




在mysql中,explain是SQL优化的重要工具,它可以查看表的加载顺序、表连接关系、索引使用情况以及SQL处理方式等。本文结合案例详解explain字段含义,深入理解执行计划,让我们写出更懂mysql的SQL语句。
- id
- select_type
- table
- partitions
- type
- possible_keys
- key
- key_len
- ref
- rows
- filtered
- Extra
一、id列
表示查询的一个序列号,用来表示查询中执行select子句或操作表的顺序。当id值相同时,查询的执行顺序为由上至下(如上图)。当ID值不同时,id的序号会递增,执行顺序由大到小。
1.1 id=1的场景
单表查询、join连接中,id值都是1且从上到下执行,第一行为驱动表。
示例
第一行dept表为驱动表,两张表join连接,所以id值均为1。
root@localhost: 11:10: [scott]> explain select e.ename,e.job,d.deptno from emp e left join dept d on e.deptno = d.deptno where d.dname='SALES';
+----+-------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 25.00 | Using where |
| 1 | SIMPLE | e | NULL | ref | deptno | deptno | 5 | scott.d.deptno | 4 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
1.2 id>=2的场景
SQL语句出现subquery,scala subquery,derived时,id会出现递增现象。
- subquery:子查询;
- scala subquery:标量子查询;
- drived:FROM后子查询select会出现此种类型,mysql会递归并将结果放到一个临时表中,称为派生表,因为临时表是从子查询中派生而来的。
若存在不同的id(如1和2),需结合select_type和查询逻辑判断,执行顺序遵循以下规则:
- 通常情况下,若id不同且子查询非相关,驱动表为id较大的行(如2)对应的步骤;
- 若为相关子查询(select_type=DEPENDENT SUBQUERY),驱动表为id较小的行(如1)对应的表。
a. 非相关子查询或优化后的JOIN:当子查询为非相关子查询(如IN子查询,且被优化为JOIN或物化临时表)时,较大的id(如2)对应的步骤会先执行。此时,驱动表为id=2的行对应的表或子查询结果,因为它生成的结果集用于驱动后续操作(如主查询的连接)。 示例:
EXPLAIN SELECT * FROM table1 WHERE id IN (SELECT id FROM table2);
若子查询被物化为临时表(select_type=MATERIALIZED),执行计划可能显示:
id | select_type | table | ...
1 | PRIMARY | <subquery2>| ...
2 | MATERIALIZED | table2 | ...
此时,id=2的子查询先执行,结果作为驱动表,与主查询(id=1)的table1进行连接。
b. 相关子查询(DEPENDENT SUBQUERY) :当子查询依赖外部查询的值时,主查询(id=1)会先执行,逐行获取数据,然后触发子查询(id=2)。此时,驱动表为id=1的行对应的表,子查询针对每一行外部数据执行。 示例:
EXPLAIN SELECT * FROM table1 t1 WHERE EXISTS (SELECT 1 FROM table2 t2 WHERE t2.id = t1.id);
执行计划可能显示:
id | select_type | table | ...
1 | PRIMARY | t1 | ...
2 | DEPENDENT SUBQUERY | t2 | ...
