






一、什么是动态过滤
基础知识
在数据库使用中,表连接是必须要掌握的一个概念,绝大多数用户可以只知道等值连接,考虑到各种不同的需求,数据库中的连接有以下几种类型:
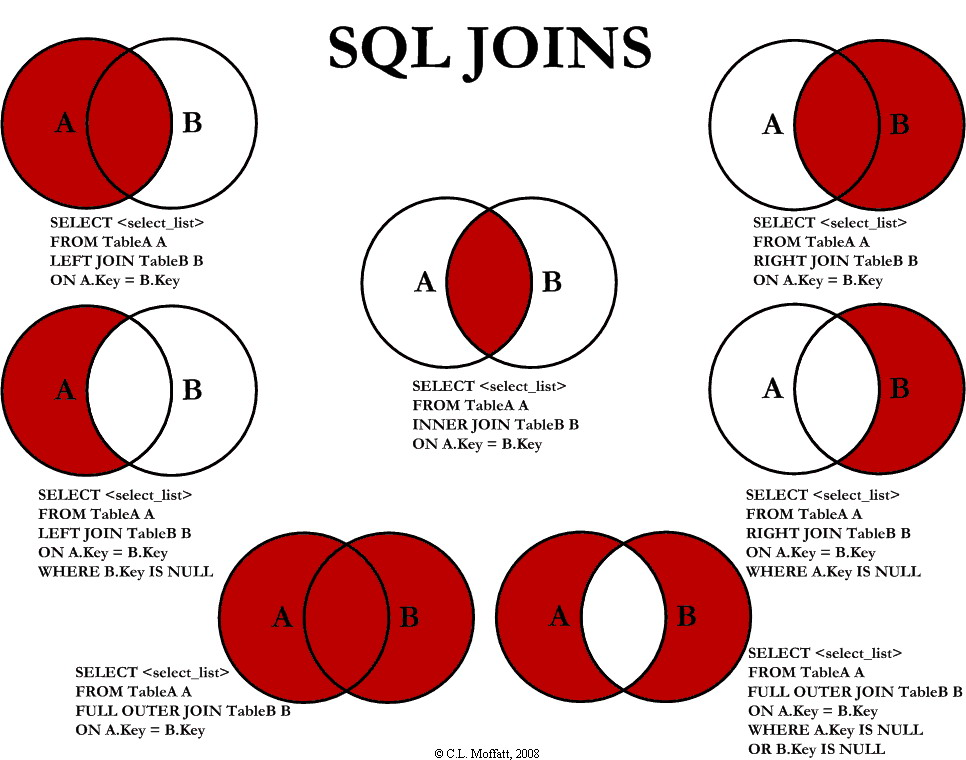
(一)内连接(Inner Join)
内连接:只返回两个表中连接字段值相等的行。
自然连接:只考虑属性相同的元组对
等值连接:给定条件进行查询
不允许 NULL 值
(二)外连接(Outer Join)
左连接:以左表为基准,返回左表中所有行和右表中与连接字段值相等的行,没有对应的部分补 NULL
右连接:以右表为基准,返回右表中所有行和左表中与连接字段值相等的行。无对应的部分补 NULL
全外连接(Full Outer Join):返回左右表中所有行和连接字段值不匹配的行,如果连接字段匹配,则显示相应的值,但是去除两表的重复数据
(三)交叉连接(Cross Join)
交叉连接:返回两表的笛卡尔积(对于所含数据分别为m、n的表,返回m*n的结果)。
不允许 NULL 值
各种连接的数据包含范围如下,红色代表包含的数据
用户提交 Table Join 指令后, 数据库内核会做什么呢?
