




DuckDB是一款非常火的OLAP嵌入式数据库,性能超级棒。它分为多个组件:解析器、逻辑规划器、优化器、物理规划器、执行器以及事务和存储管理层。其中解析器原语PgSQL的解析器;逻辑规划器包含binder、plan generator,前者解析所有引用的schema中的对象的表达式,将其与列名和类型匹配,后者将binder生成的AST转换成由基本逻辑查询运算符组成的树;优化器产生优化的查询计划;物理规划器将优化的查询计划转换成物理执行计划,即PhysicalOperator树。它的高性能主要得益于它的push-based pipeline向量化执行引擎。本文介绍它的pipeline怎么生成
1、物理执行计划长什么样?有哪些算子?
physical_plan_generator.cpp中CreatePlan函数将逻辑计划节点转换成物理计划节点,即PhysicalOperator。有哪些算子类型呢?PhysicalOperatorType:
//===--------------------------------------------------------------------===//
// Physical Operator Types
//===--------------------------------------------------------------------===//
enum class PhysicalOperatorType : uint8_t {
INVALID,
ORDER_BY,
LIMIT,
STREAMING_LIMIT,
LIMIT_PERCENT,
TOP_N,
WINDOW,
UNNEST,
UNGROUPED_AGGREGATE,
HASH_GROUP_BY,
PERFECT_HASH_GROUP_BY,
FILTER,
PROJECTION,
COPY_TO_FILE,
BATCH_COPY_TO_FILE,
FIXED_BATCH_COPY_TO_FILE,
RESERVOIR_SAMPLE,
STREAMING_SAMPLE,
STREAMING_WINDOW,
PIVOT,
// -----------------------------
// Scans
// -----------------------------
TABLE_SCAN,
DUMMY_SCAN,
COLUMN_DATA_SCAN,
CHUNK_SCAN,
RECURSIVE_CTE_SCAN,
CTE_SCAN,
DELIM_SCAN,
EXPRESSION_SCAN,
POSITIONAL_SCAN,
// -----------------------------
// Joins
// -----------------------------
BLOCKWISE_NL_JOIN,
NESTED_LOOP_JOIN,
HASH_JOIN,
CROSS_PRODUCT,
PIECEWISE_MERGE_JOIN,
IE_JOIN,
DELIM_JOIN,
INDEX_JOIN,
POSITIONAL_JOIN,
ASOF_JOIN,
// -----------------------------