此时,t1(id=1)是驱动表,子查询(id=2)逐行依赖t1的数据。
c. 派生表drived:派生表先执行,然后以临时表的身份出现在连接条件中。示例:
下面示例中
- 子查询优先执行(id=2),使用索引deptno(key=deptno)对emp表进行全索引扫描(type=index),按deptno分组计算平均工资,结果存入临时表
。临时表的结果集:每个deptno对应一个pjsal(平均工资)。 - 然后主查询执行(id=1),驱动表:dept d(全表扫描), 连接派生表
(通过deptno关联),再连接salgrade s(范围匹配)。
#每个部门的平均工资和工资等级
mysql> select d.*,t.pjsal,s.grade
-> from dept d ,(select deptno,avg(sal) pjsal from emp group by deptno) t, salgrade s
-> where d.deptno=t.deptno and t.pjsal between s.losal and s.hisal;
+--------+------------+----------+-------------+-------+
| deptno | dname | loc | pjsal | grade |
+--------+------------+----------+-------------+-------+
| 30 | SALES | CHICAGO | 1566.666667 | 3 |
| 10 | ACCOUNTING | NEW YORK | 2916.666667 | 4 |
| 20 | RESEARCH | DALLAS | 2175.000000 | 4 |
+--------+------------+----------+-------------+-------+
3 rows in set (0.00 sec)
#执行计划
mysql> explain select d.*,t.pjsal,s.grade
-> from dept d ,(select deptno,avg(sal) pjsal from emp group by deptno) t, salgrade s
-> where d.deptno=t.deptno and t.pjsal between s.losal and s.hisal;
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+----------------------------------------------------+
| 1 | PRIMARY | d | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key1> | <auto_key1> | 5 | scott.d.deptno | 2 | 100.00 | NULL |
| 1 | PRIMARY | s | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where; Using join buffer (Block Nested Loop) |
| 2 | DERIVED | emp | NULL | index | deptno | deptno | 5 | NULL | 14 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+----------------------------------------------------+
4 rows in set, 1 warning (0.01 sec)
二、select_type列
insert/update/delete语句对应的值分别为insert/update/delete,而select语句对应的值有12种,描述了具体是什么类型的查询。
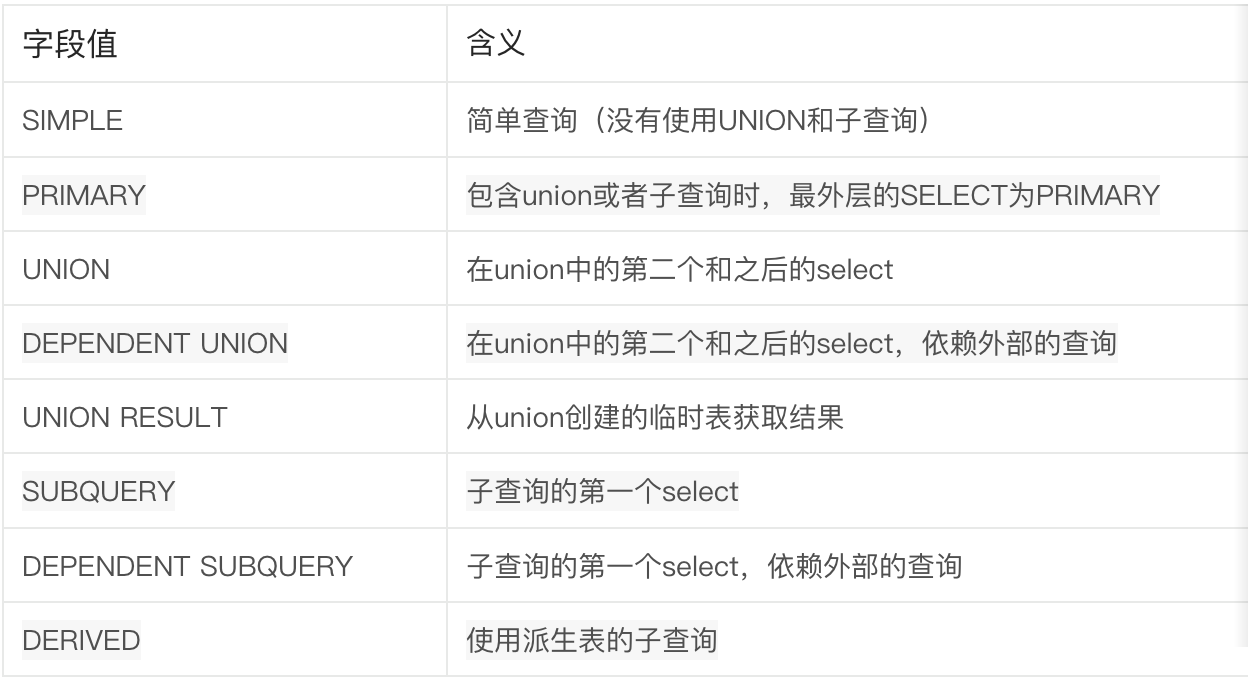
2.1 simple
不使用union或者subquery等的简单query
mysql> explain select * from emp e
left join dept d on e.deptno=d.deptno
where e.sal between 1200 and 1500;
+----+-------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
| 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 11.11 | Using where |
| 1 | SIMPLE | d | NULL | eq_ref | PRIMARY | PRIMARY | 4 | scott.e.deptno | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
2.2 primary
复杂查询中最外层的 select
mysql> explain select d.*,t.pjsal,s.grade
-> from dept d ,(select deptno,avg(sal) pjsal from emp group by deptno) t, salgrade s
-> where d.deptno=t.deptno and t.pjsal between s.losal and s.hisal;
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+----------------------------------------------------+
| 1 | PRIMARY | d | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key1> | <auto_key1> | 5 | scott.d.deptno | 2 | 100.00 | NULL |
| 1 | PRIMARY | s | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where; Using join buffer (Block Nested Loop) |
| 2 | DERIVED | emp | NULL | index | deptno | deptno | 5 | NULL | 14 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+----------------------------------------------------+
4 rows in set, 1 warning (0.01 sec)
2.3 union
- union result是union去掉重复值的临时表;
- union all 不出现union result,因为不去重;
- 5.6、5.7中,union与union all性能差不多。8.0会好很多。
# union result是union去掉重复值的临时表
mysql> explain select * from emp where ename='MARTIN'
-> union
-> select * from emp where ename='BLAKE'
-> union
-> select * from emp where ename='JAMES';
+----+--------------+--------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+--------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 10.00 | Using where |
| 2 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 10.00 | Using where |
| 3 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 10.00 | Using where |
| NULL | UNION RESULT | <union1,2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+--------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
4 rows in set, 1 warning (0.01 sec)
