




目录
Memtable在LevelDB中的作用及其数据结构
SkipList的原理浅析
实现一个SkipListMap
LevelDB中SkipListMap实现
一:Memtable在LevelDB中的作用及其数据结构
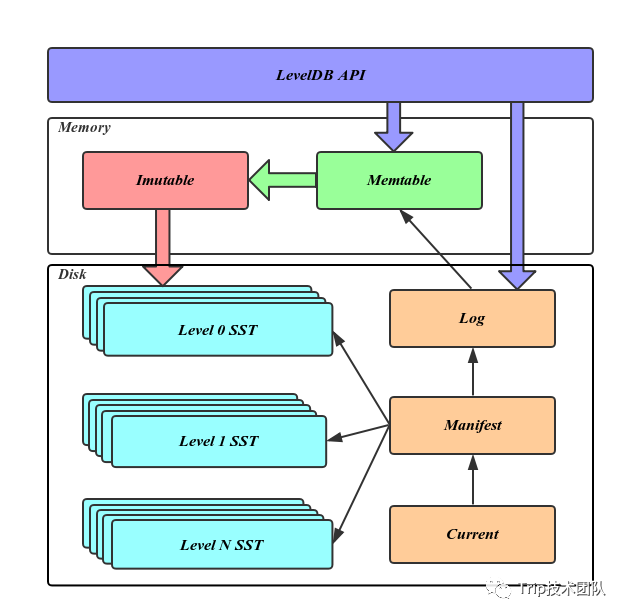
结合LevelDB的架构图,我们可以看出LevelDB的写入流程为:先写WAL,然后将数据写入到内存中的Memtable,当Memtable被写满时(默认为4M),Memtable会被变为Imutable不可变表,然后在适合的适合触发Compaction将Imutable表构造成一个SSTable写入到磁盘中完成持久化。所以,Memtable的作用正如其名,是LevelDB在内存中的表,它的存在是为了方便快速查询写入WAL日志中、但还没有被写入到SSTable中的数据;另外,内存表还能加快MinorCompaction的速度。
上面说到,Memtable是为了方便查询,方便写入到SSTable,所以Memtable的数据结构需要满足以下两个条件:一是查询复杂度低、二是有序。满足这两个条件的数据结构最常见的就是查找树,比如:红黑树、BTree等,但是LevelDB的作者没有选择树,二是选择另一种数据结构:SkipList跳表。
二:SkipList的原理
SkipList是由美国计算机科学家William Pugh在1989发表的论文Skip Lists: A Probabilistic Alternative to Balanced Trees中提出来的。作者在摘要部分就开门见山的说明了SkipList的是什么、可以做什么以及如何实现的:
Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
翻译过来就是:SkipList是一种可以替代平衡树的数据结构。它使用概率平衡而不是严格保证平衡,所以它的插入和删除操作相比于平衡树要简单快速。
首先给出SkipList的结构图:

1:SkipList的设计思想和理想模型
SkipList最基础的数据结构是一个有序链表,但是有序链表查找的时间复杂度是常量O(n),如果每个节点都有一个指针指向当前节点的第二个节点,假设我们称之为一级索引指针,那么在查询时先查询一级索引指针,最多需要查询n/2 + 1个节点。同样的,我们新增多级索引指针,查询复杂度就会不断减少,而我们付出的是额外的指针空间。试想一下,每一级索引都跨一个节点,那么一共n个节点的话,索引一共可以建log2(n)级,最高一层只会有一个头节点。在查询时从最高层开始查询,垂直方向上最多需要走log2(n)个节点,水平方向最多需要走1 * log2(n)个节点,所以最多只需要查询2 * log2(n)次就可以查询到。这就是从链表演变到跳表理想模型的思维推演方式。
2: 查询时间复杂度的简单分析
进一步,如果每跨K个节点新建索引节点,即索引层数向上爬高一的概率为1/k,对于查询的时间复杂度可以做如下分析:垂直方向上走过的最大的节点数为索引的高度logk(n),水平方向上每一层索引上最多走k个节点,一共logk(n)级,最多走k * logk(n)个节点,所以查询的路径最多需要查询的节点数为:
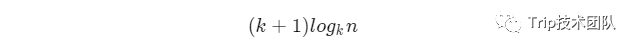
即查询的复杂度为:
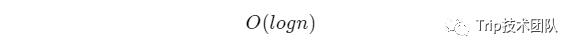
3: 空间复杂度的简单分析
跳表时间复杂度很优秀的前提是额外建立了多级的索引,需要很多的节点,那么跳表的空间复杂度会不会很高?可以做如下分析,n个节点,每跨k个节点新建索引节点。第一级索引需要n/k个节点,第二级索引需要n/k^2(K的平方),依次类推,一共需要的节点数为:
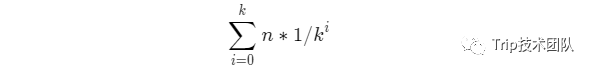
很显然这是一个等比数列,可以通过求和公式求得:
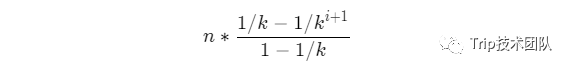
如果n很大,层数很大,那么$1/k^{i+1}$趋近于0,公式可变为:
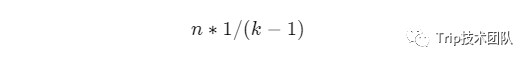
所以跳表的空间复杂度为:
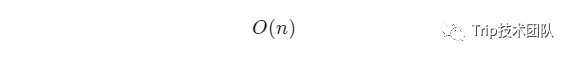
三:实现一个SkipListMap
使用跳表实现一个Map,展示跳表的基础实现。
1.定义Node和属性
首先定义跳表中的Node:
/*** 节点** @param <K>* @param <V>*/private static final class Node<K, V> implements Map.Entry<K, V> {final K key;V value;/*** 当前节点的层数*/int level;/*** 多层的前向指针,其实就是多级索引,存放每一层的下一个节点* 最多和MAX_LEVEL一样*/Node<K, V>[] forwards;@SuppressWarnings("unchecked")Node(K key, V value, int level) {super();this.key = key;this.value = value;this.level = level;this.forwards = new Node[MAX_LEVEL];}//其它方法略}