// SetOps
// -----------------------------
UNION,
RECURSIVE_CTE,
CTE,
// -----------------------------
// Updates
// -----------------------------
INSERT,
BATCH_INSERT,
DELETE_OPERATOR,
UPDATE,
// -----------------------------
// Schema
// -----------------------------
CREATE_TABLE,
CREATE_TABLE_AS,
BATCH_CREATE_TABLE_AS,
CREATE_INDEX,
ALTER,
CREATE_SEQUENCE,
CREATE_VIEW,
CREATE_SCHEMA,
CREATE_MACRO,
DROP,
PRAGMA,
TRANSACTION,
CREATE_TYPE,
ATTACH,
DETACH,
// -----------------------------
// Helpers
// -----------------------------
EXPLAIN,
EXPLAIN_ANALYZE,
EMPTY_RESULT,
EXECUTE,
PREPARE,
VACUUM,
EXPORT,
SET,
LOAD,
INOUT_FUNCTION,
RESULT_COLLECTOR,
RESET,
EXTENSION
};让我们看一个简单inner join的例子:物理执行计划最上头是投影算子PROJECTION,然后其左子树是HASH_JOIN算子,HASH_JOIN两个子算子分别为两个顺序扫描SEQ_SCAN:
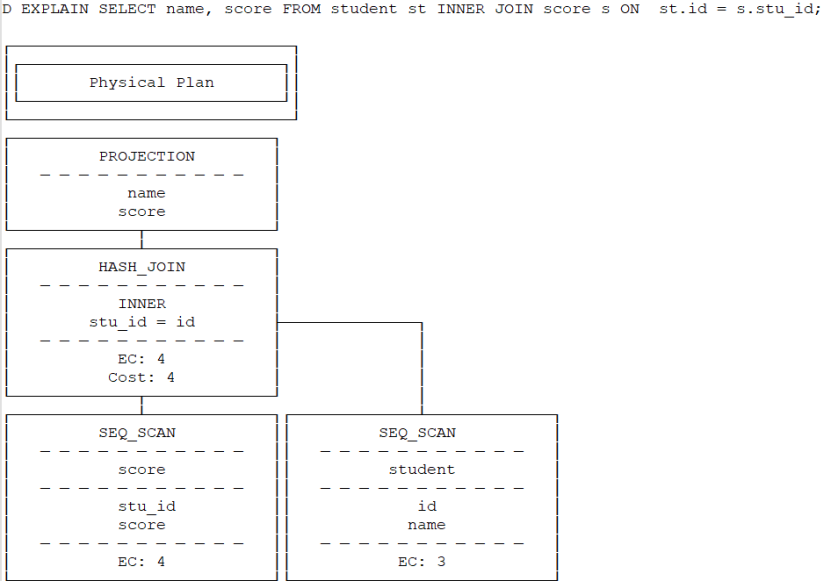
基于物理执行计划构建出pipeline,真正执行的是pipeline。
2、物理执行计划如何构建pipeline?
2.1什么是MetaPipeline
MetaPipeline 表示一组都具有相同Sink的Pipeline。Source为输入,Sink为输出,Other Node就是其他节点,将一个物理执行计划树转换成多个pipeline。一个pipeline包含一个source和一个sink以及若干个operators。
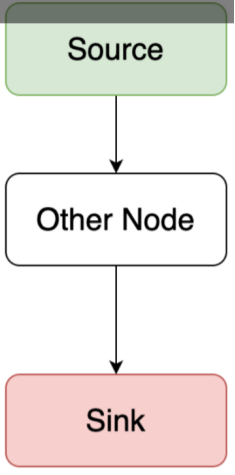
pipeline还存在一定的依赖关系,hashjoin节点必须依赖build端的pipeline产生的数据才行,所以就需要MetaPipeline构建多个pipeline依赖关系,最后执行时仅关注pipeline就可以。
以1中的例子介绍pipeline的构建过程:
2.2 Pipeline的构建
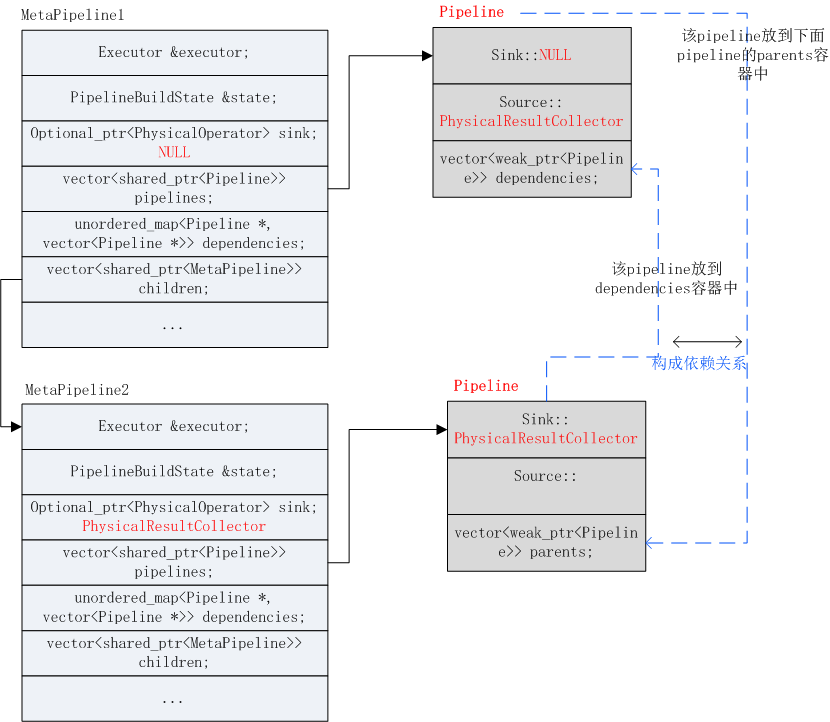
1)最开始由Executor::InitializeInteral函数创建一个MetaPipeline。该MetaPipeline的sink为NULL,vector<>pipelines容器创建一个pipeline,该pipeline的sink为NULL。
