





PostgreSQL troubleshooting系列之四
前言
接着电子书:《Troubleshooting PostgreSQL》。本文主要涉及书中的如下内容:
正确的获取事务和锁 (对应第五章)
5、正确的获取事务和锁
事务是每一个专业关系数据库系统的核心技术。事实上,现在很难想象一个没有交易的世界。原子删除、适当的锁定以及现代关系系统提供的所有功能都很简单,而且是现代系统所期望的,许多应用程序都依赖于它们。本章主要讨论事务和锁。
这里主要涉及以下几个方面的内容:
PG的事务模型
基本锁
三种锁相关的子句:FOR UPDATE, FOR SHARE, and NOWAIT
锁表
理解事务隔离级
索引与外键
事务和序列
5.1 PostgreSQL事务模型
PG的事务模型与其他DBMS还是有很大区别的。这里我们就通过一些实例来进行说明。首先,它要求使用BEGIN开始,然后commit或者rollback结束 。而且整个事务块必须没有任何错误才行:
test=# BEGIN;
BEGIN
test=# SELECT now();
now
-------------------------------
2014-09-22 13:27:24.952578+02
(1 row)
test=# SELECT now();
now
-------------------------------
2014-09-22 13:27:24.952578+02
(1 row)
test=# COMMIT;
COMMIT复制
注意,这里now()返回的是事务时间,因此,它总是返回相同的值,不管它在事务块里调用了多少回。很多人喜欢在列定义里使用DEDFAULT now()。那你就得记住,DEFAULT now() 总是返回当前事务的时间。即使它在一个长事务里头,返回的也是一个固定的时间。这也可以当作是一个技巧,用于判断是否所有行在同一个事务里进行过更新操作。
另一个要注意的是,你的这个事务必须没有任何错误:
test=# BEGIN;
BEGIN
test=# SELECT 1;
?column?
----------
1
(1 row)
test=# SELECT 1 / 0;
ERROR: division by zero
test=# SELECT 1;
ERROR: current transaction is aborted, commands
ignored until end of transaction block
test=# SELECT 1;
ERROR: current transaction is aborted, commands
ignored until end of transaction block
test=# COMMIT;
ROLLBACK复制
在这个简单的例子中,错误就发生在成功开启事务以后,主要问题是这个事务永远不会恢复正常,即使在后边有能正常工作的语句被调用。记住,一个事务必须从开头到结尾都能成功运行。否则,在出错以后所有的命令将被系统忽略。
【补充点内容:】嗯,上边的规则确实应该记着,也是默认的行为。我们可以使用一个开关来跳过这些错误(我们只需要设置开关:\set ON_ERROR_ROLLBACK on
),让后续的语句能继续执行,这就是“有名的“局部提交问题。看看下边这个示例:
mydb=# \set ON_ERROR_ROLLBACK on
mydb=# begin;
BEGIN
mydb=*# insert into t values(1, 'abc');
INSERT 0 1
mydb=*# insert into t values(2, abcd);
ERROR: column "abcd" does not exist
LINE 1: insert into t values(2, abcd);
^
mydb=*# commit;
COMMIT
mydb=# select * from t;
id | col2
----+------
1 | abc
(1 row)复制
5.1.1 理解savepoints
如果上边的条件我们也达不到,我们也可以考虑使用savepoint。savepoint是一种用于在事务里进行跳转的机制,可以有效的用于避免错误。下边的示例会用于显示它是如何工作的:
test=# BEGIN;
BEGIN
test=# SELECT 1;
?column?