Join 常见的算法有 NestLoopJoin (嵌套循环)、HashJoin 和 SortMergeJoin。由于我们采用的是 CBO 的优化器,我们会对表数据进行采样生成统计信息,优化器会进行 JoinReorder 优化,下文默认右表为小表,左表为大表。
NestLoopJoin 是以右表为驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到左表中查询数据,然后合并结果。NestLoopJoin 是一种通用的 Join 算法,可以覆盖大多数的场景,但其 Join 的效率较低,算法复杂度为 O(a*b),通常作为保底方案使用。
HashJoin 是通过对右表建立 hash 表,以 JoinKey 为 Hash 表的 Key 将对应的 Tuple 数据存储起来。再以左表为探测表,从左表中拉取数据,每拉取一批数据就从 Hash 表中查找,找到之后就作为结果输出。HashJoin 通常用于等值连接,不可用于非等值连接,其 Join 的效率较高,算法复杂度为 O(a+b) ,是较为常用的 Join 算法。但是由于右表需要构建 Hash 表,同时需要全部数据加载至内存,如果右表较大的话内存开销较高。
SortMergeJoin 是对左表和右表进行排序,再通过归并排序的方式进行 Join。优点是 Join 的结果是有序的适合应用于结果需要排序的场景。如果扫描的数据是按 JoinKey 进行排序的,则无需排序操作,这种情况下开销较低。SortMergeJoin 无需像 HashJoin 一样先加载右表的全部数据到内存,内存占用较小,稳定性较高,但是排序时会有计算开销。
动态过滤
为便于理解,下文中我们用左右表来统一表述, 左表是驱动表, 右表是构建表。动态过滤 (Dynamic Filter) 又称为运行时过滤 (Runtime Filter) ,其目的在于通过在 Join 的左表提前过滤掉那些不会命中 Join 的输入数据来大幅减少 Join 中的数据传输和计算,从而减少整体的执行时间。简单来说就是利用数据量小的右表的 Join keys 对数据量大的左表 Join keys 构造过滤器,来减少大表的数据读取。
其中 InnerJoin, RightJoin 支持动态过滤,因为左连接和全连接要求返回左表的所有行, 所以 LeftJoin, FullJoin 不支持动态过滤。