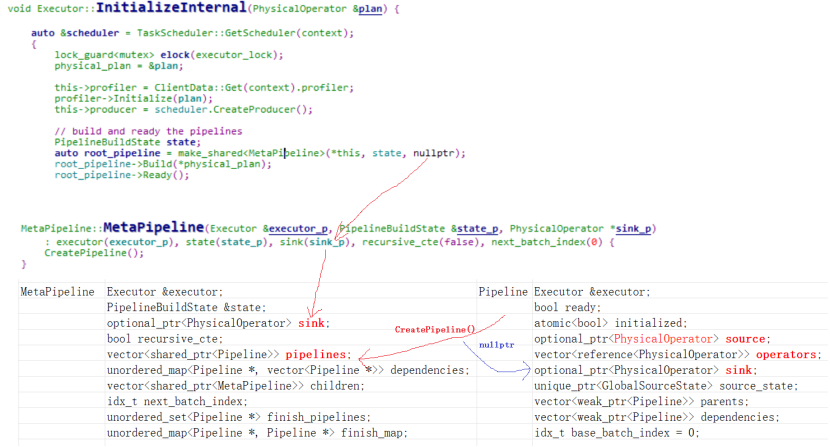
2)接着调用root_pipeline->Build(*physical_plan)使用上面的MetaPipeline继续构建pipeline
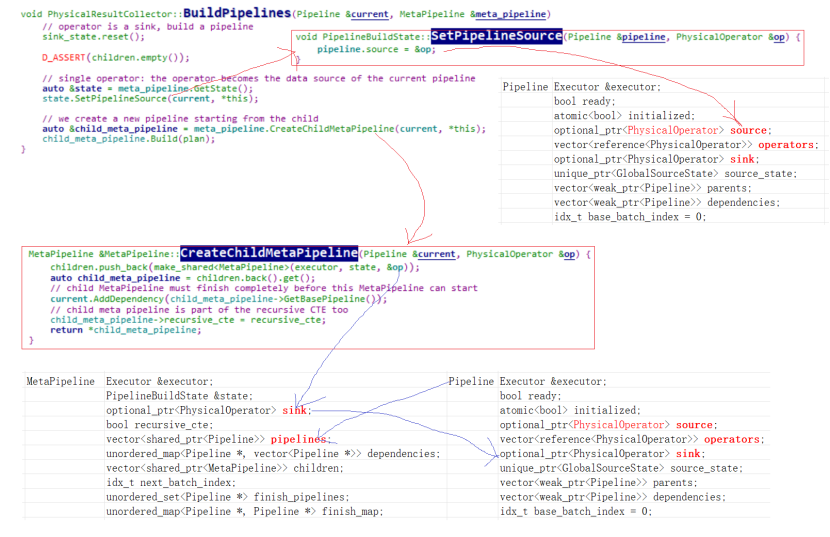
3)physical_plan为RESULT_COLLECTOR,Build会调用对应operator的Buildipelines,即调用PhysicalResultCollector::BuildPipelines,PhysicalResultCollector为PhysicalOperator的子类。
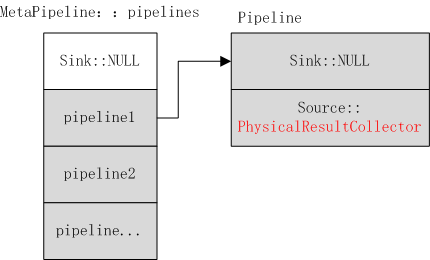
将当前operator即PhysicalResultCollector作为当前pipeline的source,如上图所示。
4)接着在调用CreateChildMetaPipeline创建一个child_meta_pipeline,sink节点为当前节点,即PhysicalResultCollector:并构建出和上一个pipeline的父子关系
代码:
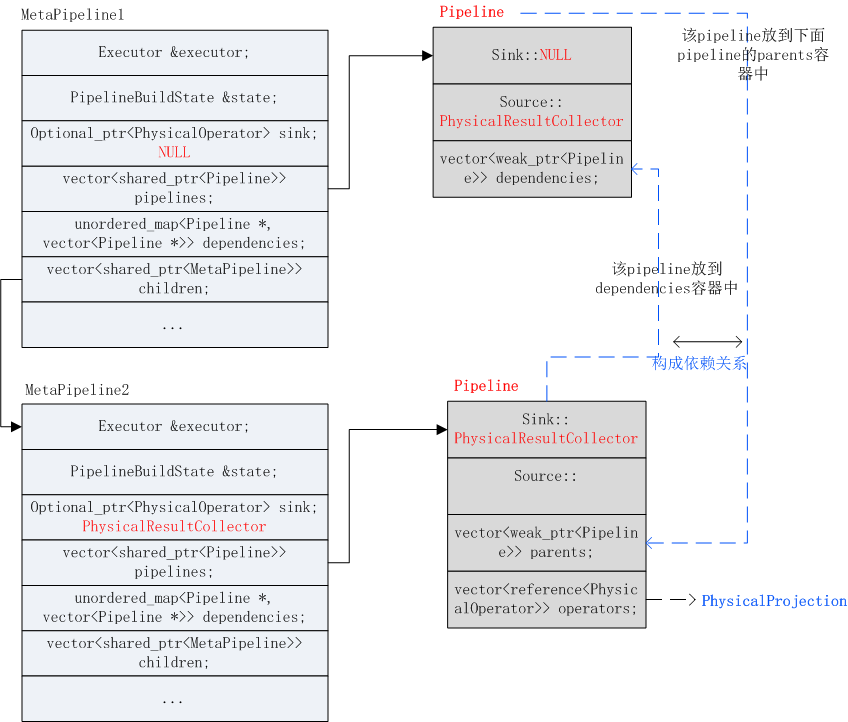
5)紧接着使用child_meta_pipeline继续构建pipeline。下一个算子是PROJECTION:PhysicalProjection,它没有重写基类的BuildPipelines,那么就调用PhysicalOperator的BuildPipelines:
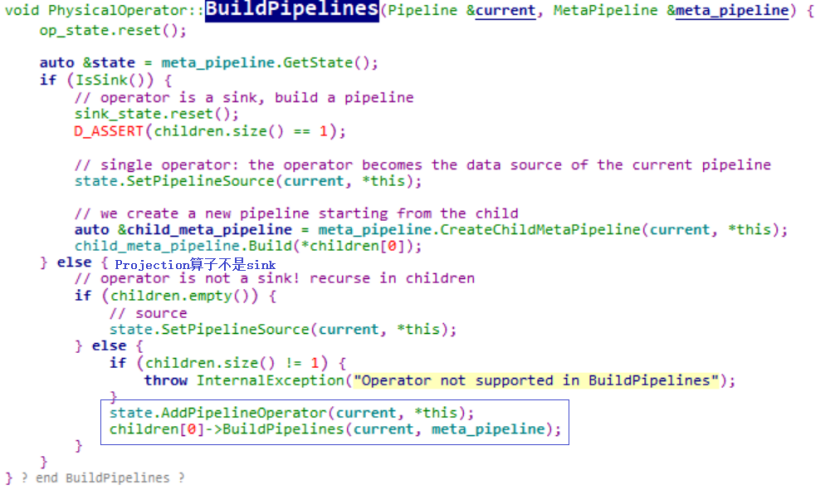
projection不是sink,并且它的子节点不为空,所以在当前pipeline添加一个算子即PhysicalProjection:也就是将PhysicalProjection放到当前pipeline的operators容器中
6)children[0]->BuildPipelines构建当前算子PhysicalProjection子节点的pipeline。此时到了HashJoin,即需要调用PhysicalHashJoin的PhysicalJoin::BuildJoinPipelines继续构建pipeline
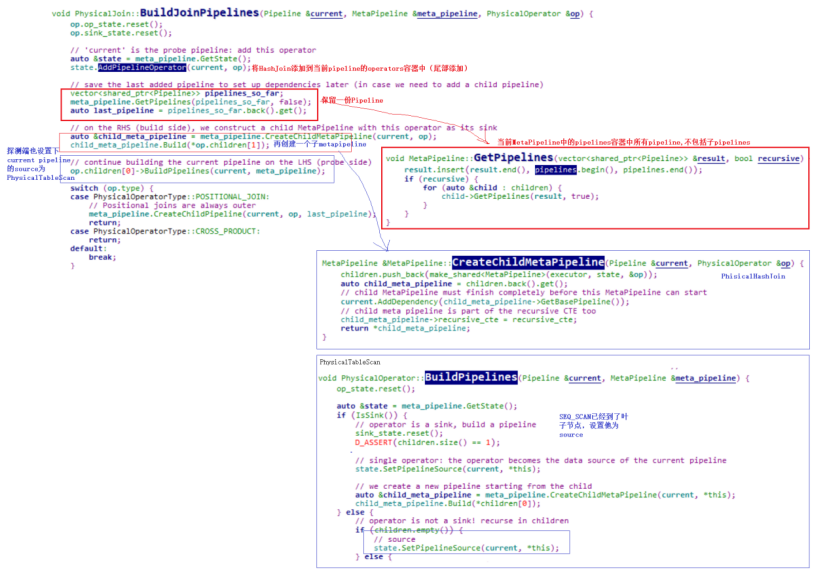
首先将HashJoin添加到当前pipeline的operator容器中(因为作为探测端的pipeline);然后保留一份当前MetaPipeline中的所有pipeline到pipelines_so_for后面使用;接着构建build端的MetaPipeline:CreateChildMetaPipeline函数完成:主要是构建一个pipeline,sink为当前PhysicalHashJoin,source为PhysicalTableScan:此时构建的pipeline如下图所示:
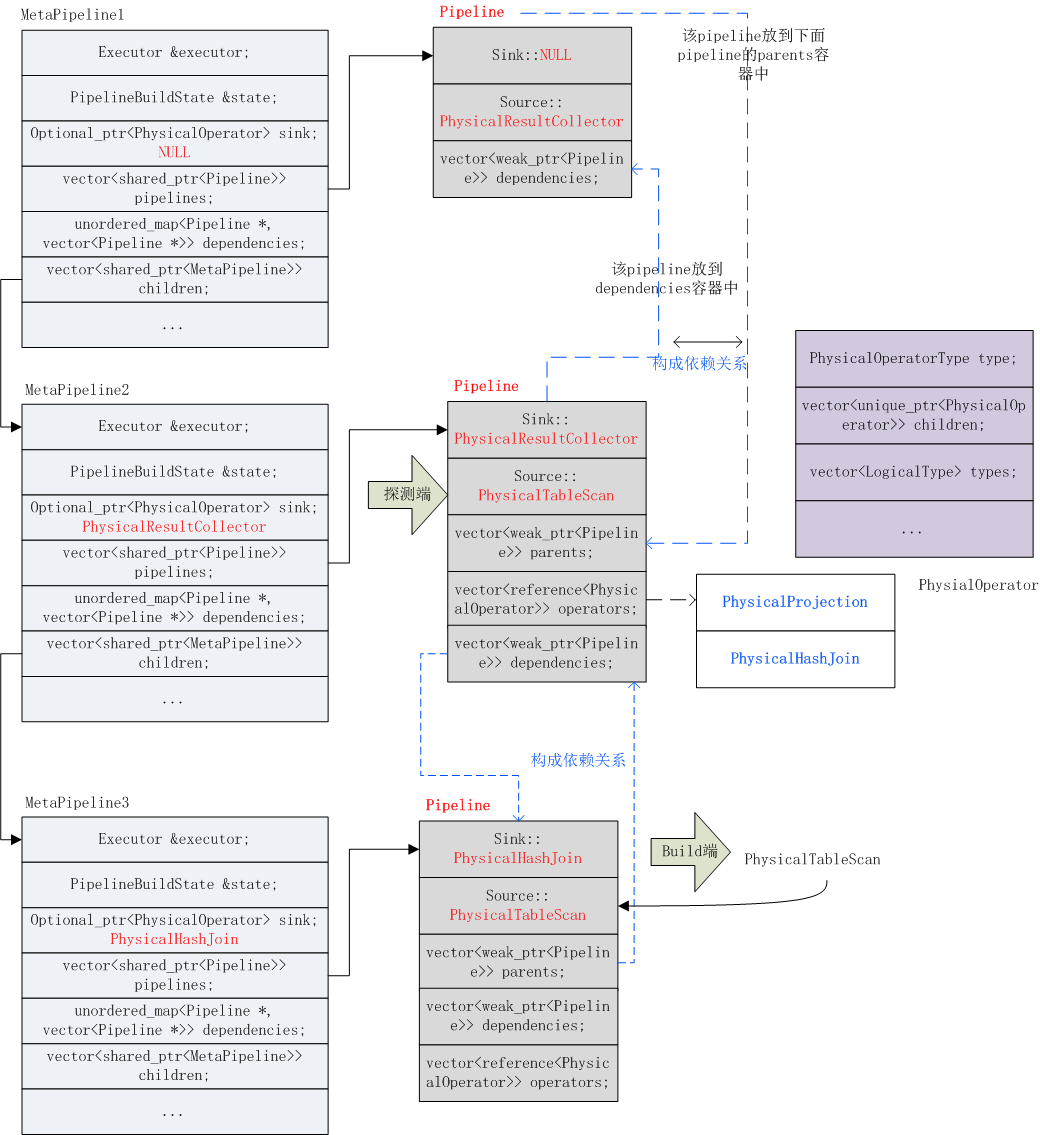