# union all 不出现union result,因为不去重。
mysql> explain select * from emp where ename='MARTIN' union all select * from emp where ename='BLAKE' union all select * from emp whereename='JAMES';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 10.00 | Using where |
| 2 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 10.00 | Using where |
| 3 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
2.4 subquery 子查询
mysql> explain select count(*) from emp
-> where deptno= (select deptno from dept where dname='ACCOUNTING');
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+--------------------------+
| 1 | PRIMARY | emp | NULL | ref | deptno | deptno | 5 | const | 3 | 100.00 | Using where; Using index |
| 2 | SUBQUERY | dept | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where |
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+--------------------------+
2 rows in set, 1 warning (0.01 sec)
2.5 dependent subquery
必须依附于外面的值。如scala subquery(标量子查询)或者exists
a. scala subquery
标量子查询相当于函数,与调用次数有关,from后面的表为299423行,及标量子查询b调用299423次。另外标量子查询只能返回一行值。
mysql> explain select d.*,(select count(*) from emp e where e.deptno = d.deptno) as dept_nums from dept d;
+----+--------------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| 1 | PRIMARY | d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 2 | DEPENDENT SUBQUERY | e | NULL | ref | deptno | deptno | 5 | scott.d.deptno | 4 | 100.00 | Using index |
+----+--------------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
2 rows in set (0.00 sec)
b. exists
exists在5.7中是dependent subquery。在8.0.17改写为simple了(semijoin优化)。
换句话说,在mysql 8.0.17前,exists 与 in 最大的区别是,in子句中的子查询会改写为semijoin,而exists无法改写。
mysql> select d.* from dept d where exists (select deptno from emp e where e.deptno=d.deptno and ename='SMITH');
+--------+----------+--------+
| deptno | dname | loc |
+--------+----------+--------+
| 20 | RESEARCH | DALLAS |
+--------+----------+--------+
1 row in set (0.00 sec)
mysql> select d.* from dept d where d.deptno in (select deptno from emp where ename='SMITH');
+--------+----------+--------+
| deptno | dname | loc |
+--------+----------+--------+
| 20 | RESEARCH | DALLAS |
+--------+----------+--------+
1 row in set (0.00 sec)
mysql> explain select d.* from dept d where exists (select deptno from emp e where e.deptno=d.deptno and ename='SMITH');
+----+--------------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| 1 | PRIMARY | d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | e | NULL | ref | deptno | deptno | 5 | scott.d.deptno | 4 | 10.00 | Using where |
+----+--------------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
类似于标量子查询,外层多少条记录,子查询就执行多少次,执行效率较低。
step1:先从外层查询中获取一条记录。如上,先从dept表中获取一条记录。
step2:然后从这条记录中找出子查询中涉及的值。 即从dept表获取的那条记录中找出d.deptno列的值,然后执行子查询。
step3:最后根据子查询的查询结果来检测外层查询WHERE子句的条件是否成立。如果成立,就把外层查询的那条记录加入到结果集,否则就丢弃。
step4:跳到步骤1,直到外层查询中获取不到记录为止。
mysql> explain select d.* from dept d where d.deptno in (select deptno from emp where ename='SMITH');
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------------------------------------------------------------+
| 1 | SIMPLE | d | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | emp | NULL | ALL | deptno | NULL | NULL | NULL | 14 | 7.14 | Using where; FirstMatch(d); Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
mysql> show warnings;
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `scott`.`d`.`deptno` AS `deptno`,`scott`.`d`.`dname` AS `dname`,`scott`.`d`.`loc` AS `loc` from `scott`.`dept` `d` semi join (`scott`.`emp`) where ((`scott`.`emp`.`deptno` = `scott`.`d`.`deptno`) and (`scott`.`emp`.`ename` = 'SMITH')) |
+-------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
2.6 derived 派生表(重点)
from 关键字后面是一个独立的子查询,mysql会将结果存放在这个内部临时表中。
- 其实就是from后面的subquery
- derived是生成在内存或者临时表中的(内存放不下会放到临时表)
- 如果derived当作驱动表的时候,重点目标是要减少数据量