----------
1
(1 row)
test=# SAVEPOINT s1;
SAVEPOINT
test=# SELECT 1 / 0;
ERROR: division by zero
test=# ROLLBACK TO SAVEPOINT s1;
ROLLBACK
test=# COMMIT;
COMMIT复制
在SELECT语句开始以后,创建了一个savepoint。注意那个savepoint,按建议来,将会提供一个标识用于后来返回。当错误出现时,就有机会跳转到这个savepoint。它的主要优点就是事务可以比较优雅地进行提交。
当然,也要注意:savepoint只能用于一个事务块以内,当事务提交或者回滚以后,它就不存在了。
5.1.2 理解基础锁和死锁
在了解了PG系统继而模型之后,是时候了解锁的相关内容了。在很多情况下,锁都变变成了瓶颈。因此,它绝对值得你去检查。
作为开始,我们看看下边一个简单的示例:
test=# CREATE TABLE t_test AS SELECT 1 AS id;
SELECT 1复制
这张表虽然只有一行,但也足够用于检查锁的一些基本概念。下边第一个示例,用于展示两人同时对该值加1的时候会发生什么。

这里目的是允许两人同时对该表的列ID进行加1操作。我们发现第二个UPDATE操作会等待第一个UPDATE操作被提交。这里我们要提及的是,我们说的是行级锁,而不是表级锁。PG只锁定那些被UPDATE语句影响的行,确保其他人不会遇到严重的瓶颈。
第二个重大发现是最后的结果;它能保证最后的输出结果总是3。只要第1个事务提交了,第2个UPDATE操作会重新读取已经提交的行,在此基础上加1。这个看起来,虽然有点逻辑问题,尽管它具有广泛的含义,但许多人并不广为人知。
我们把这个例子再扩展一下:
test=# INSERT INTO t_test VALUES (5);
INSERT 0 1
test=# SELECT * FROM t_test;
id
----
3
5
(2 rows)复制
在此基础上,再执行UPDATE操作:

(原文有错,我直接改过来了。)
第一个UPDATE语句,两个用户都能顺利进行。到了第2个UPDATE的时候,USER2就得等USER1。因为相同的那一行正在发生变化。最重要的是,最后一个UPDATE语句。它也要等USER2去完成ID=5的变更。于是谁也无法赢得这个游戏。最后PG逐步进入,解决这种没有希望的局面。准确的错误信息是这样子的:
test=# UPDATE t_test SET id = 6 WHERE id = 5;
ERROR: deadlock detected
DETAIL: Process 27988 waits for ShareLock on
transaction 1131992; blocked by process 28084.
Process 28084 waits for ShareLock on transaction
1131990; blocked by process 27988.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,5) in relation
"t_test"复制
死锁是自动解决的。该用户需要做的事情就是捕获这个错误,然后再度进行尝试。
注意:许多用户认为死锁是一件令人讨厌、极其危险和灾难性的事情。事实上,情况并非如此。死锁是完全自然的事情,只是偶尔发生而已。别慌! 相反,要从逻辑上思考它的根本原因。
我们如何避免死锁呢? 实际上,也没有什么通用规则 。个人觉得,按照固定的顺序去更新数据就很有帮助。在很多情况下,它会工作的很好,并能解决导致死锁的原因(那就是那些变更顺序都是未排序的)。除这个以外,也没有什么更好的手段去解决这种问题。
当提及死锁的时候,有很多人经常问到PG里头的一个参数:deadlock_timeout:
test=# SHOW deadlock_timeout;
deadlock_timeout
------------------
1s
(1 row)复制
在许多人的头脑中,对这个参数有一个普遍的误解。该参数实际上告诉我们系统在检查死锁之前等待多长时间。死锁检测是相当昂贵的,因此,PostgreSQL在初始化检查之前等待一秒钟。
5.1.3 FOR UPDATE模式下的锁
在本节中,将向您介绍一个困扰了几代数据库开发人员的问题——错误的或缺失的锁定。
让我们假设您正在读取一些数据,并且一旦您读取了它,您肯定打算稍后更改它。但是,如果在执行UPDATE时数据已经消失了呢? 我想这对你没有任何好处。