7)然后调用op.children[0].BuildPipelines继续build探测端的pipeline,实际上将左表的PhysicalTableScan设置到探测端pipeline的Source中。如上图所示。
8)外连接需要使用步骤6)保存的pipeline,构建一个childpipeline:
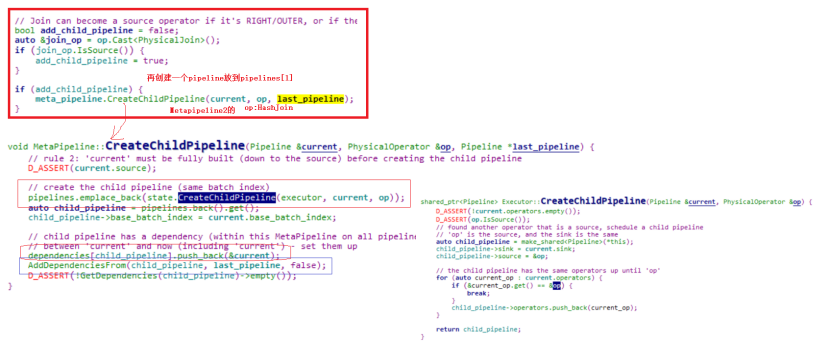
即使用Metapipeline2的pipeline再构建一个childpipeline,需要将PhysicalProjection操作符算子也加进去,此时结构如下图所示:
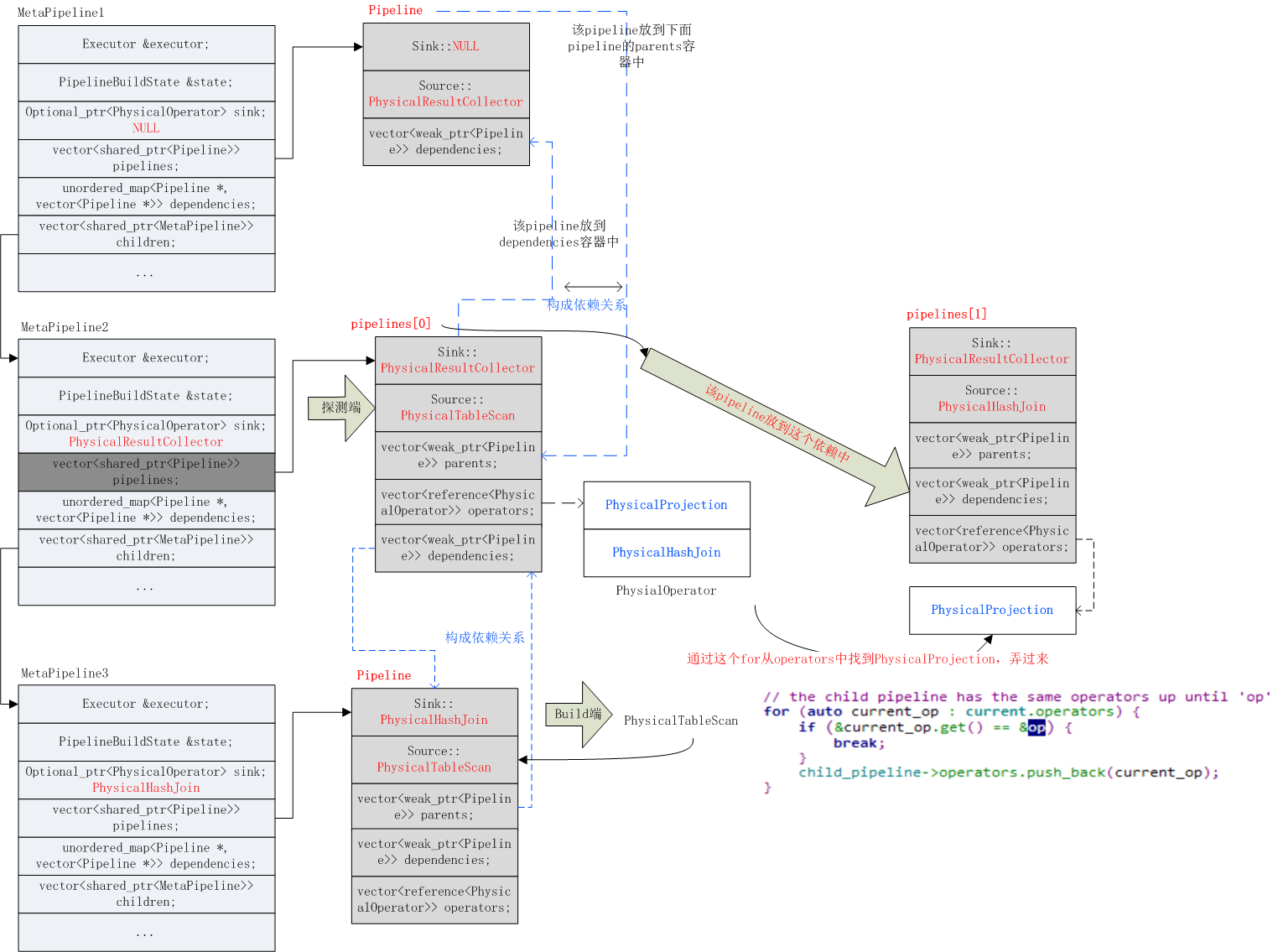
9)接着会添加依赖,都是在CreateChildPipeline函数中完成。对于当前的metapipeline,即MetaPipeline2它有两个pipeline:pipeline[0]:probe端;pipeline[1]:child pipeline。首先将当前pipeline(pipeline[0])放到dependencies[child_pipeline]中;然后调用AddDependenciesFrom(child_pipeline, last_pipeline, false)继续添加依赖关系,从last_pipeline开始继续向dependencies中添加。
例如,当前metapipeline中有n个pipeline,下面pipeline[1]为起使pipeline,pipeline[m]为dependant,那么会将中间所有的pipeline都添加到dependant依赖数组里面。
pipelines[0]
....