二、动态过滤的执行过程
首先我们构建一个概念模型,给大家简要介绍一下,动态过滤的执行过程,经过对比,相信大家对动态过滤会有一个更加清晰的认识。
未开启动态过滤时的执行过程
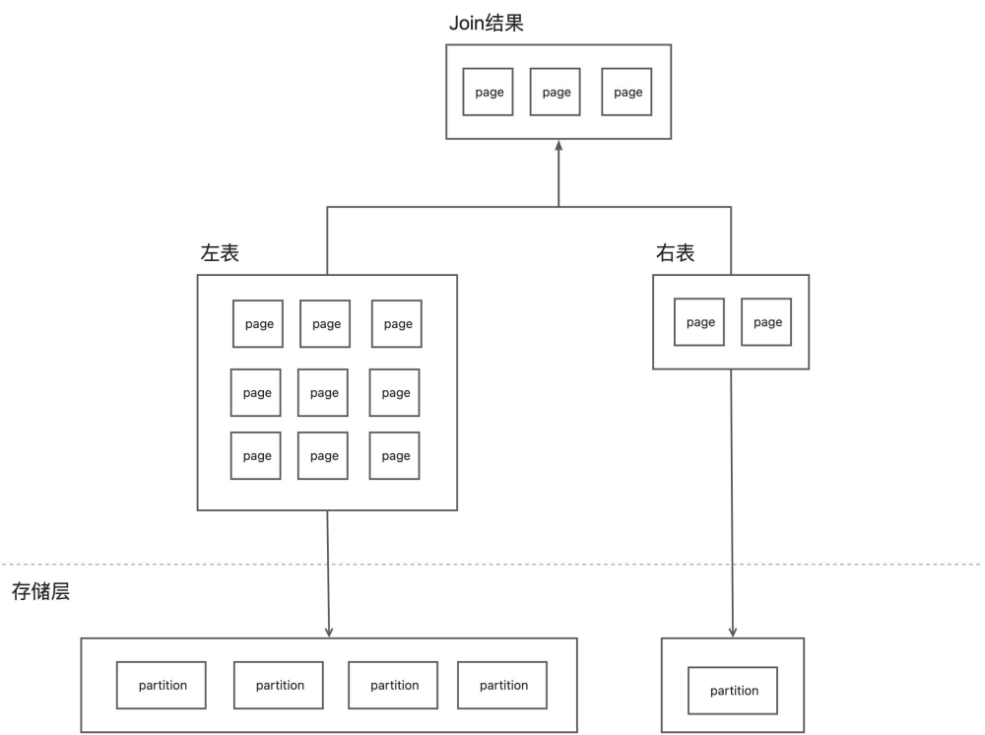
未开启动态过滤时的 SQL 执行过程是这样的:
首先由于我们的优化器支持谓词下推,右表的 Where 条件会下推至存储层,而且存储层支持索引,会使用 Where 条件先查询索引,对于命中索引的数据,再回表查询,返回过滤后的数据。
而左表是大表,可能从存储层返回大量数据, 这里有很大的 IO 开销, 而且这些数据会在后续的算子中参与计算,会产生内存和计算开销,但是这些数据并非全部应用于 Join ,可能会有大量的数据会在 Join 时过滤掉,这将带来大量的无用开销。
开启动态过滤后的执行过程
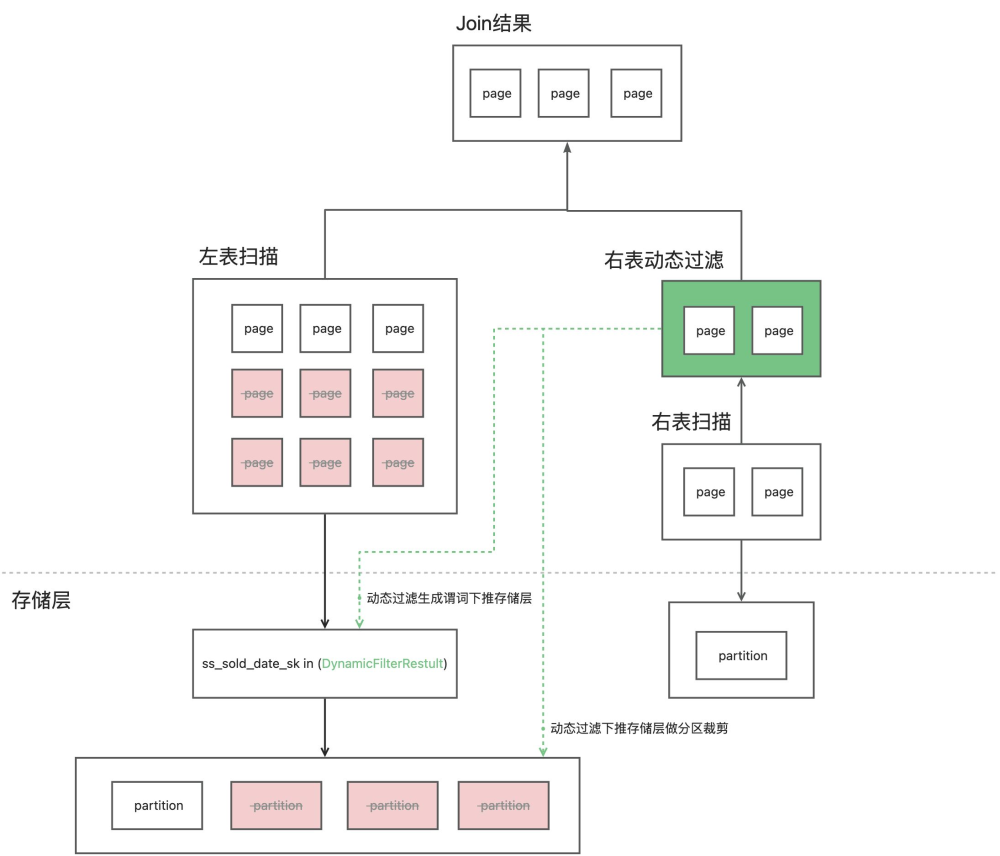
而在开启动态过滤时之后 SQL 执行过程是这样的, 首先右表会根据 Where 条件先扫描索引,再将命中索引的数据从存储层扫描贴出来,返回右表的结果集。
开启动态过滤时,会在右表加入动态过滤算子,收集动态过滤信息,具体的动态过滤信息类型,在下文中会有详细说明。
再根据不同的分布式 Join 类型,分布式动态过滤数据会在多个 Worker 中进行收集与合并,也会发送到多个 Worker 中,而本地动态过滤可以本地直接应用,最终左表的扫描算子都会收到动态过滤信息,分别做动态过滤谓词下推和分区剪裁。
动态过滤信息会下推到存储层,存储层每个分区都有统计信息,每个分区都有 MinMax 数据区间信息,可以通过动态过滤中的 MinMax 值过滤掉不需要扫描的分区。然后再从需要扫描的分区中进行索引扫描,动态过滤收集的信息可以转化为 col1 in (1,2,...,10) 或者 col1 > 1 and col1 < 10 的谓词,这样只会扫描出少量的分区和索引,再回表查询其他列的数据,这个过程效率非常高。
经过这两步工作之后, 左表就不需要从存储层返回大量无用的数据了,而是只返回可能命中 Join 的数据。这样依赖存储层的IO效率得到巨大的提升,同时也节省了后续算子的内存和计算开销。
三 、在分布式 Join 时, 如何进行动态过滤?