- 当作被驱动表时,产生auto_key索引。但是数据量很大时auto_key性能也不行。
在mysql5.7,optimizer_switch=‘derived_merge=on’ 可以把简单的subquery改写成join。这个动作称为视图合并。注意:5.6不会进行视图合并。如果deriverd临时表很大的话,会放在临时表,会影响性能。所以大版本升级的时候,一定要关注这个功能的影响。
mysql> explain select d.* from dept d left join (select * from emp) e on e.deptno=d.deptno;
+----+-------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | emp | NULL | ref | deptno | deptno | 5 | scott.d.deptno | 4 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+--------+---------+----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
#关闭视图合并后查看执行计划
mysql> set session optimizer_switch='derived_merge=off';
Query OK, 0 rows affected (0.00 sec)
mysql> explain select d.* from dept d left join (select * from emp) e on e.deptno=d.deptno;
+----+-------------+------------+------------+------+---------------+-------------+---------+----------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+-------------+---------+----------------+------+----------+-------+
| 1 | PRIMARY | d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | NULL |
| 2 | DERIVED | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+-------------+---------+----------------+------+----------+-------+
3 rows in set, 1 warning (0.00 sec)
那么derived_merge on/off 对sql优化有什么影响呢?
- 为on时,被驱动表的连接条件需要有索引(开启时,会改写临时表为外连接)
- 为off时,被驱动表结果集要小,防止内存装不下。(被驱动表是deriverd临时表,结果集太大时会溢出到磁盘)
a. 当派生表作为被驱动表出现时,会产生auto_key索引
mysql> explain select d.* from dept d left join (select * from emp) e on e.deptno=d.deptno;
+----+-------------+------------+------------+------+---------------+-------------+---------+----------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+-------------+---------+----------------+------+----------+-------+
| 1 | PRIMARY | d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | NULL |
| 2 | DERIVED | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+-------------+---------+----------------+------+----------+-------+
3 rows in set, 1 warning (0.00 sec)
b. 在mysql 5.7,Derived不能视图合并的几种情况
- union/union all
- group
- distinct
- 聚合函数
- limit
- @
示例:
union在子查询时,无法视图合并。
mysql> explain select count(*)
-> from (select * from emp union select * from emp) es
-> join dept d on es.deptno=d.deptno;
+----+--------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+-----------------+
| 1 | PRIMARY | d | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using index |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | NULL |
| 2 | DERIVED | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | NULL |
| 3 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | NULL |
| NULL | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+-----------------+
5 rows in set, 1 warning (0.00 sec)
group by在子查询时,无法视图合并。
mysql> explain select count(*) from ( select deptno from emp) es join dept d on es.deptno=d.deptno;
+----+-------------+-------+------------+-------+---------------+---------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+----------------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using index |
| 1 | SIMPLE | emp | NULL | ref | deptno | deptno | 5 | scott.d.deptno | 4 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
#子查询存在group by时无法试图合并
mysql> explain select count(*) from ( select deptno from emp group by deptno) es join dept d on es.deptno=d.deptno;
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
| 1 | PRIMARY | d | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using index |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | Using index |
| 2 | DERIVED | emp | NULL | range | deptno | deptno | 5 | NULL | 4 | 100.00 | Using index for group-by |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
3 rows in set, 1 warning (0.00 sec)
distinct在子查询时,无法视图合并。
mysql> explain select count(*) from ( select distinct deptno from emp) es join dept d on es.deptno=d.deptno;