pipelines[s] ---> start
.....
pipelines[m] ---> dependant
pipelines[n-1]结构:unordered_map<Pipeline *, vector<Pipeline *>> dependencies;完成依赖后:
pipelines[m] : [pipelines[s]......pipelines[m-1]]
由于这里的s=0;m=1所以依赖关系为:pipelines[1] : [ pipelines[0] ],其中pipeline[1]就是child_pipeline。如此:child_pipeline : [probe pipeline],表示probe pipeline依赖child_pipeline.
10)返回到1),此时进入root_pipeline->Ready()

以8)的metapipeline2中的pipeline[0]为例,反转前:
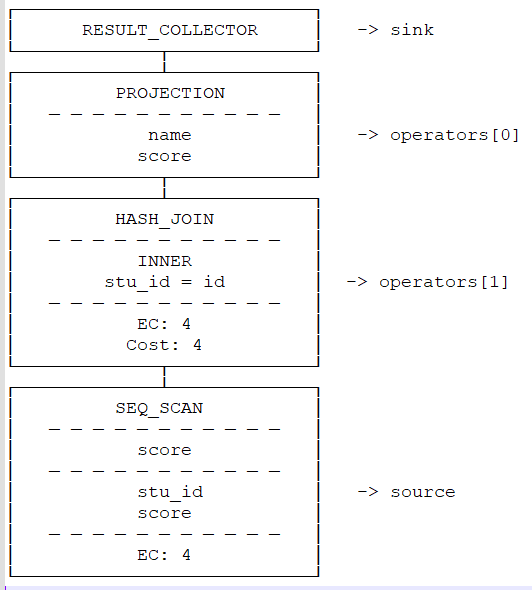 反转后:
反转后: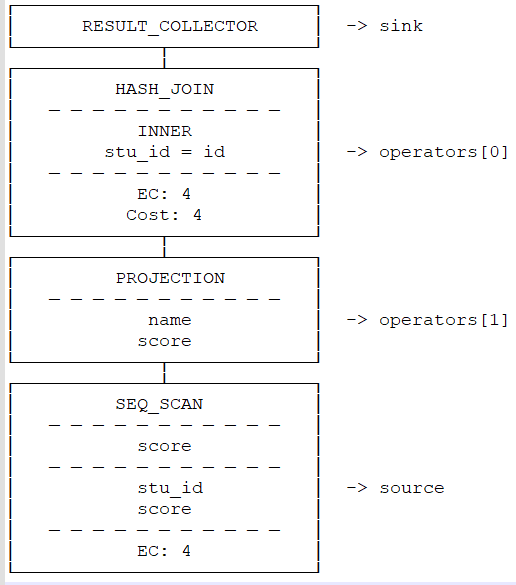
11)总结:8)中为所有Metapipeline和pipeline:
第一个Metapipeline:
{pipelines[1], children[1]}
第二个Metapipeline:Children Metapipeline:
{pipelines[2], children[1]}
第三个Metapipeline:children metapipeline:
{pipelines[1], children[0]}
注意:表示的是数组大小
12)最后再次回到1)Executor::InitializeInternal函数,会从root_pipeline(他是metapipeline),递归调用所有的metapipeline的pipelines数组,将pipeline汇总到root_pipelines中:
root_pipeline->GetPipelines(root_pipelines, false);
//vector<shared_ptr<Pipeline>> root_pipelines;
这就是pipeline的一个生成过程,下期介绍这些pipeline是如何调度的。