在 MPP 架构的分析型数据库中。需要利用分布式并行计算的能力进行 Join ,有三种常见的分布式 Join 方式, 我们先简要介绍一下这三种 Join:
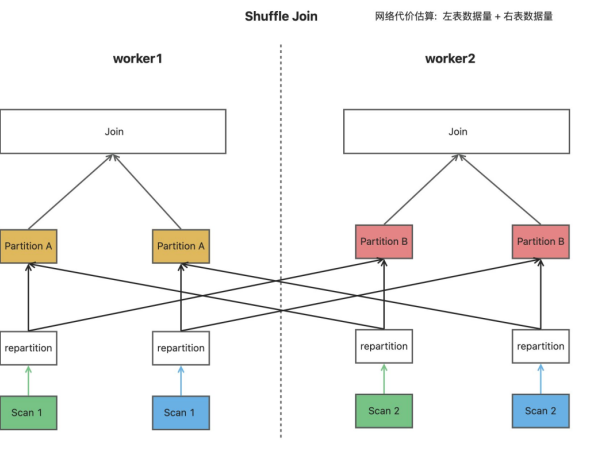
Shuffle Join: 适用于大表与大表的 Join 方式,每个 Worker 会按各自的分区扫描两张表的数据,然后再按 Join Key 进行 Hash 重新 Shuffle 到所有的 Worker 上,每个 Worker 所获取的两表的 Join Key 都是对应的,可以直接进行本地 Join, 在上层会有算子将所有 Worker 的 Join 结果进行汇总。这种 Join 的网络代价是最大的,可以估算为左表的数据量+右表的数据量, 所以如果有可能, 我们还是会建议采用下面的 Join 方式,来降低网络开销。
Broadcast Join:适用于右表是小表的场景,在这种情况下,我们会将右表复制广播到所有 Worker 上,所有 Worker 都会获得右表的全量数据,对右表建立 hash 表, 左表依次从 Hash 表中查找数据,如果命中再输出 Join 结果, 在上层会有算子将所有的 Worker 的 Join 结果进行汇总。Broadcast Join 的网络代价通常小于 Shuffle Join 的网络代价,可以估算为右表数据*节点数-1,但在右表较大时网络代价和构建 hash 表的代价会变高,甚至会超过 Shuffle Join。
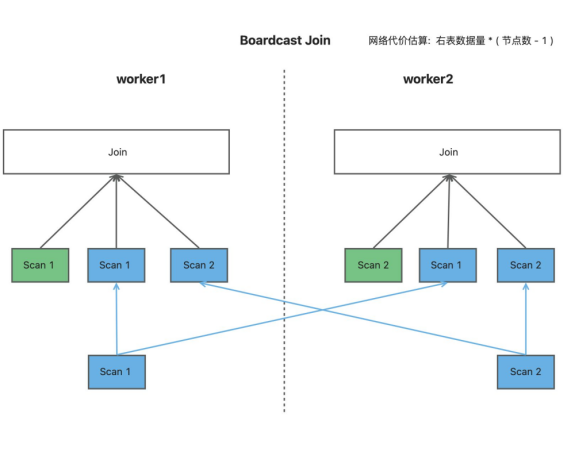
Colocate Join:这是最理想的一种 Join 方式,在 Shuffle Join 中对于两张表都按 Join Key 进行分布的情况下, 可以在本地直接进行 Join, 无需网络发送; 在 Broadcast Join 中, 右表本身就已经是复制表的情况, 也可以在本地直接进行 Join。由于 Colocate Join 是按 JoinKey 进行分布的,无需进行重分布,所以是没有网络代价的。
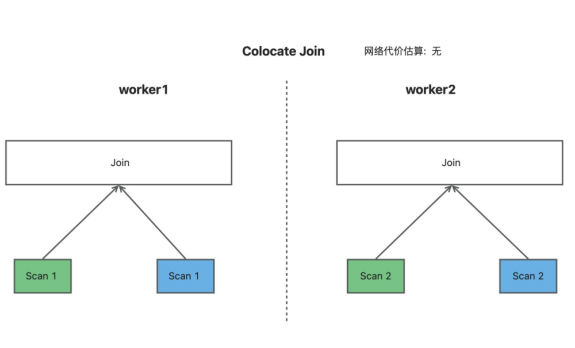
上面是三种分布式 Join 的方式,这三种方式的共同点是右表是小表,所以我们是在右表建立动态过滤,而不是在左表。而且由于两表有执行顺序的先后关系,需要右表先扫描完成并且收集动态过滤,左表在收到动态过滤后才能开始扫描,所以无法也无法使用左表对右表进行过滤。