在PostgreSQL中,读取可以并发发生,许多人可以同时读取同一块数据而不会相互干扰。因此,读取并不能提供足够的保护,防止其他人也计划修改数据。结果可能很糟糕。考虑下面的例子:
BEGIN;
SELECT * FROM tab WHERE foo = bar;
UPDATE tab SET foo = "value made in the application";
COMMIT;复制
如图所示的事务并不安全。原因很简单: 如果人们并发地执行相同的事情怎么办? 它们可能会立即覆盖彼此的更改。显然,这将导致严重问题。
要避免这类问题的发生,FOR UPDATE就可以用来救火。我们看看下边的示例:
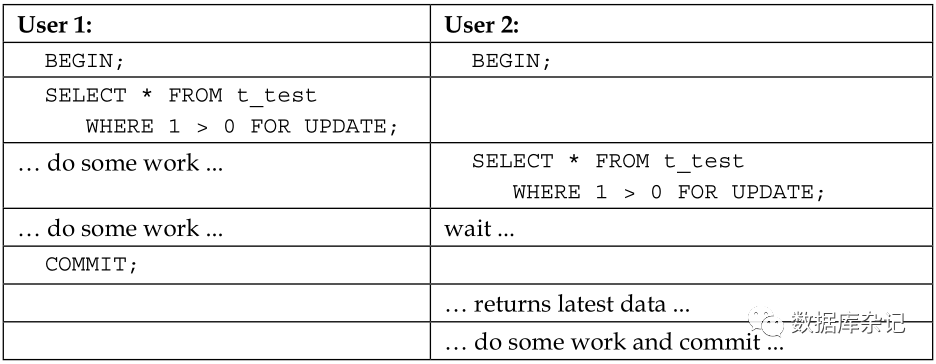
在这个例子中,SELECT … FOR UPDATE会锁定查询返回的那些行,就像UPDATE操作会锁定那些行一样。漂亮的地方在于第2个事务会等待第1个事务,要么你提交它,要么退出它。这里的优点是,第2个事务已经可以建立在第一个查询的更改之上,从而确保不会丢失任何东西。
避免性能瓶颈
当然,也有可能是无意的,SELECT …. FOR UPDATE有时候会导致严重的性能问题。考虑下边的例子:
SELECT … FROM a, b, c, d, e, f, g WHERE … FOR UPDATE;复制
我们假定你本意只是想修改a中的数据,而其他表只是用于做参考查询。而PG无从知道你只是要改a中的数据。它不得不锁定该查询返回的所有表中的所有记录行。虽然这是PostgreSQL必须做的事情,但它很可能导致涉及查找表的严重争用。
注意: 争用意味着您可能会看到以下任何情况: 相对较低的CPU使用率、较少的磁盘等待、较差的性能等等。如果CPU没有以最高速度工作,并且没有任何东西向前移动,那么您很可能面临由于某处锁定引起的争用。
有两种方法可以解决此类问题。第一种是使用SELECT… FOR UPDATE NOWAIT;这个语句会让查询停止,一旦它发现拿不到锁的时候。它对于你想避免无限期等待的情形很有帮助。第2个选项就更复杂些。考虑下下边的例子:
SELECT … FROM a, b, c, d, e, f, g WHERE … FOR UPDATE OF a, b;复制
在这个例子中,PG知道后边的若干步骤中,只有两张表最有可能更新,这样,它就会大幅提高锁的效率。
5.1.4 避免表级锁
在某些情况下,SELECT … FOR UPDATE是不够的,它可能需要锁定整张表。创建一个表锁,PG提供了简单命令:
test=# \h LOCK
Command: LOCK
Description: lock a table
Syntax:
LOCK [ TABLE ] [ ONLY ] name [ * ] [, ...] [ IN lockmode MODE ] [
NOWAIT ]
where lockmode is one of:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE
| SHARE UPDATE EXCLUSIVE | SHARE
| SHARE ROW EXCLUSIVE | EXCLUSIVE
| ACCESS EXCLUSIVE复制
请注意,PostgreSQL在这里有八个锁级别,从ACCESS SHARE一直到ACCESS EXCLUSIVE。它们允许您以非常细粒度的方式定义锁定。假设您希望确保您是唯一被允许读写表的人。那么需要的锁模式是ACCESS EXCLUSIVE。它完美地确保了没人能看到那张表。如果没有人应该修改表,但读取是完美的,EXCLUSIVE是首选选项。
另一种情形,有一个由简单读操作持有的锁,称为ACCESS SHARE。它可以很好地与其他读操作共存,不伤害他人。它只与ACCESS EXCLUSIVE冲突,DROP TABLE和类似的命令需要ACCESS EXCLUSIVE。
锁定表有时是必要的,但绝不能粗心地执行,因为它可能产生严重的副作用并阻塞其他事务。
当然我们可以看看官方文档,多了解一下:PostgreSQL: Documentation: 14: 13.3. Explicit Locking:https://www.postgresql.org/docs/14/explicit-locking.html
5.2 事务的隔离
在本节中,将向您介绍一个称为事务隔离的重要主题。在原作者作为PostgreSQL数据库顾问的漫长职业生涯中,我见过无数事务隔离导致巨大问题的场景。有时,人们甚至不顾一切地更换硬件,以解决与硬件无关的问题。
我们先看看读已提交 (RC)隔离级:
那么,什么是事务隔离?事务隔离背后的思想是为用户提供一种工具来控制他们在事务中看到的内容。报告可能与简单的OLTP应用程序有不同的需求,但我们不要迷失在计划理论中。相反,让我们看一个真实的例子:
test=# CREATE TABLE t_test (id int);
CREATE TABLE
test=# INSERT INTO t_test VALUES (4), (5);
INSERT 0 2复制
我们得到两行数据。看看两个事务同时访问数据时会发生什么。


第一个SELECT返回了9,符合预期。但是第一个事务依然活跃的时候,另外一个用户又插入了点数据。绝大多数人希望第1个事务返回的结果是9。但实际上不是。因为用户1是在一个事务中,它并不暗示在它里边数据的视图永远不变。默认情况下,PG使用的是读已提交隔离级。这意味着,一个事务会看到别的用户当中的每条语句执行以后的变化。
请注意,运行语句永远不会因为别人的改变而改变他们对世界的看法。在读提交模式下,在语句开始处创建快照。一旦它开始运行,它就保持原样。
由于其他提交而导致结果更改的事实可能会产生严重的影响。如果报告包含不止一个查询,则可能意味着第5页上显示的数据反映不了报告第29页上的内容。当然,这种差异不会一直出现,而只是偶尔出现——当有人碰巧同时在其他会话中提交更改时。
使用可重复读
要确保事务不改变它在现实世界中的视图,可以使用可重复读隔离级。下表就演示它如何工作:
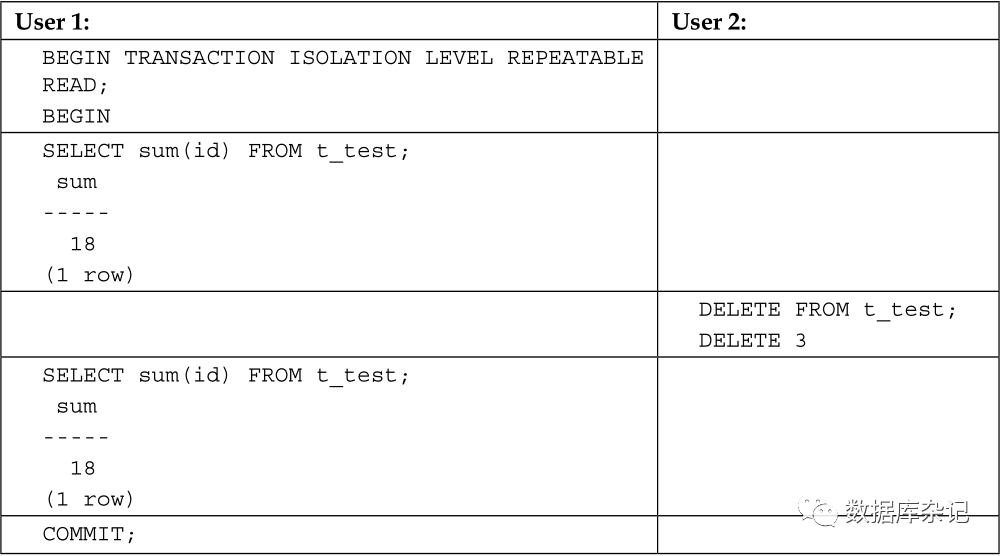
在这个示例中,事务里头,我们看到的求和的值始终不变。即算有并发的删除所有数据的DELETE操作,也不影响事务里头的求和的结果。换句话说,可以通过打开RR隔离级来避免前边出现的副作用。
注意:人们经常问RR隔离级相对于RC隔离级会有性能上的损失;“不会的”,两个隔离级拥有相同的吞吐量。没有性能瓶颈。(这是原作者的原话)
笔者注:我不敢苟同。几个并发的UPDATE操作,就会出现完全不同的效果。有兴趣的朋友可以自行尝试。
就像前边提到的那样,RR对于各类报表而言会表现的很好,但是它并不是所有类型应用的首先方案。普通的OLTP系统仍然是在RC隔离级下表现最好,这种隔离级下可以确保数据尽量最快的更新。
RR以外
不光只有RC和RR,最高的隔离级还有可串行化。它会将所有的事务串行化执行,避免各种类型的交互。
但是以串行的方式去执行事务通常并不是我们所期待的。它最大的问题是可伸缩性。它没办法进行水平扩展。
我们看看下边的例子:
CREATE TABLE t_prison (guard text);复制
让我们假设您希望确保始终只有一个保护键(对于本例,不允许使用主键)。现在一个事务可能看起来像这样:
BEGIN;
SELECT count(*) FROM t_prison;
if count > 1
delete a guard
COMMIT;复制
如果两个人同时执行,会发生什么? 两个人都会看到表中有两个人。他们每个人都会决定删除一个。如果我们运气不好,一个人会删除“BOB”,另一个人会删除“Alice”。瞧! 所有通往监狱的门都敞开着。使用可重复读还是已提交读并不重要。两个人可以同时检查内容,因此,看到相同的数据,得出相同的结论。
这个问题的解决方案是使用可串行隔离级。它确保同一时刻只有一个事务在运行。涉及相同数据(或相同谓词)的事务将相互冲突。
这样做的美妙之处在于,您基本上可以绕过表锁,从而提高可伸缩性。但是,如果事务因冲突而中止,则需要重试循环。
5.3 观测锁
在许多情况下,锁是大多数系统管理员的主要问题。如果一个事务阻塞了其他一些操作,这通常是一个问题。最终用户会抱怨“有些东西挂了”。然而,你可以相信PostgreSQL从来不会无缘无故挂起。通常,它很简单,而且都是关于锁定的。
在这一节里,我们可以尝试着如何探测锁,并了解是谁锁定哪个事务。
我们看看下边的语句:
test=# CREATE TABLE t_test AS SELECT *
FROM generate_series(1, 10) AS id;
SELECT 10复制
我们的目标是:使用两个并发的SELECT FOR UPDATE操作读取略微不同的数据。这两个操作会相互锁定。目标是确定哪个操作阻塞哪个事务。
第一个操作,对于大于9的记录要进行UPDATE
test=# BEGIN;
BEGIN
test=# SELECT * FROM t_test WHERE id > 9 FOR UPDATE;
id
----
10
(1 rows)复制
第二年操作,对大于8的记录要进行UPDATE:
test=# BEGIN;
BEGIN
test=# SELECT * FROM t_test WHERE id > 8 FOR UPDATE;复制
从逻辑上来讲,这个事务要等待第一个事务完成。如果您不知道这个情况,那该如何检查呢?
