





前言
这几天有几位同学,不知道从哪里收集到的几道PostgreSQL的练习题目,看看也蛮有意思。这里列出来,逐个尝试解析。不保证所有解答是正确,主要目的,是为了掌握背后隐藏的知识点。
分析
题一
1. pg_basebackup可以用于在线文件级备份,则下面那些参数必须设置大于0才生效
A.max wal senders
B.wal keep segments
C.wal segment size
D.checkpoint timeout
这道题,老实说,感觉不是怎么严谨的。C这个纯粹是为了凑选项。它根本就不是设置类的参数。在实例初始化的时候就指定了的,并且不可能不大于0.
针对A答案,如果将其设置为0,
pg_basebackup -Fp -v -D ../d1 1 ↵
pg_basebackup: error: connection to server on socket "/tmp/.s.PGSQL.5555" failed: FATAL: number of requested standby connections exceeds max_wal_senders (currently 0)
结果导致全备失败。单选选A。
我们再看看 D :
checkpoint_timeout = 0min # range 30s-1d
这样设置以后,你启动server都会失败:
0 s is outside the valid range for parameter "checkpoint_timeout" (30 .. 86400)
B值只是要求wal保留多少,与全备能否成功无关。
题二
3.在PostgresoL中设置账户admin永不过期的SQL命令是
A.ALTER ROLE user1 UNLOCK ACCOUNT;
B.ALTER USER user1 ACCOUNT UNLOCK;
C.ALTER ROLE user VALID UNTIL 'infinity';
D.ALTER user user1 VALID UNTIL infinity;
(C)
这个好解释。直接测试一下便知。不过,这里要提醒的是,A 和 B的用法,在PostgreSQL里头是不支持。
这种语法多见于别的数据库。
如果想所谓的“锁定”某一个用户,直接用:(nologin的权限即可)
mydb=# alter user mydb nologin;
ALTER ROLE
mydb=# \c - mydb
connection to server on socket "/tmp/.s.PGSQL.5555" failed: FATAL: role "mydb" is not permitted to log in
Previous connection kept
想解锁:
mydb=# alter user mydb login;
ALTER ROLE
mydb=# \c - mydb
You are now connected to database "mydb" as user "mydb".
题三
3. PostgresQL中的savepoint在事务结束后仍然有效
A.是 B.否
(B)
savepoint只能在事务里头有效。所以事务结束以后,它也就自动结束了。
题四
4. (多选题)由于业务需求、需要在数据库中存放少量图片文件,使用如下命令创建相关的表: CREATE TABLE images(pid bigserial primary key, ouid varchar, main oid);
INSERT INTO images VALUES(1, 'TO User', lo_import('/tmp/imagel2f41a3eb.jpg')); 并导入数据;下面描述正确的是:
A.导入的图片数据储存于表images中
B.导入的图片数据储存于系统表pg Largeobject中
c.删除images的行记录就可以册除对应的图片数据
D.truncate表images不能立即回收图片数据所占的磁盘空间
图片内容使用的是Large Object的形式存储,必然是B。删除了image中的行记录,LO中的内容依然还在。这样,即算truncate表images,LO中的数据还在,因而对应的磁盘空间还是不能回收。选的应该是(B, D)
看看下边的示例:
mydb=# INSERT INTO images VALUES(1, 'TO User', lo_import('/tmp/imagel2f41a3eb.jpg'));
INSERT 0 1
mydb=# select * from images;
pid | ouid | main
-----+---------+-------
1 | TO User | 29899
(1 row)
删掉一行,内容还在:
mydb=# delete from images;
DELETE 1
mydb=# select lo_get(29899, 0, 2); --读取LO的头两个字节
lo_get
--------
\x666a
(1 row)
-- truncate之后,依然还在
mydb=# truncate images;
TRUNCATE TABLE
mydb=# select lo_get(29899, 0, 2);
lo_get
--------
\x666a
(1 row)
-- 真正的删除,需要用:lo_unlink(loid)
mydb=# INSERT INTO images VALUES(1, 'TO User', lo_import('/tmp/imagel2f41a3eb.jpg'));
INSERT 0 1
mydb=# select * from images;
pid | ouid | main
-----+---------+-------
1 | TO User | 29904
(1 row)
mydb=# select lo_unlink(29904);
lo_unlink
-----------
1
(1 row)
mydb=# select lo_get(29904, 0, 2);
ERROR: large object 29904 does not exist
后边再清除(delete, truncate)就顺理成章了。一定要保持一致。
题五
5. (多选题)在PostgresQL中、新建的表或索引是
A.表是索引组织表
B.表是堆表
C.索引是聚集索引
D.索引是二级索引
这道题,考的是概念方面的居多。首先,PG中的表不是索引组织表。表与索引的组织结构完全分开。它里头的表是按堆的顺序来组织的。
那么,里头的索引是聚集索引(cluster index)吗?也不是。要不然,就不会有cluster index这个专有命令了。
再看看D: 索引是二级索引。如果结合聚集索引的概念,可以理解为它是二级索引。
倾向于选 (B, D)
题六
6. (多选题)会引起目标数据库对象oid变化的操作
A.VACUUM FULL
B.REINDEX
C.ANALYZE
D.CLUSTER
(A, B, D)
下边是一位同学直接给出的示例:
x_db=# create table b(i int);
CREATE TABLE
x_db=# select oid,relfilenode from pg_class where relname='b';