由于开启动态过滤时左表和右表是串行扫描,在 ShffuleJoin 时如果左表扫描速度较快,而动态过滤的收集速度较慢,可能起不到过滤效果,但是这种情况在常见的分析型数据库的查询场景下并不常见。
下面我们进一步深入了解一下在这三种分布式 Join 下, 动态过滤的工作细节:
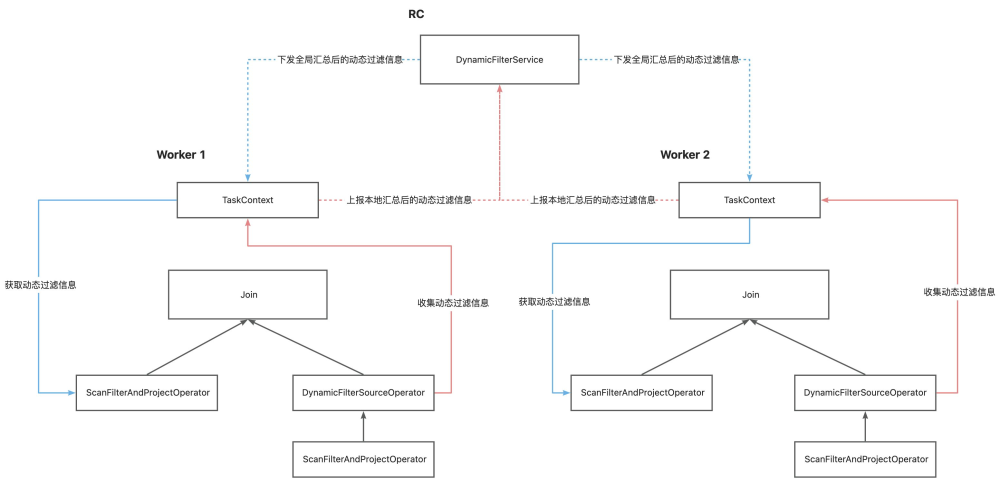
Shuffle Join 和 Broadcast Join
在下图中我们可以看到,每个 Worker 节点都会收集动态过滤信息,在收集时数据是从分区文件中产生的,这样本地会收集到多个分区的动态过滤数据并存放在TaskContext (任务上下文),每个 Worker 会把当前 Worker 中所有分区的数据在本节点内进行合并,合并完成后会生成本地最终的动态过滤信息。
每个 Worker 会把本地合并后的的动态过滤信息上传到 RC 节点,RC 节点上会收到所有 Worker 的动态过滤信息,RC 节点需要合并所有 Worker 的动态过滤信息生成最新版本的动态过滤信息。
RC 会将合并后的最新版本的动态过滤信息在更新任务状态时发送给 Worker 节点,Worker 收到动态过滤信息后会更新本地的最新版本的动态过滤信息并存放在 TaskContext 中。
当左表需要进行扫描时,会检查当前的动态过滤是否收集完成,如果没有收集完成,需要进行等待,如果已经收集完成,会从 TaskContext 中取出最新版本的动态过滤信息,并将动态过滤信息转换成谓词进行索引扫描。
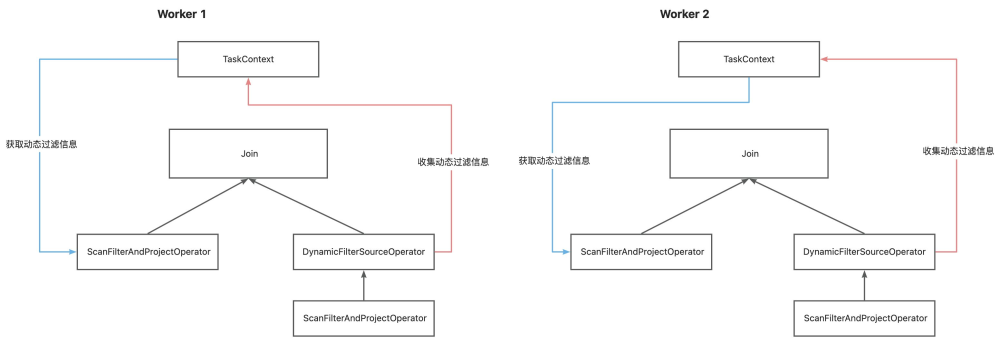
Colocate Join
由于 Colocate Join 时数据已经按 Join Key 进行分布,在当前 Worker 中按 JoinKey 收集的动态过滤信息,不会存在于其他 Worker,所以无需使用分布式动态过滤,不需要在集群中进行汇总、合并和分发。
右表也是从各个分区中扫描数据并生成动态过滤,然后动态过滤信息合并后存入 TaskContext,左表在扫描时从 TaskContext 中取出汇总后的动态过滤信息即可。
四、动态过滤数据源
根据前面的介绍, 我们了解的动态过滤的优点,和动态过滤的基本流程。下面我们进一步分析, 在右表收集动态过滤信息的具体类型:
HashSet
如果右表的 Where 条件过滤效率高,最终扫描的行数较少时,我们会使用 HashSet 的方式收集动态过滤信息, HashSet 的动态过滤信息在下推存储层时,会转换成In谓词的形式,如: col1 in (1,2,3,...,10)。