首先,可以检查一下:pg_stat_activity,它会提示正在进行哪些活动,并且哪些操作是活跃的:
test=# \x
Expanded display is on.
test=# SELECT pid, query, waiting
FROM pg_stat_activity;
[ RECORD1 ]--------------------------------------------
pid | 4635
query | SELECT * FROM t_test WHERE id > 9 FOR UPDATE;
waiting | f
[ RECORD2 ]--------------------------------------------
pid | 4637
query | SELECT * FROM t_test WHERE id > 8 FOR UPDATE;
waiting | t
[ RECORD3 ]--------------------------------------------
pid | 4654
query | SELECT pid, query, waiting
FROM pg_stat_activity;
waiting | f复制
在此例中,4637这个pid 标示着它正在等待什么事情。waiting=true意味着有潜在的一些问题。也意味着该事务正被阻塞着。另一个有用的事务视图就是pg_locks。这个视图可以告诉我们哪些锁已经被授予,哪些没有。
下边的查询用于找出哪些锁没被授予:
test=# SELECT locktype, granted, transactionid,
mode
FROM pg_locks WHERE granted = 'f';
locktype | granted | transactionid | mode
---------------+---------+---------------+-----------
transactionid | f | 1812 | ShareLock复制
看起来好像有人在等待1812这个事务。下一步,我们可以进一步看看1812这个事务的具体信息:
test=# SELECT granted, transactionid, mode, pid
FROM pg_locks
WHERE transactionid = 1812;
granted | transactionid | mode | pid
---------+---------------+---------------+------
t | 1812 | ExclusiveLock | 4635
f | 1812 | ShareLock | 4637
(2 rows)复制
这下清楚了,有两个进程都与事务1812有关。一个拥有锁,而另一个没有。很明显的,4635这个进程阻塞着进程4637。要解决这个问题,可以终止4635这个进程。
SELECT pg_terminate_backend(4635);复制
但是不要那么做。我们还可以找到更多的信息。当锁在有空突的行上被持有的时候,pg_locks里会有相应的记录。
test=# SELECT pid, relation, page, tuple
FROM pg_locks
WHERE page IS NOT NULL;
pid | relation | page | tuple
------+----------+------+-------
4637 | 16385 | 0 | 10
(1 row)复制
很明显,在16385这个关系的第0页,第10个元组有一个锁。pid指示着等待事务在等待着这一行。
在很多情况下,我们甚至可以看出引发问题的那一行。所谓的ctid可以用来标识存储系统的一行。要查询行,我们可以这么做:
test=# SELECT ctid, * FROM t_test
WHERE ctid = '(0, 10)';
ctid | id
--------+----
(0,10) | 10
(1 row)复制
问题是由第10行引起的。它是由第一个SELECT命令引起的行锁。检查导致问题的行可以让您了解系统中真正发生了什么。在终止数据库连接之前,明智的做法是检查出真正造成问题的数据类型。有时,这可能会暴露底层应用程序中的问题。
小结:
在本章中,向您介绍了锁和事务。正如所指出的,锁定是影响可伸缩性和数据正确性的核心问题。注意锁是很重要的。特别是,事务隔离是一个重要的问题,但许多开发人员经常忘记它,这反过来可能导致应用程序出现错误。除此之外,苛刻的锁还会导致可伸缩性问题和超时。
除了您所看到的,还可以对锁进行逆向工程,以找出谁在等待谁。
参考:
《Troubleshooting PostgreSQL》第5章