由于实现的SkipListMap实现了JDK中的Map接口所以节点也实现了Map.Entry。下面给出SkipListMap的声明、属性、构造方法:
/*** 跳表** @param <K> K值,用于排序* @param <V> V值,存放的值也可为null* @author chengzheng*/public final class SkipListMap<K extends Comparable<K>, V> implements Map<K, V>, Iterable<Map.Entry<K, V>> {/*** 最大层限制为16*/private static final int MAX_LEVEL = 16;/*** 增长的概率为1/4,即当前层中平均插入4个节点就向上爬一层*/private static final int BRANCH = 4;/*** 头节点*/private final Node<K, V> dummyHead;/*** 当前跳表中最高的节点*/private int currentMaxLevel;/*** 元素个数*/private int size;public SkipListMap() {this.currentMaxLevel = 1;this.size = 0;this.dummyHead = new Node<>(null, null, 1);}//其它略}
2.展现跳表核心思想的方法:randomLevel()
每次插入新节点时,需要确定新节点的层数level,跳表使用一种概率的方式来确定新节点的层数,这是跳表相比于其它确定算法的特点和优势。方法如下:
/*** 获得新节点的level* @return 新节点的level*/private int randomLevel() {//初始高度1int newLevel = 1;//通过随机数判断是否要爬高,newLevel为2有25%的概率,newLevel为3的概率为25% * 25%while (newLevel < MAX_LEVEL && ThreadLocalRandom.current().nextInt() % BRANCH == 0) {newLevel++;}//更新当前最大levelif (newLevel > this.currentMaxLevel) {this.currentMaxLevel = newLevel;}return newLevel;}
3.查询方法
查询的主要思路是:从最高层的索引开始遍历,遍历方向是向左或者向下;如果下一个节点小于查询节点就向左,否则就向下,直到最左下方的节点。代码如下:
@Overridepublic V get(Object key) {Objects.requireNonNull(key);//当前节点Node<K, V> c = dummyHead;//从当前跳表中最高层开始遍历,层越高,节点越稀疏for (int i = currentMaxLevel - 1; i >= 0; i--) {while (c.forwards[i] != null) {//当前节点的下一个节点和查询值比较@SuppressWarnings("unchecked")final int cmp = c.forwards[i].key.compareTo((K) key);//当前节点的下一个节点小于查询值,当前节点向右移动if (cmp < 0) {c = c.forwards[i];} else if (cmp == 0) {//查询到了return c.forwards[i].value;} else {//当前节点的下一个节点大于查询值,当前节点向下移动break;}}}//查询不到返回nullreturn null;}
4.插入方法
插入方法的主要思路是,一是:找到K值相等的节点,替换其中的oldValue;二是:生成新节点的高度,找到新节点的上一个节点,这里的上一个节点是新节点每一层的上一个节点,这样才能把每一层的索引链接(其实就是每一层的链表)起来。代码明细如下:
@Overridepublic V put(K key, V value) {Objects.requireNonNull(key);//新节点的高度final int newNodeLevel = randomLevel();Node<K, V> c = dummyHead;//新节点的后向结点(这里的后向是指小于新节点的方向),大小是新节点的高度,因为新节点的所有层都必须前后连接起来@SuppressWarnings("unchecked")Node<K, V>[] backwards = new Node[newNodeLevel];//从最高层开始向左下方遍历for (int i = currentMaxLevel - 1; i >= 0; i--) {while (c.forwards[i] != null) {final int cmp = c.forwards[i].key.compareTo(key);//当前节点的下一个节点小于要插入的节点K,更新当前节点,向左移动if (cmp < 0) {c = c.forwards[i];} else if (cmp == 0) {//等于的话,直接更新value即可返回final V oldValue = c.forwards[i].value;c.forwards[i].value = value;return oldValue;} else {break;}}//走到这里所以当前层的当前节点的下一个节点大于插入节点K了,所以把当节点为插入节点的上一个节点,保存之//但是当前层需要小于等新节点的层数才能保存,不然会越界,注意上面声明的大小if (i <= newNodeLevel - 1) {backwards[i] = c;}}//不存在,新建Nodefinal Node<K, V> newNode = new Node<>(key, value, newNodeLevel);//依次连接每一层的索引(其实就是每一层的链表)for (int i = 0; i < newNodeLevel; i++) {newNode.forwards[i] = backwards[i].forwards[i];backwards[i].forwards[i] = newNode;}size++;return null;}
5.跳表的有序遍历或者范围查询
相比于平衡树,跳表的另一个优势就是它的有序遍历和范围查询,这也是它在很多场景大放异彩的原因。由于跳表的本质就是一个多层的链表,所以只要查询到第一个节点,后面的遍历就很方便,这里主要给出跳表的一个迭代器,它可以从头到尾的遍历跳表,至于给定起始的动态范围遍历,在LevelDB中跳表实现中给出。
获得迭代器:
@Overridepublic Iterator<Map.Entry<K, V>> iterator() {return new SkipListMapIterator<>(0, this.dummyHead);}
迭代器实现:
/*** 迭代器** @param <K>* @param <V>*/private static final class SkipListMapIterator<K, V> implements Iterator<Map.Entry<K, V>> {/*** 遍历的层级,一般全遍历就是0*/private final int level;private Node<K, V> c;public SkipListMapIterator(int level, Node<K, V> dummyHead) {this.level = level;this.c = dummyHead;}@Overridepublic boolean hasNext() {//下一个节点不为null即可继续return this.c.forwards[level] != null;}@Overridepublic Entry<K, V> next() {//指向下一个节点,更新当前节点,返回Node<K, V> next = this.c.forwards[level];this.c = next;return next;}}
上面就描述完跳表的查询、插入、迭代器了,相比于平衡树,它的实现复杂度和代码量都远远小于平衡树,但是它的时间复杂度可是和平衡树一样。它简单的实现和优异的性能被很多优秀的组件使用,例如:
LevelDB的Memtable
Redis的ZSet
Lucene索引文件的生成和合并(场景和LevelDB类似)
四:LevelDB中跳表的实现简析
LevelDB中跳表的实现和我们上面实现的几乎没有什么区别,代码地址为skiplist.h,LevelDB中跳表的实现都在一个头文件里,也可以看出它的实现到底有多简单。
这里着重看一下它的迭代器实现,实际场景中会高频使用到。比如:定位到指定位置,访问前向节点,定位到第一个节点和最后一个节点等。JDK中的SortedMap、NavigableMap也有类似方法。