HashSet 是将右表的数据构建成哈希表, 然后通过 in 谓词的方式下推给左表的存储层。HashSet 的优点就是效果过滤效果明显。HashSet 的缺点内存占用和网络传输的代价比较高, in 谓词走索引的代价也比较高, 右表超过一定数据量的时候就失效了。
Min/Max
当右表数据量达到一定的阈值,或者右表的 Where 条件过滤效果不好, 这个时候再构造 Hash Set 的话, 内存占用和网络传输的代价都会过高, 这个时候 我们会考虑退化的方式, 退而求其次,仅仅返回一个数据的一个范围,这样也能起到一定的减少IO的效果。Min/Max 的动态过滤信息在下推到存储层时,会转换为范围谓词的形式,如:col1 > 1 and col1 < 10。
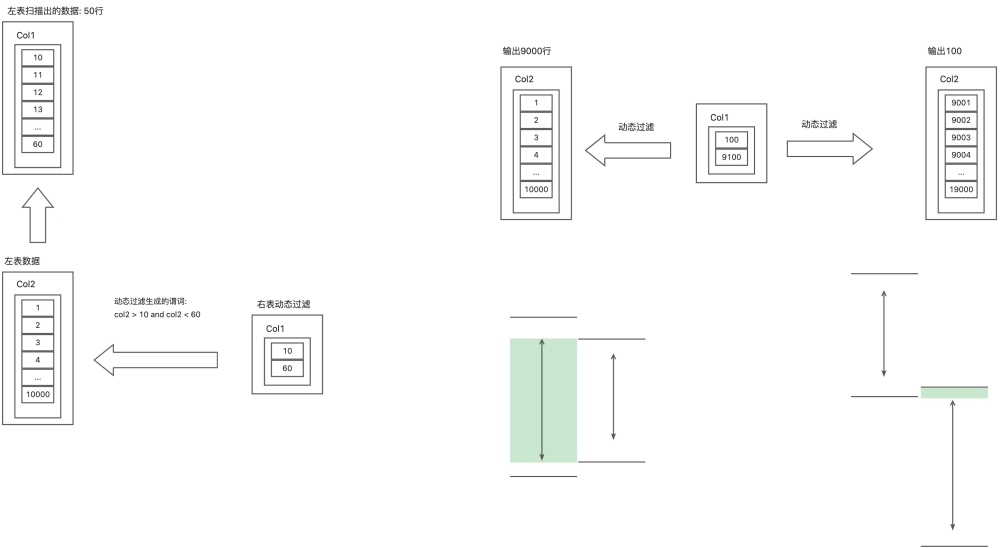
Min/Max 就是个 Range 范围,通过右表数据确定 Range 范围之后,下推给左表的存储层。Min/Max 的优点是开销比较小。它的缺点就是对数值列还有比较好的效果,但对于非数值列,效果不明显。当左表和右表的 JoinKey 的数据范围比较重合时,过滤效果较差;当左表和右表的 JoinKey 的数据范围重合较小时,过滤效果好。
上图中只是一个简单的示例,实际的动态过滤的 Min/Max 信息并非只有一组,而是包含多组的,但是原理与上图类似,本文不过多讲解。
五、不开启动态过滤的情况
在某些特定情况下, 我们就不开启动态过滤,如 LeftJoin, FullJoin 之类返回左表 JoinKey 全量数据的 table Join。由于 JoinKey 的最终集合中包含左表的全部数据,而 Join 时又是通过右表对左表进行过滤,所以 LeftJoin 与 FullJoin 是起不到过滤效果的,就不需要开启动态过滤。
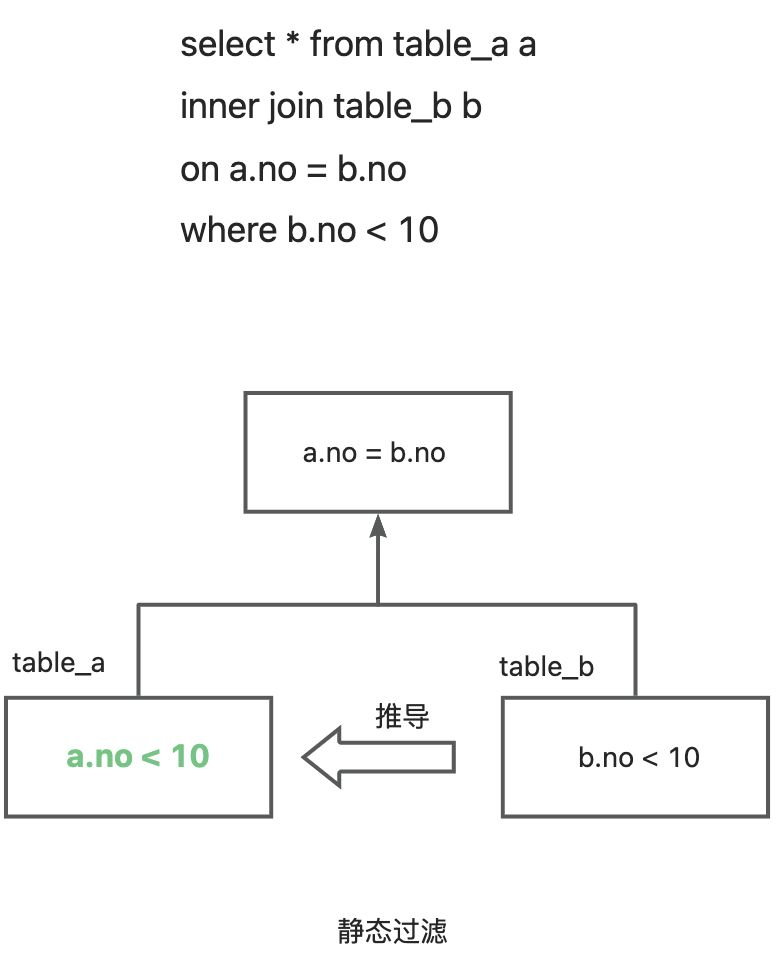
另外, 如果 SQL 语句中对于在 JoinKey 上进行过滤, 谓词下推优化器在 Inner Join 和 Right Join 的情况下可以将右表的谓词推导到左表进行过滤, 在 Inner Join 和 Left Join 的情况下可以将左表的谓词推导到右表进行过滤,这种情况属于静态过滤,所以也不需要开启动态过滤。
六、动态过滤的性能提升