oidrelfilenode
.------十------------
66191
66191
(1 row)
x_db=# vacuum full b; -- file node变了
VACUUM
x_db=# select oid,relfilenode from pg_class where relname='b';
oidrelfilenode
66191
66194
(1 row)
x_db=# vacuum ; -- file node不变
VACUUM
x_db=# select oid,relfilenode from pg_class where relname='b';
oidrelfilenode
66191
66194
(1 row)
x_db=# vacuum b;
VACUUM
x_db=# select oid,relfilenode from pg_class where relname='b';
oidrelfilenode
66191
66194
(1 row)
x_db=# insert into table b values(1);
ERROR :syntax error at or near "table
LINE 1:insert into table b values(1)
x_db=# insert into b values(1);
INSERT 0 1
x_db=# select oid,relfilenode from pg_class where relname='b';
oidrelfilenode
66191
66194
(1 row)
x_db=# vacuum b; -- file node仍不变
VACUUM
x_db=# select oid,relfilenode from pg_class
oidrelfilenode
66191
66194
(1 row)
至于cluster, 与 reindex. 看看下边的示例:
postgres-postgres=# select pg_relation_filenode("test4');
pg_relation filenode
(1 row)
24757
postgres=# truncate test4;
TRUNCATE TABLE
postgres=# select pg_relation_filenode('test4');
pg_relation filenode
24762
(1 row)
postgres=# cluster test4 using idx num ;
CLUSTER
postgres-# select pg_relation_filenode('test4');
pg relation filenode
24764
(1 row
postgres-#
这可以说明,cluster、truncate命令改变了表数据的filenode.
有些同学认为reindex改变不了相关对象的id, 果真如此吗?
x_db=# select pg_relation_filenode('b');
pg_relation_filenode
67029
(1 row)
x_db=# REINDEX INDEX index_name ;
REINDEX
x_db=# REINDEX INDEX index_name
REINDEX
x_db=# select pg_relation_filenode('b');
pg_relation_filenode
67029
(1 row)
看看这个示例,要知道reindex是index重建, 它最终会改变index文件的node id.
完整示例如下:
mydb=# create table test(id int primary key, col2 varchar(32));
CREATE TABLE
mydb=# insert into test select n, 'test ' || n from generate_series(1, 10000) as n;
INSERT 0 10000
mydb=# \di test*
List of relations
Schema | Name | Type | Owner | Table
--------+-----------+-------+----------+-------
public | test_pkey | index | postgres | test
(1 row)
mydb=# select pg_relation_filepath('test_pkey');
pg_relation_filepath
----------------------
base/16385/29878
(1 row)
mydb=# reindex index test_pkey;
REINDEX
mydb=# select pg_relation_filepath('test_pkey');
pg_relation_filepath
----------------------
base/16385/29880
(1 row)
mydb=# select relname, oid, relfilenode from pg_class where relname in ('test', 'test_pkey');
relname | oid | relfilenode
-----------+-------+-------------
test | 29875 | 29875
test_pkey | 29878 | 29880
(2 rows)
mydb=# select relname, oid, relfilenode, pg_relation_filepath(oid) from pg_class where relname in ('test', 'test_pkey');
relname | oid | relfilenode | pg_relation_filepath
-----------+-------+-------------+----------------------
test | 29875 | 29875 | base/16385/29875
test_pkey | 29878 | 29880 | base/16385/29880
(2 rows)
mydb=# cluster test_pkey on test;
CLUSTER
mydb=# select relname, oid, relfilenode, pg_relation_filepath(oid) from pg_class where relname in ('test', 'test_pkey');
relname | oid | relfilenode | pg_relation_filepath
-----------+-------+-------------+----------------------
test | 29875 | 29882 | base/16385/29882
test_pkey | 29878 | 29885 | base/16385/29885
(2 rows)
所以,最终主张选:(A,B,D)
题七
7. (多选题)以下哪些是数据库实例级别的权限?