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
| 1 | PRIMARY | d | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using index |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | Using index |
| 2 | DERIVED | emp | NULL | range | deptno | deptno | 5 | NULL | 4 | 100.00 | Using index for group-by |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
3 rows in set, 1 warning (0.00 sec)
聚合函数、limit在子查询时,无法视图合并。
#子查询使用了聚合函数
mysql> explain select count(*) from ( select count(deptno),deptno from emp) es join dept d on es.deptno=d.deptno;
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | PRIMARY | d | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
| 2 | DERIVED | emp | NULL | index | NULL | deptno | 5 | NULL | 14 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
# 子查询使用了limit
mysql> explain select count(*) from ( select deptno from emp limit 2) es join dept d on es.deptno=d.deptno;
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+-------------+
| 1 | PRIMARY | d | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using index |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | Using index |
| 2 | DERIVED | emp | NULL | index | NULL | deptno | 5 | NULL | 14 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
使用自定义变量@时,无法视图合并。常见于存储过程。
#在存储过程中,用户变量常用于传递动态值,例如:
CREATE PROCEDURE dynamic_query()
BEGIN
SET @value = 100;
SELECT * FROM view_using_variable;
END;
#每次调用存储过程时,@value的值可能不同。优化器无法提前预知变量的值,因此无法将视图合并到主查询中。
2.7 materialized 物化表
物化表会预先计算并存储where关键字后的子查询的结果集,可以有效减少查询的执行时间和资源消耗,它也属于内部临时表。
注意区分:from后面的子查询会产生派生表(derived),where后面的子查询会产生物化表(materialized),都属于临时内存表。
mysql> explain select * from emp where ename in (select ename from emp);
+----+--------------+-------------+------------+--------+---------------+------------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+------------+--------+---------------+------------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | Using where |
| 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_key> | <auto_key> | 48 | scott.emp.ename | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | emp | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | NULL |
+----+--------------+-------------+------------+--------+---------------+------------+---------+-----------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
将in子查询结果集保存到临时表的过程称为物化,存储子查询结果集的临时表就是物化表。物化表中的记录都建立了索引,通过索引来判断操作的值是否在子查询结果集中。这种查询速度很快,可以有效提升子查询语句的性能。
- 基于内存的物化表有哈希索引;
- 基于磁盘的物化表有 B+树索引。
三、table列
当前查询所涉及的表。可以是真实的表名,也可以是在查询过程中产生的匿名临时表。
3.1 null表示不使用任何表
比如运算、dual等
mysql> desc select 1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
其中extra列的’select tables optimized away’常见于早期版本mysiam引擎,类似于计数器统计,不太准确,现在已经没有了。
mysql> explain select count(*) from dept_my1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
其中extra列的’select tables optimized away’常见于早期版本mysiam引擎,类似于计数器统计,不太准确,现在已经没有了。
mysql> explain select count(*) from dept_my1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
3.2 <derived + id>、<union + id> 表示临时表<>里的数字是id列
表示临时表,<>里面的数字是id列。tmp_table_size=max_heap_table_size,建议适当调大,避免影响性能。
示例:
mysql> explain select count(*) from ( select distinct deptno from emp) es join dept d on es.deptno=d.deptno;
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
| 1 | PRIMARY | d | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using index |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | scott.d.deptno | 2 | 100.00 | Using index |
| 2 | DERIVED | emp | NULL | range | deptno | deptno | 5 | NULL | 4 | 100.00 | Using index for group-by |
+----+-------------+------------+------------+-------+---------------+-------------+---------+----------------+------+----------+--------------------------+
3 rows in set, 1 warning (0.00 sec)
四、partitions
partitions列显示查询实际访问的分区名称。如果表未分区,该列为NULL。

欢迎关注作者公众号:类MySQL学堂