在本地开发环境中生成两张表,并插入随机数据进行动态过滤的性能提升对比。
在大表中分别插入2000万行数据和200万行数据与小表进行Join做为对比。
大表的建表语句:
create table big_table(a varchar(8) comment '分布键',b bigint comment '主键',c bigint comment '外键',d varchar(255),e varchar(255),f varchar(255),i varchar(255),j varchar(255),k varchar(255),l varchar(255),m varchar(255),n varchar(255),o varchar(255),primary key (b, a))DISTRIBUTE BY HASH(`a`)INDEX_ALL='Y';
小表的建表语句:
create table small_table(a varchar(8) comment '分布键',b bigint comment '主键',c bigint comment '业务数据',primary key (b, a))DISTRIBUTE BY HASH(`a`)INDEX_ALL='Y';
查询语句:
select *from big_table b,small_table swhere b.c = s.band s.c < 100
Benchmark 结果:
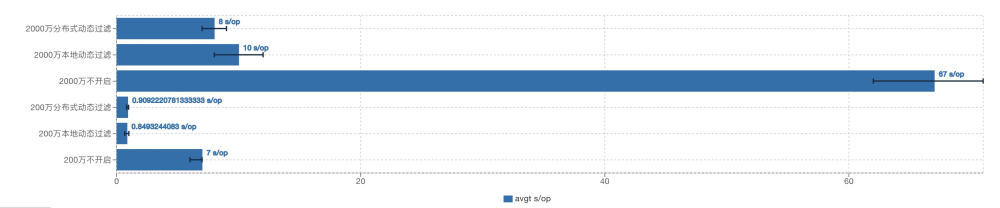
2000万/200万数据量, 分布式动态过滤/本地动态过滤/不开启动态过滤的性能对比:
对照组1:2000万数据量分布式动态过滤效果好些, 平均有8倍左右的性能提升。
对照组2:200万数据量下普通动态过滤与分布式动态过滤效果差不多, 平均有8倍左右的性能提升。
在本地开发环境后,利用TPC-H的数据集进行验证, 有如下的结果:
TPC-H Q17 SQL 语句:
select sum(l_extendedprice) 7.0 as avg_yearlyfrom lineitem,partwhere p_partkey = l_partkeyand p_brand = 'Brand#23'and p_container = 'MED BOX'and l_quantity < (select 0.2 * avg(l_quantity)from lineitemwhere l_partkey = p_partkey)