// Iteration over the contents of a skip listclass Iterator {public:// Initialize an iterator over the specified list.// The returned iterator is not valid.explicit Iterator(const SkipList* list);// Returns true iff the iterator is positioned at a valid node.bool Valid() const;// Returns the key at the current position.// REQUIRES: Valid()const Key& key() const;// Advances to the next position.// REQUIRES: Valid()void Next();// Advances to the previous position.// REQUIRES: Valid()void Prev();// Advance to the first entry with a key >= targetvoid Seek(const Key& target);// Position at the first entry in list.// Final state of iterator is Valid() iff list is not empty.void SeekToFirst();// Position at the last entry in list.// Final state of iterator is Valid() iff list is not empty.void SeekToLast();private:const SkipList* list_;Node* node_;// Intentionally copyable};
可以看出Seek()方法即是我们的代码中没有实现的部分,这里着重看一下:
template <typename Key, class Comparator>inline void SkipList<Key, Comparator>::Iterator::Seek(const Key& target) {node_ = list_->FindGreaterOrEqual(target, nullptr);}template <typename Key, class Comparator>typename SkipList<Key, Comparator>::Node*SkipList<Key, Comparator>::FindGreaterOrEqual(const Key& key,Node** prev) const {Node* x = head_;int level = GetMaxHeight() - 1;while (true) {Node* next = x->Next(level);if (KeyIsAfterNode(key, next)) {// Keep searching in this listx = next;} else {if (prev != nullptr) prev[level] = x;if (level == 0) {return next;} else {// Switch to next listlevel--;}}}}
可以看出随机定位的Seek方法的思想就是找到比给定值大或者相等的节点,把这个节点指向迭代器中的当前节点,这样迭代器就可以以此向后访问了。
SkipListMap实现demo
Demo地址
https://gitee.com/MuYangQuan/study-note/blob/master/demo/src/main/java/com/chengzheng/study/note/SkipListMap.java
参考文档
https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf
https://blog.csdn.net/qq_34412579/article/details/101731935
https://www.amazingkoala.com.cn/Lucene/Index/2020/0103/123.html
作者介绍
Daniel ,携程资深后端开发工程师,关注Golang、Rust等新兴语言、KV存储引擎、无锁数据结构等领域。
团队招聘信息
我们是Trip.com国际事业部研发团队,主要负责集团国际化业务在全球的云原生化开发和部署,直面业界最前沿的技术挑战,致力于引领集团技术创新,赋能国际业务增长,带来更极致的用户体验。
团队怀有前瞻的技术视野,积极拥抱开源建设,紧跟业界技术趋势,在这里有浓厚的技术氛围,你可以和团队成员一同参与开源建设,深入探索和交流技术原理,也有技术实施的广阔场景。
我们长期招聘有志于技术成长、对技术怀有热忱的同学,如果你热爱技术,无惧技术挑战,渴望更大的技术进步,Trip.com国际事业部期待与您的相遇。
目前我们后端/前端/测试开发/安卓,岗位都在火热招聘。简历投递邮箱:tech@trip.com,邮件标题:【姓名】-【携程国际业务研发部】- 【投递职位】
