司成立至今,已积累了上千位用户,种子客户达 300 多家,取得 30+ 项软件著作权,成功申请并获准通过了 16+ 项技术专利,分别获评杭州市创新型中小企业、浙江省科技型中小企业、国家级科技型中小企业,产品通过公安部三所自主原创性认证,全面满足信创和等保要求。