A.CONNECT
B.SUPERUSER
C.CREATEDB
D.CREATEROLE
(B, C, D)
要求是实例级别。A是针对某个数据库的连接权限,排除。而其它几个都作用于实例范围。
欢迎不同意见,文后留言。
题八
8. (多选题)下列关于CUSTER命令说法正确的是
A.该命今需要rebuild表
B.原理是在原表上进行数据块移动排序
C.如果一个表被执行过Cluster、那么对该表的后续更新也会被排序写入
D.CLUSTER命令也具有回收磁盘空间的效果
(A, D)
根据cluster命令的原始概念,A没有什么疑问。 D选项,我们直接根据一个同学的实验,可以印证:
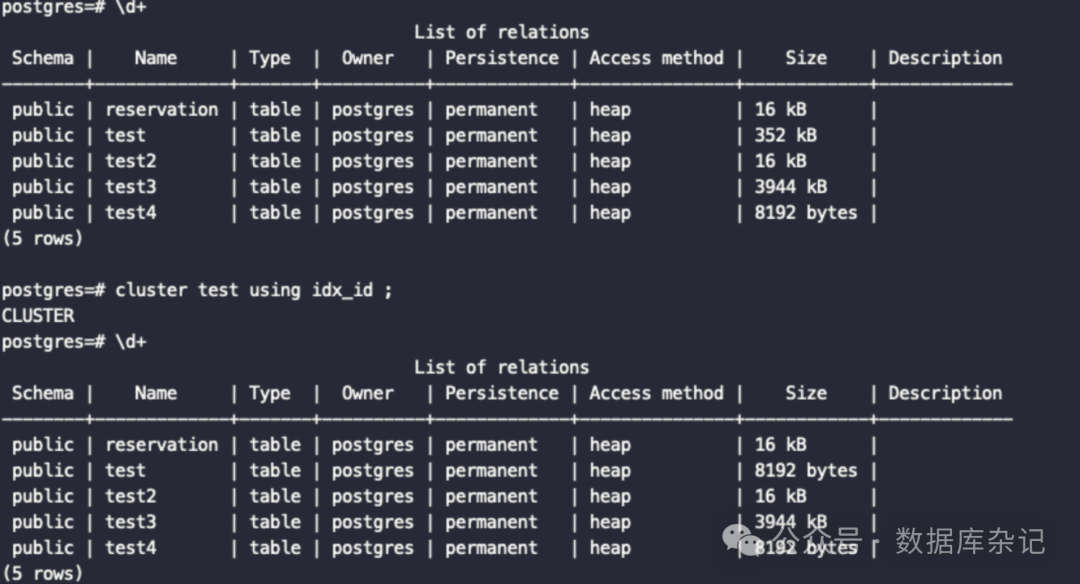
比较有疑问的是B,是在原表上进行数据块移动和排序吗?要知道执行完以后,原始nodeid对应的文件内容已经全部清空。有兴趣可以自行实验。
这里主张只选(A, D)
总结与声明
上边题目,虽提供了一些解析,但不一定答案是正确的。只是尝试着进行解答,把其中的原理弄明白,分享与大家。做题只是巩固知识技能的一种手段,最终还是要了解背后的原理,并用于实际的工作当中。
如果有不同理解,欢迎文后留言。
我是【Sean】, 欢迎大家长按关注并加星公众号:数据库杂记。有好资源相送,同时为你提供及时更新。已关注的朋友,发送0、1到7,都有好资源相送。

往期导读:
1. 小福利: ULID---另一种半有序高效全局ID出现了
2. 小心使用UUID, PostgreSQL中的UUID的弊端及解决方案
3. 一个有关UUID字段相关类型的有趣案例
4. PostgreSQL SQL的基础使用及技巧
5. PostgreSQL开发技术基础:过程与函数
6. 几道小题:几个易出错的PostgreSQL小用法(一)
文章转载自数据库杂记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