TPC-H 1G 环境 Q17 平均有18倍的性能提升。
关于石原子科技
石原子科技成立于 2021 年 10 月, 拥有国内顶级的数据库人才与专家,专注于企业级实时数据仓库和 MySQL 实时 HTAP 数据库的研发与应用,依托云中立的数据技术进行产品设计,致力于为客户提供大规模、高性能、低成本的一站式实时数据分析服务。
石原子科技坚持精细布局、自主创新的产品研发路线,打造了三款标杆产品:

业内首个单机内核开源、行列混存+内存计算架构的一体化 MySQL HTAP 数据库 StoneDB:使用 MySQL 的用户,通过 StoneDB 可以实现 TP+AP 混合负载,分析性能提升 10 倍以上显著提升,不需要进行数据迁移,也无需与其他 AP 集成,弥补 MySQL 分析领域的空白,形成实时在线数据就近分析。

基于全场景的新一代高性能、低成本的离在线一体化实时数仓 StoneData:高度兼容 MySQL 语法,毫秒级更新,亚秒级查询,满足准实时和实时分析需求,一体化架构将实时和离线融合,减少数据冗余和移动,具有简化技术栈架构的能力;实现业务与技术解耦,支持自助式分析和敏捷分析;无论是数据湖中的非结构化或半结构化数据,还是数据库中的结构化数据,都可使用 StoneData 构建企业的数据分析平台,同时完成高吞吐离线处理和高性能在线分析,实现降本增效。
基于容器、IAC 等技术的一站式数据库管理服务 StoneDMP:集数据管理、结构管理、用户授权、安全审计、数据趋势、数据追踪、BI 图表、性能与优化和服务器管理于一体的数据管理服务。
成立至今,公司已积累了上千位用户,种子客户达 300 多家,取得 30+ 项软件著作权,成功申请并获准通过了 10+ 项技术专利,分别获评浙江省级、国家级科技型中小企业。
石原子科技积极参与中国数据库产业建设,目前已经成为中国信通院分布式系统稳定性实验室成员单位、中国通信标准化协会(CCSA)大数据技术标准推进委员会(TC601)全权成员单位、中国信通院科技制造开源社区成员单位、中国信通院数据库应用创新实验室成员单位、国家信创工作委员会技术活动单位、浙江省信创联盟会员单位、上海市软件行业协会团体会员、北京信创工委会会员单位,先后参与起草多项国家级和行业级标准的编写工作。产品已经通过了中国信通院分布式分析型数据库基础能力专项评测、信息安全管理体系认证,并与主流服务器、操作系统、中间件等国产化软硬件生态体系进行全面兼容。

